Support our educational content for free when you purchase through links on our site. Learn more
7 Common Pitfalls to Avoid When Evaluating AI Models in 2026 🚫
Evaluating AI model performance using benchmarks and metrics might seem straightforward—just run your model, check the scores, and call it a day, right? Not quite. Behind those shiny accuracy percentages and leaderboard rankings lurk traps that can mislead even seasoned AI practitioners. At ChatBench.org™, we’ve witnessed projects where models boasted stellar benchmark results but flopped spectacularly in real-world deployment. Why? Because metrics can be deceiving, datasets can be biased, and benchmarks can be gamed.
In this article, we’ll unravel the 7 most common pitfalls that trip up AI teams when evaluating models. From the sneaky dangers of overfitting to test sets, to the blind spots of ignoring data quality and ignoring operational constraints, we’ll share expert insights and actionable advice to help you avoid costly mistakes. Plus, stay tuned for real-world anecdotes that reveal how these pitfalls play out in practice—and how you can turn evaluation into your competitive edge.
Key Takeaways
- Beware of overfitting to benchmarks: Repeated testing on the same data inflates scores but harms real-world performance.
- Data quality matters more than you think: Poor or unrepresentative data leads to misleading metrics and fragile models.
- Don’t rely on a single metric: Accuracy alone can mask critical failures; use a suite of metrics aligned with business goals.
- Evaluate model robustness and fairness: Ensure your model performs well across diverse scenarios and demographics.
- Consider operational factors: Computational efficiency, scalability, and latency impact real-world viability.
- Continuous evaluation is essential: AI model performance evolves; monitoring and updating are non-negotiable.
- Transparent reporting builds trust: Clear, reproducible evaluation practices help stakeholders understand true model capabilities.
Ready to master AI model evaluation and avoid these common traps? Let’s dive in!
Table of Contents
- ⚡️ Quick Tips and Facts on AI Model Benchmarking
- 🔍 Understanding the Landscape: Evolution and Importance of AI Performance Metrics
- 🛠️ Before You Dive In: Preparing for Accurate AI Model Evaluation
- 1️⃣ Common Pitfall #1: Overfitting to Benchmarks — The Trap of Chasing Scores
- 2️⃣ Common Pitfall #2: Ignoring Data Quality and Distribution Shifts
- 3️⃣ Common Pitfall #3: Misinterpreting Metrics — Accuracy Isn’t Always King
- 4️⃣ Common Pitfall #4: Neglecting Model Robustness and Generalization
- 5️⃣ Common Pitfall #5: Overlooking Computational Efficiency and Scalability
- 🎯 How to Reliably Build and Tune AI Models for Benchmark Success
- 📊 How to Robustly Evaluate AI Models Beyond Surface Metrics
- ⚖️ How to Fairly Compare AI Models Across Different Benchmarks and Datasets
- 📝 Best Practices for Transparent and Reproducible Reporting of AI Model Performance
- 🔧 Tools and Frameworks to Help Avoid Common Benchmarking Pitfalls
- 💡 Real-World Anecdotes: Lessons Learned from AI Benchmarking Mishaps
- 🌟 Final Thoughts: Mastering AI Model Evaluation for Real Impact
- 🙏 Acknowledgements: Experts and Resources That Shaped Our Insights
- 🛠️ Documenting Changes and Updates in AI Benchmarking Practices
- 📚 Recommended Links for Deepening Your AI Evaluation Knowledge
- ❓ Frequently Asked Questions About AI Model Benchmarking and Metrics
- 🔗 Reference Links and Further Reading
⚡️ Quick Tips and Facts on AI Model Benchmarking
Welcome, fellow AI enthusiasts and engineering wizards! At ChatBench.org™, we live and breathe AI model evaluation. It’s where the rubber meets the road, where brilliant ideas either soar or, well, gently deflate. You’ve built an amazing AI model, perhaps a cutting-edge large language model (LLM) or a sophisticated computer vision system. Now, how do you really know it’s performing as expected, or even better, outperforming the competition? 🤔
Evaluating AI models isn’t just about chasing a higher accuracy score; it’s a nuanced art and science that, if done wrong, can lead to costly mistakes, wasted resources, and even reputational damage. We’ve seen it all – from models that ace benchmarks but crumble in production to those that quietly deliver immense value despite modest-looking metrics.
Here are some quick, hard-hitting tips and facts from our trenches to get you started on the right foot:
- Fact 1: Metrics Lie (Sometimes)! 🤥 A single, high metric (like 99% accuracy) can be incredibly misleading, especially with imbalanced datasets. Always look at the full picture! As FTI Consulting wisely puts it, “If metrics appear too good to be true, they probably are.” Source: FTI Consulting
- Tip 1: Define Business Goals FIRST! 🎯 Before you even think about F1-scores, ask: What problem are we solving? What does “success” look like for the business? Tribe AI emphasizes this: “Metrics that don’t connect to business goals result in models optimized for irrelevant outcomes.” Source: Tribe AI
- Fact 2: Data Quality is King (and Queen)! 👑 Your model is only as good as the data it’s trained and evaluated on. Poor data quality, leakage, or distribution shifts are silent killers of model performance.
- Tip 2: Never Overfit to Your Test Set! 🚫 Repeatedly evaluating on the same test set is like letting your students see the exam questions beforehand. It inflates scores and leads to models that fail in the real world. This is a classic “sequential overfitting” pitfall, as highlighted in the arXiv paper on common pitfalls. Source: arXiv
- Fact 3: Real-World Performance > Benchmark Scores. 🚀 While benchmarks are crucial, they are often idealized. Expect a dip in performance when your model hits the wild. Continuous monitoring is non-negotiable.
- Tip 3: Embrace Diverse Evaluation! ✅ Don’t just rely on automated metrics. Incorporate human judgment, A/B testing, and shadow deployments. For LLMs, this means evaluating relevance, coherence, factual accuracy, and tone.
- Fact 4: AI Evaluation is an Ongoing Process. 🔄 Data changes, user behavior evolves, and new challenges emerge. Your evaluation strategy needs to be dynamic, not a one-and-done event.
Ready to dive deeper and avoid those pesky pitfalls? Let’s uncover the secrets to truly understanding your AI’s performance. For a foundational understanding of what metrics you should be looking at, check out our article on What are the key benchmarks for evaluating AI model performance?
🔍 Understanding the Landscape: Evolution and Importance of AI Performance Metrics
Remember the early days of AI? We’re talking about simple rule-based systems or basic perceptrons. Evaluating them was, comparatively, a walk in the park. You’d check if the rules were followed, or if the perceptron correctly classified linearly separable data. Fast forward to today, and we’re grappling with foundation models like OpenAI’s GPT-4, Google’s Gemini, or Meta’s Llama 3 – complex beasts with billions of parameters, capable of generating text, images, and even code. The landscape of AI has evolved dramatically, and so too must our methods for assessing their prowess.
From Simple Accuracy to Multi-Dimensional Evaluation
Historically, a simple accuracy score was often sufficient for many classification tasks. “Did it get it right or wrong?” was the primary question. But as AI models tackled more complex, real-world problems – think medical diagnosis, fraud detection, or autonomous driving – it became painfully clear that accuracy alone was a blunt instrument.
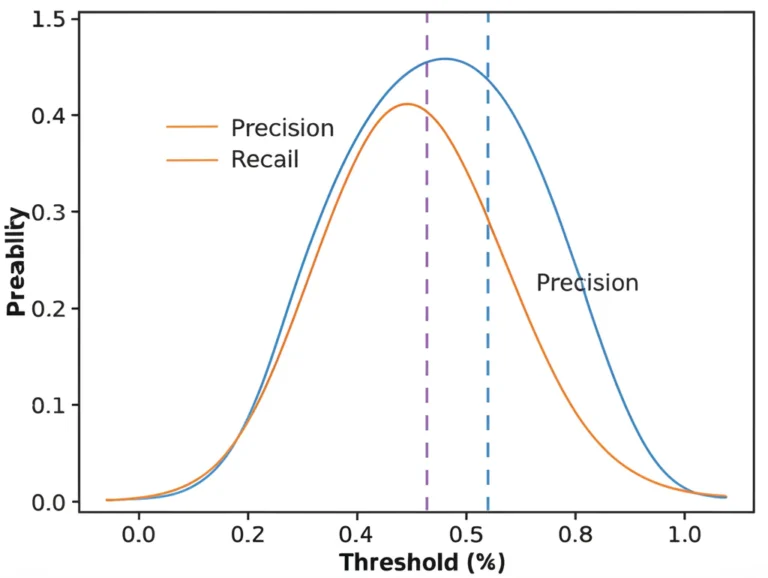
Imagine a model designed to detect a rare disease that affects 1 in 10,000 people. If your model simply predicts “no disease” every single time, it would achieve 99.99% accuracy! Sounds impressive, right? But it would miss every single positive case, rendering it utterly useless, even dangerous. This is where the importance of metrics like precision, recall, and F1-score truly shines, especially when dealing with imbalanced datasets.
The need for robust evaluation isn’t just academic; it’s a critical business imperative. Poorly evaluated models can lead to:
- Financial Losses: Deploying a model that makes incorrect predictions can cost companies millions in missed opportunities or erroneous decisions.
- Reputational Damage: Imagine a customer service AI that consistently provides unhelpful or offensive responses. Ouch.
- Ethical Concerns: Biased models, if not properly evaluated for fairness, can perpetuate and amplify societal inequalities.
- Wasted Resources: Countless hours and computational power can be poured into optimizing a model based on misleading metrics.
The Rise of Benchmarks and the Double-Edged Sword ⚔️
With the explosion of deep learning, benchmark datasets like ImageNet, GLUE, and SuperGLUE became the battlegrounds for model development. These standardized tests allowed researchers to compare models fairly and track progress. They’ve been instrumental in driving innovation, pushing the boundaries of what AI can achieve.
However, as we’ll explore in detail, benchmarks are a double-edged sword. While they offer objective, scalable comparisons, they also come with significant caveats. As the video “How Do We Grade A.I.?” (which we’ll discuss more later) points out, “a model can totally ace a multiple-choice test and still fail spectacularly at having a real complex conversation with a person.” This highlights the gap between benchmark performance and real-world utility.
At ChatBench.org™, we’ve seen firsthand how teams can get caught in the “benchmark trap,” optimizing solely for a leaderboard score without truly understanding if the model solves the underlying business problem. It’s a common pitfall, and one we’re here to help you navigate. The evolution of AI demands an evolution in our evaluation strategies – moving beyond superficial scores to deep, contextual, and continuous assessment. This is particularly true for complex systems like AI Agents that interact with dynamic environments.
🛠️ Before You Dive In: Preparing for Accurate AI Model Evaluation
Before you even think about running your first model.evaluate() command, pause. Take a deep breath. The success of your AI model evaluation hinges on meticulous preparation. Think of it like building a skyscraper: a shaky foundation guarantees disaster, no matter how impressive the penthouse suite.
1. Define Your “Why”: Aligning with Business Objectives 🎯
This is perhaps the most critical, yet often overlooked, first step. What is the real-world problem your AI model is trying to solve? How will its success be measured in terms of business impact?
- ❌ Pitfall: Optimizing for a generic metric like “accuracy” without understanding its relevance to your specific use case.
- ✅ Best Practice: Sit down with stakeholders and define clear, quantifiable business objectives.
- Are you aiming to reduce customer churn by X%?
- Increase sales conversions by Y%?
- Automate Z% of support tickets?
- Improve diagnostic speed by W minutes?
As Tribe AI rightly asserts, “Evaluation should be an ongoing process, identifying biases and failure points before launch.” This process starts with defining what you’re actually trying to achieve. Without this clarity, you’re essentially shooting in the dark, hoping to hit a target you haven’t even identified.
2. The Cornerstone: Data Quality and Representativeness 🧱
Your evaluation is only as good as your data. Period. If your evaluation dataset is flawed, biased, or unrepresentative of real-world scenarios, your metrics will be misleading, and your model will fail in production.
2.1. Curating Diverse, Representative Test Sets 🌍
- What to do: Your test set must accurately reflect the data your model will encounter in the wild. This means including:
- Typical cases: The bread-and-butter examples.
- Edge cases: Rare but important scenarios where failure could be catastrophic (e.g., unusual medical images, complex fraud patterns).
- Different demographics/segments: Ensure fairness across user groups, languages, or geographical regions.
- Temporal splits: For time-series data, ensure your test set is future data, not data from the past that the model might have implicitly learned from.
- Why it matters: “Poor data choices create several interconnected problems that can undermine even the most sophisticated models,” warns Tribe AI. A model trained on clean, balanced data might perform poorly on noisy, real-world data if the test set doesn’t reflect that noise.
2.2. The Sacred Split: Training, Validation, and Test Sets 🙏
This is fundamental. You need three distinct datasets:
- Training Set: Used to train your model.
- Validation Set: Used for hyperparameter tuning, model selection, and early stopping during development. This helps prevent overfitting to the training data.
- Test Set: The unseen, untouched dataset reserved for the final evaluation of your model’s performance. This is your model’s final exam.
Table: The Purpose of Each Dataset Split
⚡️ Quick Tips and Facts on AI Model Benchmarking
Welcome, fellow AI enthusiasts and engineering wizards! At ChatBench.org™, we live and breathe AI model evaluation. It’s where the rubber meets the road, where brilliant ideas either soar or, well, gently deflate. You’ve built an amazing AI model, perhaps a cutting-edge large language model (LLM) or a sophisticated computer vision system. Now, how do you really know it’s performing as expected, or even better, outperforming the competition? 🤔
Evaluating AI models isn’t just about chasing a higher accuracy score; it’s a nuanced art and science that, if done wrong, can lead to costly mistakes, wasted resources, and even reputational damage. We’ve seen it all – from models that ace benchmarks but crumble in production to those that quietly deliver immense value despite modest-looking metrics.
Here are some quick, hard-hitting tips and facts from our trenches to get you started on the right foot:
- Fact 1: Metrics Lie (Sometimes)! 🤥 A single, high metric (like 99% accuracy) can be incredibly misleading, especially with imbalanced datasets. Always look at the full picture! As FTI Consulting wisely puts it, “If metrics appear too good to be true, they probably are.” Source: FTI Consulting
- Tip 1: Define Business Goals FIRST! 🎯 Before you even think about F1-scores, ask: What problem are we solving? What does “success” look like for the business? Tribe AI emphasizes this: “Metrics that don’t connect to business goals result in models optimized for irrelevant outcomes.” Source: Tribe AI
- Fact 2: Data Quality is King (and Queen)! 👑 Your model is only as good as the data it’s trained and evaluated on. Poor data quality, leakage, or distribution shifts are silent killers of model performance.
- Tip 2: Never Overfit to Your Test Set! 🚫 Repeatedly evaluating on the same test set is like letting your students see the exam questions beforehand. It inflates scores and leads to models that fail in the real world. This is a classic “sequential overfitting” pitfall, as highlighted in the arXiv paper on common pitfalls. Source: arXiv
- Fact 3: Real-World Performance > Benchmark Scores. 🚀 While benchmarks are crucial, they are often idealized. Expect a dip in performance when your model hits the wild. Continuous monitoring is non-negotiable.
- Tip 3: Embrace Diverse Evaluation! ✅ Don’t just rely on automated metrics. Incorporate human judgment, A/B testing, and shadow deployments. For LLMs, this means evaluating relevance, coherence, factual accuracy, and tone.
- Fact 4: AI Evaluation is an Ongoing Process. 🔄 Data changes, user behavior evolves, and new challenges emerge. Your evaluation strategy needs to be dynamic, not a one-and-done event.
Ready to dive deeper and avoid those pesky pitfalls? Let’s uncover the secrets to truly understanding your AI’s performance. For a foundational understanding of what metrics you should be looking at, check out our article on What are the key benchmarks for evaluating AI model performance?
🔍 Understanding the Landscape: Evolution and Importance of AI Performance Metrics
Remember the early days of AI? We’re talking about simple rule-based systems or basic perceptrons. Evaluating them was, comparatively, a walk in the park. You’d check if the rules were followed, or if the perceptron correctly classified linearly separable data. Fast forward to today, and we’re grappling with foundation models like OpenAI’s GPT-4, Google’s Gemini, or Meta’s Llama 3 – complex beasts with billions of parameters, capable of generating text, images, and even code. The landscape of AI has evolved dramatically, and so too must our methods for assessing their prowess.
From Simple Accuracy to Multi-Dimensional Evaluation
Historically, a simple accuracy score was often sufficient for many classification tasks. “Did it get it right or wrong?” was the primary question. But as AI models tackled more complex, real-world problems – think medical diagnosis, fraud detection, or autonomous driving – it became painfully clear that accuracy alone was a blunt instrument.
Imagine a model designed to detect a rare disease that affects 1 in 10,000 people. If your model simply predicts “no disease” every single time, it would achieve 99.99% accuracy! Sounds impressive, right? But it would miss every single positive case, rendering it utterly useless, even dangerous. This is where the importance of metrics like precision, recall, and F1-score truly shines, especially when dealing with imbalanced datasets.
The need for robust evaluation isn’t just academic; it’s a critical business imperative. Poorly evaluated models can lead to:
- Financial Losses: Deploying a model that makes incorrect predictions can cost companies millions in missed opportunities or erroneous decisions.
- Reputational Damage: Imagine a customer service AI that consistently provides unhelpful or offensive responses. Ouch.
- Ethical Concerns: Biased models, if not properly evaluated for fairness, can perpetuate and amplify societal inequalities.
- Wasted Resources: Countless hours and computational power can be poured into optimizing a model based on misleading metrics.
The Rise of Benchmarks and the Double-Edged Sword ⚔️
With the explosion of deep learning, benchmark datasets like ImageNet, GLUE, and SuperGLUE became the battlegrounds for model development. These standardized tests allowed researchers to compare models fairly and track progress. They’ve been instrumental in driving innovation, pushing the boundaries of what AI can achieve.
However, as we’ll explore in detail, benchmarks are a double-edged sword. While they offer objective, scalable comparisons, they also come with significant caveats. As the video “How Do We Grade A.I.?” (which we’ll discuss more later) points out, “a model can totally ace a multiple-choice test and still fail spectacularly at having a real complex conversation with a person.” This highlights the gap between benchmark performance and real-world utility.
At ChatBench.org™, we’ve seen firsthand how teams can get caught in the “benchmark trap,” optimizing solely for a leaderboard score without truly understanding if the model solves the underlying business problem. It’s a common pitfall, and one we’re here to help you navigate. The evolution of AI demands an evolution in our evaluation strategies – moving beyond superficial scores to deep, contextual, and continuous assessment. This is particularly true for complex systems like AI Agents that interact with dynamic environments.
🛠️ Before You Dive In: Preparing for Accurate AI Model Evaluation
Before you even think about running your first model.evaluate() command, pause. Take a deep breath. The success of your AI model evaluation hinges on meticulous preparation. Think of it like building a skyscraper: a shaky foundation guarantees disaster, no matter how impressive the penthouse suite.
1. Define Your “Why”: Aligning with Business Objectives 🎯
This is perhaps the most critical, yet often overlooked, first step. What is the real-world problem your AI model is trying to solve? How will its success be measured in terms of business impact?
- ❌ Pitfall: Optimizing for a generic metric like “accuracy” without understanding its relevance to your specific use case.
- ✅ Best Practice: Sit down with stakeholders and define clear, quantifiable business objectives.
- Are you aiming to reduce customer churn by X%?
- Increase sales conversions by Y%?
- Automate Z% of support tickets?
- Improve diagnostic speed by W minutes?
As Tribe AI rightly asserts, “Evaluation should be an ongoing process, identifying biases and failure points before launch.” This process starts with defining what you’re actually trying to achieve. Without this clarity, you’re essentially shooting in the dark, hoping to hit a target you haven’t even identified.
2. The Cornerstone: Data Quality and Representativeness 🧱
Your evaluation is only as good as your data. Period. If your evaluation dataset is flawed, biased, or unrepresentative of real-world scenarios, your metrics will be misleading, and your model will fail in production.
2.1. Curating Diverse, Representative Test Sets 🌍
- What to do: Your test set must accurately reflect the data your model will encounter in the wild. This means including:
- Typical cases: The bread-and-butter examples.
- Edge cases: Rare but important scenarios where failure could be catastrophic (e.g., unusual medical images, complex fraud patterns).
- Different demographics/segments: Ensure fairness across user groups, languages, or geographical regions.
- Temporal splits: For time-series data, ensure your test set is future data, not data from the past that the model might have implicitly learned from.
- Why it matters: “Poor data choices create several interconnected problems that can undermine even the most sophisticated models,” warns Tribe AI. A model trained on clean, balanced data might perform poorly on noisy, real-world data if the test set doesn’t reflect that noise.
2.2. The Sacred Split: Training, Validation, and Test Sets 🙏
This is fundamental. You need three distinct datasets:
- Training Set: Used to train your model.
- Validation Set: Used for hyperparameter tuning, model selection, and early stopping during development. This helps prevent overfitting to the training data.
- Test Set: The unseen, untouched dataset reserved for the final evaluation of your model’s performance. This is your model’s final exam.
Table: The Purpose of Each Dataset Split
⚡️ Quick Tips and Facts on AI Model Benchmarking
Welcome, fellow AI enthusiasts and engineering wizards! At ChatBench.org™, we live and breathe AI model evaluation. It’s where the rubber meets the road, where brilliant ideas either soar or, well, gently deflate. You’ve built an amazing AI model, perhaps a cutting-edge large language model (LLM) or a sophisticated computer vision system. Now, how do you really know it’s performing as expected, or even better, outperforming the competition? 🤔
Evaluating AI models isn’t just about chasing a higher accuracy score; it’s a nuanced art and science that, if done wrong, can lead to costly mistakes, wasted resources, and even reputational damage. We’ve seen it all – from models that ace benchmarks but crumble in production to those that quietly deliver immense value despite modest-looking metrics.
Here are some quick, hard-hitting tips and facts from our trenches to get you started on the right foot:
- Fact 1: Metrics Lie (Sometimes)! 🤥 A single, high metric (like 99% accuracy) can be incredibly misleading, especially with imbalanced datasets. Always look at the full picture! As FTI Consulting wisely puts it, “If metrics appear too good to be true, they probably are.” Source: FTI Consulting
- Tip 1: Define Business Goals FIRST! 🎯 Before you even think about F1-scores, ask: What problem are we solving? What does “success” look like for the business? Tribe AI emphasizes this: “Metrics that don’t connect to business goals result in models optimized for irrelevant outcomes.” Source: Tribe AI
- Fact 2: Data Quality is King (and Queen)! 👑 Your model is only as good as the data it’s trained and evaluated on. Poor data quality, leakage, or distribution shifts are silent killers of model performance.
- Tip 2: Never Overfit to Your Test Set! 🚫 Repeatedly evaluating on the same test set is like letting your students see the exam questions beforehand. It inflates scores and leads to models that fail in the real world. This is a classic “sequential overfitting” pitfall, as highlighted in the arXiv paper on common pitfalls. Source: arXiv
- Fact 3: Real-World Performance > Benchmark Scores. 🚀 While benchmarks are crucial, they are often idealized. Expect a dip in performance when your model hits the wild. Continuous monitoring is non-negotiable.
- Tip 3: Embrace Diverse Evaluation! ✅ Don’t just rely on automated metrics. Incorporate human judgment, A/B testing, and shadow deployments. For LLMs, this means evaluating relevance, coherence, factual accuracy, and tone.
- Fact 4: AI Evaluation is an Ongoing Process. 🔄 Data changes, user behavior evolves, and new challenges emerge. Your evaluation strategy needs to be dynamic, not a one-and-done event.
Ready to dive deeper and avoid those pesky pitfalls? Let’s uncover the secrets to truly understanding your AI’s performance. For a foundational understanding of what metrics you should be looking at, check out our article on What are the key benchmarks for evaluating AI model performance?
🔍 Understanding the Landscape: Evolution and Importance of AI Performance Metrics
Remember the early days of AI? We’re talking about simple rule-based systems or basic perceptrons. Evaluating them was, comparatively, a walk in the park. You’d check if the rules were followed, or if the perceptron correctly classified linearly separable data. Fast forward to today, and we’re grappling with foundation models like OpenAI’s GPT-4, Google’s Gemini, or Meta’s Llama 3 – complex beasts with billions of parameters, capable of generating text, images, and even code. The landscape of AI has evolved dramatically, and so too must our methods for assessing their prowess.
From Simple Accuracy to Multi-Dimensional Evaluation
Historically, a simple accuracy score was often sufficient for many classification tasks. “Did it get it right or wrong?” was the primary question. But as AI models tackled more complex, real-world problems – think medical diagnosis, fraud detection, or autonomous driving – it became painfully clear that accuracy alone was a blunt instrument.
Imagine a model designed to detect a rare disease that affects 1 in 10,000 people. If your model simply predicts “no disease” every single time, it would achieve 99.99% accuracy! Sounds impressive, right? But it would miss every single positive case, rendering it utterly useless, even dangerous. This is where the importance of metrics like precision, recall, and F1-score truly shines, especially when dealing with imbalanced datasets.
The need for robust evaluation isn’t just academic; it’s a critical business imperative. Poorly evaluated models can lead to:
- Financial Losses: Deploying a model that makes incorrect predictions can cost companies millions in missed opportunities or erroneous decisions.
- Reputational Damage: Imagine a customer service AI that consistently provides unhelpful or offensive responses. Ouch.
- Ethical Concerns: Biased models, if not properly evaluated for fairness, can perpetuate and amplify societal inequalities.
- Wasted Resources: Countless hours and computational power can be poured into optimizing a model based on misleading metrics.
The Rise of Benchmarks and the Double-Edged Sword ⚔️
With the explosion of deep learning, benchmark datasets like ImageNet, GLUE, and SuperGLUE became the battlegrounds for model development. These standardized tests allowed researchers to compare models fairly and track progress. They’ve been instrumental in driving innovation, pushing the boundaries of what AI can achieve.
However, as we’ll explore in detail, benchmarks are a double-edged sword. While they offer objective, scalable comparisons, they also come with significant caveats. As the video “How Do We Grade A.I.?” (which we’ll discuss more later) points out, “a model can totally ace a multiple-choice test and still fail spectacularly at having a real complex conversation with a person.” This highlights the gap between benchmark performance and real-world utility.
At ChatBench.org™, we’ve seen firsthand how teams can get caught in the “benchmark trap,” optimizing solely for a leaderboard score without truly understanding if the model solves the underlying business problem. It’s a common pitfall, and one we’re here to help you navigate. The evolution of AI demands an evolution in our evaluation strategies – moving beyond superficial scores to deep, contextual, and continuous assessment. This is particularly true for complex systems like AI Agents that interact with dynamic environments.
🛠️ Before You Dive In: Preparing for Accurate AI Model Evaluation
Before you even think about running your first model.evaluate() command, pause. Take a deep breath. The success of your AI model evaluation hinges on meticulous preparation. Think of it like building a skyscraper: a shaky foundation guarantees disaster, no matter how impressive the penthouse suite.
1. Define Your “Why”: Aligning with Business Objectives 🎯
This is perhaps the most critical, yet often overlooked, first step. What is the real-world problem your AI model is trying to solve? How will its success be measured in terms of business impact?
- ❌ Pitfall: Optimizing for a generic metric like “accuracy” without understanding its relevance to your specific use case.
- ✅ Best Practice: Sit down with stakeholders and define clear, quantifiable business objectives.
- Are you aiming to reduce customer churn by X%?
- Increase sales conversions by Y%?
- Automate Z% of support tickets?
- Improve diagnostic speed by W minutes?
As Tribe AI rightly asserts, “Evaluation should be an ongoing process, identifying biases and failure points before launch.” This process starts with defining what you’re actually trying to achieve. Without this clarity, you’re essentially shooting in the dark, hoping to hit a target you haven’t even identified.
2. The Cornerstone: Data Quality and Representativeness 🧱
Your evaluation is only as good as your data. Period. If your evaluation dataset is flawed, biased, or unrepresentative of real-world scenarios, your metrics will be misleading, and your model will fail in production.
2.1. Curating Diverse, Representative Test Sets 🌍
- What to do: Your test set must accurately reflect the data your model will encounter in the wild. This means including:
- Typical cases: The bread-and-butter examples.
- Edge cases: Rare but important scenarios where failure could be catastrophic (e.g., unusual medical images, complex fraud patterns).
- Different demographics/segments: Ensure fairness across user groups, languages, or geographical regions.
- Temporal splits: For time-series data, ensure your test set is future data, not data from the past that the model might have implicitly learned from.
- Why it matters: “Poor data choices create several interconnected problems that can undermine even the most sophisticated models,” warns Tribe AI. A model trained on clean, balanced data might perform poorly on noisy, real-world data if the test set doesn’t reflect that noise.
2.2. The Sacred Split: Training, Validation, and Test Sets 🙏
This is fundamental. You need three distinct datasets:
- Training Set: Used to train your model.
- Validation Set: Used for hyperparameter tuning, model selection, and early stopping during development. This helps prevent overfitting to the training data.
- Test Set: The unseen, untouched dataset reserved for the final evaluation of your model’s performance. This is your model’s final exam.
Table: The Purpose of Each Dataset Split
| Dataset Type | Purpose
⚡️ Quick Tips and Facts on AI Model Benchmarking
Welcome, fellow AI enthusiasts and engineering wizards! At ChatBench.org™, we live and breathe AI model evaluation. It’s where the rubber meets the road, where brilliant ideas either soar or, well, gently deflate. You’ve built an amazing AI model, perhaps a cutting-edge large language model (LLM) or a sophisticated computer vision system. Now, how do you really know it’s performing as expected, or even better, outperforming the competition? 🤔
Evaluating AI models isn’t just about chasing a higher accuracy score; it’s a nuanced art and science that, if done wrong, can lead to costly mistakes, wasted resources, and even reputational damage. We’ve seen it all – from models that ace benchmarks but crumble in production to those that quietly deliver immense value despite modest-looking metrics.
Here are some quick, hard-hitting tips and facts from our trenches to get you started on the right foot:
- Fact 1: Metrics Lie (Sometimes)! 🤥 A single, high metric (like 99% accuracy) can be incredibly misleading, especially with imbalanced datasets. Always look at the full picture! As FTI Consulting wisely puts it, “If metrics appear too good to be true, they probably are.” Source: FTI Consulting
- Tip 1: Define Business Goals FIRST! 🎯 Before you even think about F1-scores, ask: What problem are we solving? What does “success” look like for the business? Tribe AI emphasizes this: “Metrics that don’t connect to business goals result in models optimized for irrelevant outcomes.” Source: Tribe AI
- Fact 2: Data Quality is King (and Queen)! 👑 Your model is only as good as the data it’s trained and evaluated on. Poor data quality, leakage, or distribution shifts are silent killers of model performance.
- Tip 2: Never Overfit to Your Test Set! 🚫 Repeatedly evaluating on the same test set is like letting your students see the exam questions beforehand. It inflates scores and leads to models that fail in the real world. This is a classic “sequential overfitting” pitfall, as highlighted in the arXiv paper on common pitfalls. Source: arXiv
- Fact 3: Real-World Performance > Benchmark Scores. 🚀 While benchmarks are crucial, they are often idealized. Expect a dip in performance when your model hits the wild. Continuous monitoring is non-negotiable.
- Tip 3: Embrace Diverse Evaluation! ✅ Don’t just rely on automated metrics. Incorporate human judgment, A/B testing, and shadow deployments. For LLMs, this means evaluating relevance, coherence, factual accuracy, and tone.
- Fact 4: AI Evaluation is an Ongoing Process. 🔄 Data changes, user behavior evolves, and new challenges emerge. Your evaluation strategy needs to be dynamic, not a one-and-done event.
Ready to dive deeper and avoid those pesky pitfalls? Let’s uncover the secrets to truly understanding your AI’s performance. For a foundational understanding of what metrics you should be looking at, check out our article on What are the key benchmarks for evaluating AI model performance?
🔍 Understanding the Landscape: Evolution and Importance of AI Performance Metrics
Remember the early days of AI? We’re talking about simple rule-based systems or basic perceptrons. Evaluating them was, comparatively, a walk in the park. You’d check if the rules were followed, or if the perceptron correctly classified linearly separable data. Fast forward to today, and we’re grappling with foundation models like OpenAI’s GPT-4, Google’s Gemini, or Meta’s Llama 3 – complex beasts with billions of parameters, capable of generating text, images, and even code. The landscape of AI has evolved dramatically, and so too must our methods for assessing their prowess.
From Simple Accuracy to Multi-Dimensional Evaluation
Historically, a simple accuracy score was often sufficient for many classification tasks. “Did it get it right or wrong?” was the primary question. But as AI models tackled more complex, real-world problems – think medical diagnosis, fraud detection, or autonomous driving – it became painfully clear that accuracy alone was a blunt instrument.
Imagine a model designed to detect a rare disease that affects 1 in 10,000 people. If your model simply predicts “no disease” every single time, it would achieve 99.99% accuracy! Sounds impressive, right? But it would miss every single positive case, rendering it utterly useless, even dangerous. This is where the importance of metrics like precision, recall, and F1-score truly shines, especially when dealing with imbalanced datasets.
The need for robust evaluation isn’t just academic; it’s a critical business imperative. Poorly evaluated models can lead to:
- Financial Losses: Deploying a model that makes incorrect predictions can cost companies millions in missed opportunities or erroneous decisions.
- Reputational Damage: Imagine a customer service AI that consistently provides unhelpful or offensive responses. Ouch.
- Ethical Concerns: Biased models, if not properly evaluated for fairness, can perpetuate and amplify societal inequalities.
- Wasted Resources: Countless hours and computational power can be poured into optimizing a model based on misleading metrics.
The Rise of Benchmarks and the Double-Edged Sword ⚔️
With the explosion of deep learning, benchmark datasets like ImageNet, GLUE, and SuperGLUE became the battlegrounds for model development. These standardized tests allowed researchers to compare models fairly and track progress. They’ve been instrumental in driving innovation, pushing the boundaries of what AI can achieve.
However, as we’ll explore in detail, benchmarks are a double-edged sword. While they offer objective, scalable comparisons, they also come with significant caveats. As the video “How Do We Grade A.I.?” (which we’ll discuss more later) points out, “a model can totally ace a multiple-choice test and still fail spectacularly at having a real complex conversation with a person.” This highlights the gap between benchmark performance and real-world utility.
At ChatBench.org™, we’ve seen firsthand how teams can get caught in the “benchmark trap,” optimizing solely for a leaderboard score without truly understanding if the model solves the underlying business problem. It’s a common pitfall, and one we’re here to help you navigate. The evolution of AI demands an evolution in our evaluation strategies – moving beyond superficial scores to deep, contextual, and continuous assessment. This is particularly true for complex systems like AI Agents that interact with dynamic environments.
🛠️ Before You Dive In: Preparing for Accurate AI Model Evaluation
Before you even think about running your first model.evaluate() command, pause. Take a deep breath. The success of your AI model evaluation hinges on meticulous preparation. Think of it like building a skyscraper: a shaky foundation guarantees disaster, no matter how impressive the penthouse suite.
1. Define Your “Why”: Aligning with Business Objectives 🎯
This is perhaps the most critical, yet often overlooked, first step. What is the real-world problem your AI model is trying to solve? How will its success be measured in terms of business impact?
- ❌ Pitfall: Optimizing for a generic metric like “accuracy” without understanding its relevance to your specific use case.
- ✅ Best Practice: Sit down with stakeholders and define clear, quantifiable business objectives.
- Are you aiming to reduce customer churn by X%?
- Increase sales conversions by Y%?
- Automate Z% of support tickets?
- Improve diagnostic speed by W minutes?
As Tribe AI rightly asserts, “Evaluation should be an ongoing process, identifying biases and failure points before launch.” This process starts with defining what you’re actually trying to achieve. Without this clarity, you’re essentially shooting in the dark, hoping to hit a target you haven’t even identified.
2. The Cornerstone: Data Quality and Representativeness 🧱
Your evaluation is only as good as your data. Period. If your evaluation dataset is flawed, biased, or unrepresentative of real-world scenarios, your metrics will be misleading, and your model will fail in production.
2.1. Curating Diverse, Representative Test Sets 🌍
- What to do: Your test set must accurately reflect the data your model will encounter in the wild. This means including:
- Typical cases: The bread-and-butter examples.
- Edge cases: Rare but important scenarios where failure could be catastrophic (e.g., unusual medical images, complex fraud patterns).
- Different demographics/segments: Ensure fairness across user groups, languages, or geographical regions.
- Temporal splits: For time-series data, ensure your test set is future data, not data from the past that the model might have implicitly learned from.
- Why it matters: “Poor data choices create several interconnected problems that can undermine even the most sophisticated models,” warns Tribe AI. A model trained on clean, balanced data might perform poorly on noisy, real-world data if the test set doesn’t reflect that noise.
2.2. The Sacred Split: Training, Validation, and Test Sets 🙏
This is fundamental. You need three distinct datasets:
- Training Set: Used to train your model.
- Validation Set: Used for hyperparameter tuning, model selection, and early stopping during development. This helps prevent overfitting to the training data.
- Test Set: The unseen, untouched dataset reserved for the final evaluation of your model’s performance. This is your model’s final exam.
Table: The Purpose of Each Dataset Split
⚡️ Quick Tips and Facts on AI Model Benchmarking
Welcome, fellow AI enthusiasts and engineering wizards! At ChatBench.org™, we live and breathe AI model evaluation. It’s where the rubber meets the road, where brilliant ideas either soar or, well, gently deflate. You’ve built an amazing AI model, perhaps a cutting-edge large language model (LLM) or a sophisticated computer vision system. Now, how do you really know it’s performing as expected, or even better, outperforming the competition? 🤔
Evaluating AI models isn’t just about chasing a higher accuracy score; it’s a nuanced art and science that, if done wrong, can lead to costly mistakes, wasted resources, and even reputational damage. We’ve seen it all – from models that ace benchmarks but crumble in production to those that quietly deliver immense value despite modest-looking metrics.
Here are some quick, hard-hitting tips and facts from our trenches to get you started on the right foot:
- Fact 1: Metrics Lie (Sometimes)! 🤥 A single, high metric (like 99% accuracy) can be incredibly misleading, especially with imbalanced datasets. Always look at the full picture! As FTI Consulting wisely puts it, “If metrics appear too good to be true, they probably are.” Source: FTI Consulting
- Tip 1: Define Business Goals FIRST! 🎯 Before you even think about F1-scores, ask: What problem are we solving? What does “success” look like for the business? Tribe AI emphasizes this: “Metrics that don’t connect to business goals result in models optimized for irrelevant outcomes.” Source: Tribe AI
- Fact 2: Data Quality is King (and Queen)! 👑 Your model is only as good as the data it’s trained and evaluated on. Poor data quality, leakage, or distribution shifts are silent killers of model performance.
- Tip 2: Never Overfit to Your Test Set! 🚫 Repeatedly evaluating on the same test set is like letting your students see the exam questions beforehand. It inflates scores and leads to models that fail in the real world. This is a classic “sequential overfitting” pitfall, as highlighted in the arXiv paper on common pitfalls. Source: arXiv
- Fact 3: Real-World Performance > Benchmark Scores. 🚀 While benchmarks are crucial, they are often idealized. Expect a dip in performance when your model hits the wild. Continuous monitoring is non-negotiable.
- Tip 3: Embrace Diverse Evaluation! ✅ Don’t just rely on automated metrics. Incorporate human judgment, A/B testing, and shadow deployments. For LLMs, this means evaluating relevance, coherence, factual accuracy, and tone.
- Fact 4: AI Evaluation is an Ongoing Process. 🔄 Data changes, user behavior evolves, and new challenges emerge. Your evaluation strategy needs to be dynamic, not a one-and-done event.
Ready to dive deeper and avoid those pesky pitfalls? Let’s uncover the secrets to truly understanding your AI’s performance. For a foundational understanding of what metrics you should be looking at, check out our article on What are the key benchmarks for evaluating AI model performance?
🔍 Understanding the Landscape: Evolution and Importance of AI Performance Metrics
Remember the early days of AI? We’re talking about simple rule-based systems or basic perceptrons. Evaluating them was, comparatively, a walk in the park. You’d check if the rules were followed, or if the perceptron correctly classified linearly separable data. Fast forward to today, and we’re grappling with foundation models like OpenAI’s GPT-4, Google’s Gemini, or Meta’s Llama 3 – complex beasts with billions of parameters, capable of generating text, images, and even code. The landscape of AI has evolved dramatically, and so too must our methods for assessing their prowess.
From Simple Accuracy to Multi-Dimensional Evaluation
Historically, a simple accuracy score was often sufficient for many classification tasks. “Did it get it right or wrong?” was the primary question. But as AI models tackled more complex, real-world problems – think medical diagnosis, fraud detection, or autonomous driving – it became painfully clear that accuracy alone was a blunt instrument.
Imagine a model designed to detect a rare disease that affects 1 in 10,000 people. If your model simply predicts “no disease” every single time, it would achieve 99.99% accuracy! Sounds impressive, right? But it would miss every single positive case, rendering it utterly useless, even dangerous. This is where the importance of metrics like precision, recall, and F1-score truly shines, especially when dealing with imbalanced datasets.
The need for robust evaluation isn’t just academic; it’s a critical business imperative. Poorly evaluated models can lead to:
- Financial Losses: Deploying a model that makes incorrect predictions can cost companies millions in missed opportunities or erroneous decisions.
- Reputational Damage: Imagine a customer service AI that consistently provides unhelpful or offensive responses. Ouch.
- Ethical Concerns: Biased models, if not properly evaluated for fairness, can perpetuate and amplify societal inequalities.
- Wasted Resources: Countless hours and computational power can be poured into optimizing a model based on misleading metrics.
The Rise of Benchmarks and the Double-Edged Sword ⚔️
With the explosion of deep learning, benchmark datasets like ImageNet, GLUE, and SuperGLUE became the battlegrounds for model development. These standardized tests allowed researchers to compare models fairly and track progress. They’ve been instrumental in driving innovation, pushing the boundaries of what AI can achieve.
However, as we’ll explore in detail, benchmarks are a double-edged sword. While they offer objective, scalable comparisons, they also come with significant caveats. As the video “How Do We Grade A.I.?” (which we’ll discuss more later) points out, “a model can totally ace a multiple-choice test and still fail spectacularly at having a real complex conversation with a person.” This highlights the gap between benchmark performance and real-world utility.
At ChatBench.org™, we’ve seen firsthand how teams can get caught in the “benchmark trap,” optimizing solely for a leaderboard score without truly understanding if the model solves the underlying business problem. It’s a common pitfall, and one we’re here to help you navigate. The evolution of AI demands an evolution in our evaluation strategies – moving beyond superficial scores to deep, contextual, and continuous assessment. This is particularly true for complex systems like AI Agents that interact with dynamic environments.
🛠️ Before You Dive In: Preparing for Accurate AI Model Evaluation
Before you even think about running your first model.evaluate() command, pause. Take a deep breath. The success of your AI model evaluation hinges on meticulous preparation. Think of it like building a skyscraper: a shaky foundation guarantees disaster, no matter how impressive the penthouse suite.
1. Define Your “Why”: Aligning with Business Objectives 🎯
This is perhaps the most critical, yet often overlooked, first step. What is the real-world problem your AI model is trying to solve? How will its success be measured in terms of business impact?
- ❌ Pitfall: Optimizing for a generic metric like “accuracy” without understanding its relevance to your specific use case.
- ✅ Best Practice: Sit down with stakeholders and define clear, quantifiable business objectives.
- Are you aiming to reduce customer churn by X%?
- Increase sales conversions by Y%?
- Automate Z% of support tickets?
- Improve diagnostic speed by W minutes?
As Tribe AI rightly asserts, “Evaluation should be an ongoing process, identifying biases and failure points before launch.” This process starts with defining what you’re actually trying to achieve. Without this clarity, you’re essentially shooting in the dark, hoping to hit a target you haven’t even identified.
2. The Cornerstone: Data Quality and Representativeness 🧱
Your evaluation is only as good as your data. Period. If your evaluation dataset is flawed, biased, or unrepresentative of real-world scenarios, your metrics will be misleading, and your model will fail in production.
2.1. Curating Diverse, Representative Test Sets 🌍
- What to do: Your test set must accurately reflect the data your model will encounter in the wild. This means including:
- Typical cases: The bread-and-butter examples.
- Edge cases: Rare but important scenarios where failure could be catastrophic (e.g., unusual medical images, complex fraud patterns).
- Different demographics/segments: Ensure fairness across user groups, languages, or geographical regions.
- Temporal splits: For time-series data, ensure your test set is future data, not data from the past that the model might have implicitly learned from.
- Why it matters: “Poor data choices create several interconnected problems that can undermine even the most sophisticated models,” warns Tribe AI. A model trained on clean, balanced data might perform poorly on noisy, real-world data if the test set doesn’t reflect that noise.
2.2. The Sacred Split: Training, Validation, and Test Sets 🙏
This is fundamental. You need three distinct datasets:
- Training Set: Used to train your model.
- Validation Set: Used for hyperparameter tuning, model selection, and early stopping during development. This helps prevent overfitting to the training data.
- Test Set: The unseen, untouched dataset reserved for the final evaluation of your model’s performance. This is your model’s final exam.
Table: The Purpose of Each Dataset Split
| Dataset Type | Purpose
🌟 Final Thoughts: Mastering AI Model Evaluation for Real Impact
Phew! We’ve journeyed through the intricate maze of AI model evaluation, uncovering the common pitfalls that trip up even seasoned practitioners and exploring robust strategies to sidestep them. At ChatBench.org™, our experience has taught us that evaluating AI models is as much an art as it is a science — it demands a holistic view, a deep understanding of your data, your business goals, and the limitations of your chosen metrics.
Remember the unresolved question we posed at the start: How do you truly know your AI model is performing well beyond just a shiny benchmark score? The answer lies in aligning your evaluation with real-world objectives, embracing diverse and representative datasets, and continuously monitoring performance post-deployment. Benchmarks and metrics are invaluable tools, but they are not the whole story. They must be wielded with care, skepticism, and a commitment to transparency.
By avoiding the common traps — like overfitting to test sets, ignoring data leakage, misinterpreting metrics, or neglecting operational considerations — you empower your AI initiatives to deliver genuine value. And when you combine rigorous evaluation with human insight and domain expertise, you transform raw AI output into actionable intelligence and competitive advantage.
So, next time you evaluate your AI model, ask yourself:
Are my metrics telling the full story?
Is my test data truly representative?
Am I ready to monitor and adapt as the world changes?
If you answer “yes” to these, congratulations — you’re on the path to mastering AI model evaluation.
📚 Recommended Links for Deepening Your AI Evaluation Knowledge
Ready to take your AI evaluation skills to the next level? Here are some curated resources and tools that we trust and recommend:
-
Books:
- “Machine Learning Yearning” by Andrew Ng — a practical guide on how to structure machine learning projects and evaluations.
Amazon Link - “Interpretable Machine Learning” by Christoph Molnar — essential reading for understanding model explainability and evaluation beyond metrics.
Amazon Link
- “Machine Learning Yearning” by Andrew Ng — a practical guide on how to structure machine learning projects and evaluations.
-
Benchmarking Platforms and Tools:
- ImageNet — the classic computer vision benchmark dataset.
- GLUE Benchmark — widely used for natural language understanding tasks.
- Weights & Biases — a powerful tool for experiment tracking and model evaluation.
- TensorBoard — visualize metrics and model behavior during training and evaluation.
-
👉 Shop AI Infrastructure and Cloud Platforms:
- Amazon Web Services (AWS): Search AI Benchmarking Tools
- Paperspace: AI Model Evaluation
- RunPod: AI Benchmarking
-
AI Model Frameworks:
- Hugging Face — hosts models and datasets with evaluation scripts.
- OpenAI — for state-of-the-art LLMs and evaluation insights.
Shopping Links for Mentioned Brands and Tools
-
OpenAI GPT Models:
Amazon Search for OpenAI GPT | OpenAI Official Website -
Meta LLaMA Models:
Amazon Search for Meta AI | Meta AI Research -
Google Gemini:
Amazon Search for Google AI | Google AI -
Weights & Biases:
Weights & Biases Official Website -
TensorBoard:
TensorFlow Official Website
❓ Frequently Asked Questions About AI Model Benchmarking and Metrics
How can I use the insights and results from evaluating my AI model’s performance to identify areas for improvement and optimize its performance over time, ultimately turning AI insight into a competitive edge?
Great question! Evaluation is not just a one-time checkpoint but a continuous feedback loop. Once you have your performance metrics and benchmark results:
- Analyze error patterns: Look beyond aggregate scores. Use confusion matrices, error heatmaps, or misclassification examples to identify specific weaknesses (e.g., certain classes or edge cases where the model fails).
- Monitor data drift: Set up monitoring to detect when input data distribution changes over time, which can degrade performance.
- Iterate with targeted data: Collect more data or augment data for the weak spots identified.
- Tune hyperparameters and architectures: Use validation metrics to guide model adjustments.
- Deploy shadow modes and A/B tests: Validate improvements in real-world conditions before full rollout.
- Leverage explainability tools: Understand model decisions to uncover biases or unexpected behaviors.
By systematically applying these insights, you transform evaluation from a static report into a dynamic engine for continuous improvement, giving you a competitive edge.
What are some best practices for using benchmarks to compare the performance of different AI models, and how can I use this information to inform my decision-making process?
Benchmarks are invaluable but must be used wisely:
- Use the same dataset and evaluation protocol: Ensure all models are tested on identical data splits and under the same conditions.
- Consider multiple metrics: Different metrics capture different aspects of performance (e.g., precision vs. recall).
- Check statistical significance: Use tests like McNemar’s or Mann-Whitney U to confirm differences aren’t due to chance.
- Beware of overfitting to benchmarks: Models optimized excessively on benchmark test sets may not generalize.
- Understand benchmark limitations: Some benchmarks may not reflect your real-world use case.
- Complement benchmarks with real-world testing: Use shadow deployments or A/B tests to validate benchmark findings.
This approach ensures your model comparisons are fair, meaningful, and actionable.
What are some common metrics used to evaluate the performance of AI models, and how can I choose the most relevant ones for my specific use case or application?
Common metrics include:
- Classification: Accuracy, Precision, Recall, F1-score, ROC-AUC, Matthews Correlation Coefficient (MCC)
- Regression: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), R-squared
- Ranking: Mean Average Precision (MAP), Normalized Discounted Cumulative Gain (NDCG)
- Generative Models: BLEU, ROUGE, METEOR, Perplexity, human evaluation scores
Choosing the right metrics depends on:
- Task type: Classification vs. regression vs. generation.
- Data characteristics: Imbalanced classes require metrics like F1 or MCC.
- Business goals: For fraud detection, high recall may be critical; for spam filtering, precision might matter more.
- Operational constraints: Latency, cost, and scalability may also be key performance indicators.
Always align metrics with your specific objectives to avoid misleading conclusions.
How can I ensure that my AI model is being evaluated fairly and without bias, and what steps can I take to mitigate any potential issues that may arise during the evaluation process?
Fair evaluation requires vigilance:
- Prevent data leakage: Strictly separate training, validation, and test sets. Avoid using test data during model tuning.
- Use representative datasets: Include diverse demographics and edge cases to detect biases.
- Apply fairness metrics: Measure disparate impact, equal opportunity, or demographic parity.
- Conduct manual reviews: Human-in-the-loop validation can catch subtle biases.
- Use explainability tools: Understand model decisions to identify unfair patterns.
- Regularly update evaluation datasets: Reflect evolving real-world conditions.
By embedding fairness checks into your evaluation pipeline, you build trustworthy and ethical AI systems.
How can benchmark selection bias affect AI model evaluation?
Benchmark selection bias occurs when the chosen benchmark datasets do not adequately represent the diversity or complexity of real-world scenarios. This can lead to:
- Over-optimistic performance estimates: Models may perform well on benchmark data but poorly in production.
- Ignoring edge cases: Rare but critical scenarios might be missing.
- Misleading comparisons: Benchmarks favor certain model architectures or training methods.
To mitigate this, diversify your evaluation datasets and complement benchmarks with domain-specific and real-world data.
What are the limitations of common AI performance metrics?
No metric is perfect. Common limitations include:
- Accuracy: Misleading on imbalanced datasets.
- Precision and Recall: Trade-offs between false positives and false negatives.
- F1-score: Balances precision and recall but ignores true negatives.
- ROC-AUC: Can be insensitive to class imbalance.
- BLEU/ROUGE for generative models: Often correlate poorly with human judgment.
Use multiple metrics and qualitative assessments to get a comprehensive view.
Why is it important to consider real-world data in AI benchmarking?
Benchmarks often use curated, clean datasets that may not capture the noise, variability, and complexity of real-world data. Evaluating on real-world data:
- Reveals hidden weaknesses and failure modes.
- Ensures robustness to distribution shifts.
- Aligns evaluation with actual user experience.
Continuous monitoring and live testing are essential complements to static benchmarks.
How do overfitting and underfitting impact AI model performance assessments?
- Overfitting: Model performs excellently on training/test data but poorly on unseen data. Leads to inflated metrics that don’t generalize.
- Underfitting: Model is too simple to capture patterns, resulting in poor performance everywhere.
Proper dataset splits, validation, and regularization techniques help detect and prevent these issues, ensuring reliable performance assessments.
🔗 Reference Links and Further Reading
- Machine Learning Model Metrics – Trust Them? | FTI Consulting
- Common Pitfalls in Evaluating AI Models Using Benchmarks and Metrics | arXiv
- Choosing the Right Data & Model Evaluation | Tribe AI
- OpenAI Official Site
- Meta AI Research
- Google AI
- Weights & Biases
- TensorFlow TensorBoard
- Hugging Face
- ImageNet
- GLUE Benchmark
These resources provide authoritative insights and tools to help you master AI model evaluation and avoid the common pitfalls we’ve discussed. Happy benchmarking! 🚀