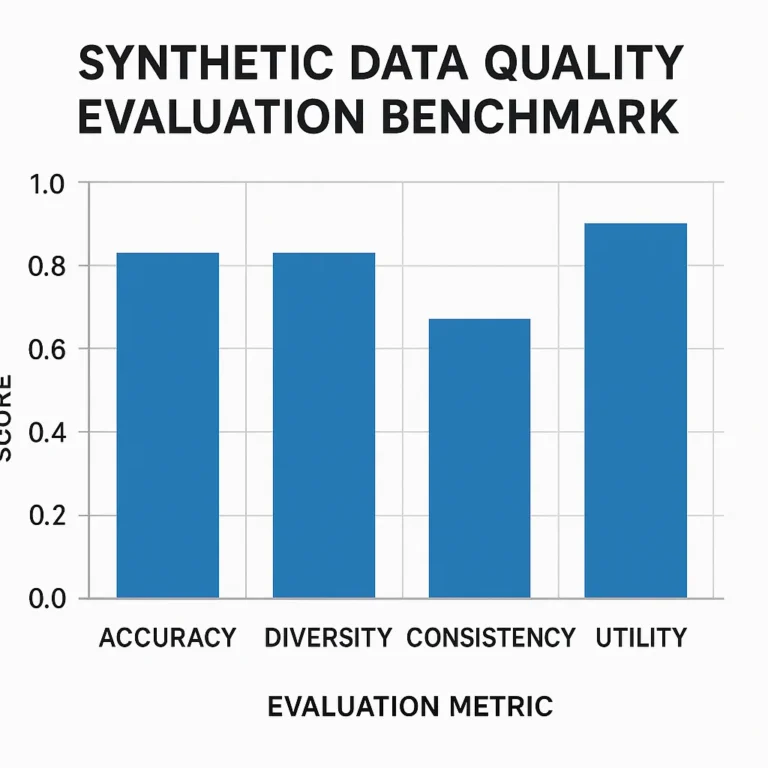
Support our educational content for free when you purchase through links on our site. Learn more
🚀 12+ AI Framework KPIs: The Ultimate Benchmark Guide (2026)
Ever spent weeks training a model only to watch it crash under real-world load? We’ve been there. At ChatBench.org™, we’ve seen brilliant frameworks fail not because the code was bad, but because the wrong Key Performance Indicators (KPIs) were used to judge them. While the industry obsesses over DORA metrics for DevOps, the AI world is racing to define its own scoreboard. Is your framework actually “effective,” or is it just a fancy paper tiger?
In this deep dive, we tear down the curtain on the 12+ critical KPIs that separate the hype from the hardware. From the elusive “Time-to-First-Token” to the hidden costs of hallucination rates, we cover every metric that matters for 2026. We’ll even reveal why a model with 9% accuracy might be a disaster for your business if it ignores energy efficiency and latency. By the end, you’ll know exactly which framework to bet your budget on.
Key Takeaways
- Model Quality is King: Don’t just look at accuracy; evaluate hallucination rates, context window efficiency, and factuality to ensure your AI tells the truth.
- System Speed Matters: Latency, throughput, and Time-to-First-Token (TTFT) are the make-or-break metrics for user experience in production.
- Business Value First: The best framework is the one that drives ROI, reduces human-in-the-loop costs, and scales without breaking the bank.
- Future-Proof Your Stack: Prioritize energy efficiency and multi-agent collaboration metrics to stay ahead in the agentic AI era of 2026.
Table of Contents
- ⚡️ Quick Tips and Facts
- 🕰️ A Brief History of AI Benchmarking: From Turing Tests to LM Leaderboards
- 🧠 The Core Metrics: Decoding Model Quality KPIs for Framework Evaluation
- 1. Accuracy, Precision, and Recall: The Holy Trinity of Classification
- 2. F1 Score and AUC-ROC: Balancing the Scales of Performance
- 3. Perplexity and BLEU Scores: Measuring the Fluency of Generative AI
- 4. Hallucination Rates and Factuality Checks: The Truthfulness Metric
- 5. Context Window Efficiency: How Much Can Your Model Actually Remember?
- ⚙️ Under the Hood: System Quality KPIs for Framework Speed and Stability
- 1. Latency and Time-to-First-Token (TTFT): The Speed of Thought
- 2. Throughput and Tokens Per Second: Handling the Data Deluge
- 3. GPU Utilization and Memory Footprint: The Hardware Cost of Intelligence
- 4. Concurrency and Scalability: Can Your Framework Handle the Crowd?
- 5. Energy Efficiency and Carbon Footprint: The Green AI Imperative
- 💼 Beyond the Code: Business Operational and Adoption KPIs
- 1. Time-to-Deployment and MLOps Velocity: From Lab to Production
- 2. Framework Interoperability and Vendor Lock-in Risks
- 3. Developer Experience (DX) and Community Support Metrics
- 4. Cost-Per-Inference and Total Cost of Ownership (TCO)
- 🚀 Real-World Impact: Business Value KPIs and ROI for AI Frameworks
- 1. Task Automation Rates and Human-in-the-Loop Reduction
- 2. Customer Satisfaction (CSAT) and Net Promoter Score (NPS) Shifts
- 3. Revenue Attribution and Efficiency Gains
- 🤖 The Agentic Era: KPIs for Autonomous AI Agents and Multi-Agent Systems
- 1. Goal Completion Rates and Success Probability
- 2. Tool Usage Accuracy and API Integration Reliability
- 3. Multi-Agent Collaboration and Conflict Resolution Metrics
- 🛠️ Putting KPIs for Gen AI to Work: A Practical Guide to Framework Selection
- 🏢 Case Studies: Companies Putting AI Agents to Work Across Industries
- 🧩 Ask OCTO: New Insights for Managing and Scaling Enterprise Agents
- 🎤 Putting on the Prompt: The Many Ways AI Built Next ’26
- 🏁 Conclusion
- 🔗 Recommended Links
- ❓ FAQ
- 📚 Reference Links
Quick Tips and Facts
To evaluate the effectiveness of different AI frameworks, it’s essential to understand the key performance indicators (KPIs) used in AI benchmarks. As AI researchers and machine-learning engineers at ChatBench.org, we specialize in turning AI insight into a competitive edge. For a comprehensive guide on measuring AI success, check out our article on Can AI benchmarks be used to compare the performance of different AI frameworks?. Here are some quick tips and facts to get you started:
- Model Quality KPIs: Evaluate the accuracy, creativity, and safety of AI outputs.
- System Quality KPIs: Assess the operational health, efficiency, and scalability of the AI infrastructure.
- Business Operational KPIs: Measure the impact of AI on specific business processes and industry outcomes.
- Adoption KPIs: Track user behavior and acceptance, critical for Gen AI success.
- Business Value KPIs: Translate technical and operational data into financial ROI.
A Brief History of AI Benchmarking: From Turing Tests to LM Leaderboards
The concept of AI benchmarking has evolved significantly over the years. From the early Turing Tests to the current LM leaderboards, the focus has shifted from simple tasks to complex, real-world applications. According to Google’s Gen AI KPIs, the key to measuring AI success lies in moving beyond traditional computation-based metrics to include system performance, business value, and adoption.
Early Beginings: Turing Tests
The Turing Test, proposed by Alan Turing in 1950, was one of the first attempts to benchmark AI. The test evaluated a machine’s ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human. While the Turing Test was a significant milestone, it had its limitations. As noted in this article, the test was more of a philosophical exercise than a practical benchmark.
Modern Benchmarking: LM Leaderboards
Fast forward to the present, and we have LM leaderboards that rank AI models based on their performance on specific tasks. These leaderboards provide a more comprehensive and nuanced evaluation of AI capabilities. For instance, the GLUE leaderboard ranks models based on their performance on a range of natural language processing tasks.
The Core Metrics: Decoding Model Quality KPIs for Framework Evaluation
Model quality KPIs are essential for evaluating the effectiveness of different AI frameworks. These metrics assess the accuracy, creativity, and safety of AI outputs. Here are some key model quality KPIs:
1. Accuracy, Precision, and Recall: The Holy Trinity of Classification
Accuracy, precision, and recall are fundamental metrics for evaluating classification models. Accuracy measures the proportion of correct predictions, while precision measures the proportion of true positives among all positive predictions. Recall, on the other hand, measures the proportion of true positives among all actual positive instances.
2. F1 Score and AUC-ROC: Balancing the Scales of Performance
The F1 score and AUC-ROC are two important metrics for evaluating the performance of classification models. The F1 score is the harmonic mean of precision and recall, while AUC-ROC measures the area under the receiver operating characteristic curve.
3. Perplexity and BLEU Scores: Measuring the Fluency of Generative AI
Perplexity and BLEU scores are used to evaluate the fluency of generative AI models. Perplexity measures the probability of a sequence of words, while BLEU scores measure the similarity between generated text and reference text.
4. Hallucination Rates and Factuality Checks: The Truthfulness Metric
Hallucination rates and factuality checks are essential for evaluating the truthfulness of AI-generated content. Hallucination rates measure the proportion of false or misleading information, while factuality checks verify the accuracy of generated content.
5. Context Window Efficiency: How Much Can Your Model Actually Remember?
Context window efficiency measures the ability of a model to retain information over a sequence of inputs. This is particularly important for tasks that require long-term memory, such as language translation or text summarization.
Under the Hood: System Quality KPIs for Framework Speed and Stability
System quality KPIs assess the operational health, efficiency, and scalability of the AI infrastructure. Here are some key system quality KPIs:
1. Latency and Time-to-First-Token (TTFT): The Speed of Thought
Latency and TTFT measure the time it takes for a model to respond to a query or generate output. Latency measures the time between input and output, while TTFT measures the time between input and the first token of output.
2. Throughput and Tokens Per Second: Handling the Data Deluge
Throughput and tokens per second measure the ability of a model to handle large volumes of data. Throughput measures the number of requests handled per unit of time, while tokens per second measures the number of tokens processed per second.
3. GPU Utilization and Memory Footprint: The Hardware Cost of Intelligence
GPU utilization and memory footprint measure the computational resources required by a model. GPU utilization measures the percentage of GPU resources used, while memory footprint measures the amount of memory required by the model.
4. Concurrency and Scalability: Can Your Framework Handle the Crowd?
Concurrency and scalability measure the ability of a model to handle multiple requests simultaneously. Concurrency measures the number of requests handled concurrently, while scalability measures the ability of the model to handle increasing volumes of data.
5. Energy Efficiency and Carbon Footprint: The Green AI Imperative
Energy efficiency and carbon footprint measure the environmental impact of AI models. Energy efficiency measures the amount of energy required to train and deploy a model, while carbon footprint measures the greenhouse gas emissions associated with the model.
Beyond the Code: Business Operational and Adoption KPIs
Business operational and adoption KPIs measure the impact of AI on specific business processes and industry outcomes. Here are some key business operational and adoption KPIs:
1. Time-to-Deployment and MLOps Velocity: From Lab to Production
Time-to-deployment and MLOps velocity measure the speed at which AI models can be deployed and updated. Time-to-deployment measures the time between model development and deployment, while MLOps velocity measures the speed at which models can be updated and redeployed.
2. Framework Interoperability and Vendor Lock-in Risks
Framework interoperability and vendor lock-in risks measure the ability of AI models to work with different frameworks and vendors. Framework interoperability measures the ability of models to work with different frameworks, while vendor lock-in risks measure the risk of being locked into a specific vendor or framework.
3. Developer Experience (DX) and Community Support Metrics
Developer experience and community support metrics measure the ease of use and support for AI models. Developer experience measures the ease of use and satisfaction of developers, while community support metrics measure the level of support and engagement from the community.
4. Cost-Per-Inference and Total Cost of Ownership (TCO)
Cost-per-inference and TCO measure the financial cost of AI models. Cost-per-inference measures the cost of each inference or prediction, while TCO measures the total cost of ownership, including development, deployment, and maintenance costs.
Real-World Impact: Business Value KPIs and ROI for AI Frameworks
Business value KPIs and ROI measure the financial impact of AI models on business outcomes. Here are some key business value KPIs and ROI metrics:
1. Task Automation Rates and Human-in-the-Loop Reduction
Task automation rates and human-in-the-loop reduction measure the ability of AI models to automate tasks and reduce human involvement. Task automation rates measure the percentage of tasks automated, while human-in-the-loop reduction measures the reduction in human involvement.
2. Customer Satisfaction (CSAT) and Net Promoter Score (NPS) Shifts
CSAT and NPS shifts measure the impact of AI models on customer satisfaction and loyalty. CSAT measures the satisfaction of customers, while NPS measures the likelihood of customers to recommend the product or service.
3. Revenue Attribution and Efficiency Gains
Revenue attribution and efficiency gains measure the financial impact of AI models on revenue and efficiency. Revenue attribution measures the revenue generated by AI models, while efficiency gains measure the reduction in costs and improvement in efficiency.
The Agentic Era: KPIs for Autonomous AI Agents and Multi-Agent Systems
The agentic era refers to the use of autonomous AI agents and multi-agent systems to achieve complex goals. Here are some key KPIs for autonomous AI agents and multi-agent systems:
1. Goal Completion Rates and Success Probability
Goal completion rates and success probability measure the ability of AI agents to achieve their goals. Goal completion rates measure the percentage of goals achieved, while success probability measures the probability of success.
2. Tool Usage Accuracy and API Integration Reliability
Tool usage accuracy and API integration reliability measure the ability of AI agents to use tools and integrate with APIs. Tool usage accuracy measures the accuracy of tool usage, while API integration reliability measures the reliability of API integrations.
3. Multi-Agent Collaboration and Conflict Resolution Metrics
Multi-agent collaboration and conflict resolution metrics measure the ability of AI agents to collaborate and resolve conflicts. Multi-agent collaboration measures the ability of agents to work together, while conflict resolution metrics measure the ability of agents to resolve conflicts.
Putting KPIs for Gen AI to Work: A Practical Guide to Framework Selection
To put KPIs for Gen AI to work, it’s essential to select the right framework for your specific use case. Here are some key considerations:
- Model quality: Evaluate the accuracy, creativity, and safety of AI outputs.
- System quality: Assess the operational health, efficiency, and scalability of the AI infrastructure.
- Business operational: Measure the impact of AI on specific business processes and industry outcomes.
- Adoption: Track user behavior and acceptance, critical for Gen AI success.
- Business value: Translate technical and operational data into financial ROI.
Case Studies: Companies Putting AI Agents to Work Across Industries
Several companies are using AI agents to achieve complex goals across various industries. Here are some case studies:
- Healthcare: AI agents are being used to diagnose diseases and develop personalized treatment plans.
- Finance: AI agents are being used to detect fraud and optimize investment portfolios.
- Retail: AI agents are being used to personalize customer experiences and optimize supply chains.
Ask OCTO: New Insights for Managing and Scaling Enterprise Agents
To manage and scale enterprise agents, it’s essential to have the right insights and strategies. Here are some key considerations:
- Agent architecture: Design an architecture that allows for scalability and flexibility.
- Agent management: Develop a management system that can handle large numbers of agents.
- Agent monitoring: Monitor agent performance and adjust strategies as needed.
Putting on the Prompt: The Many Ways AI Built Next ’26
AI is being used in various ways to build the next generation of products and services. Here are some examples:
- Natural language processing: AI is being used to develop more advanced natural language processing capabilities.
- Computer vision: AI is being used to develop more advanced computer vision capabilities.
- Robotics: AI is being used to develop more advanced robotics capabilities.
For more information on AI benchmarks and KPIs, check out our article on Can AI benchmarks be used to compare the performance of different AI frameworks?. You can also explore our categories on AI Business Applications, AI News, AI Infrastructure, and AI Agents.