Support our educational content for free when you purchase through links on our site. Learn more
Assessing the Accuracy of AI Systems: 12 Essential Metrics & Tips (2026) 🤖
 www.covid19.min-saude.pt by ChatBench.org")
Ever wondered how we truly know if an AI system is accurate? Spoiler: it’s way more complex than just a percentage score. At ChatBench.org™, we’ve seen AI models boasting sky-high accuracy stumble in real-world scenarios because they ignored critical nuances like bias, data quality, and evolving conditions. In this comprehensive guide, we unpack 12 essential metrics and validation techniques that will help you assess AI accuracy with confidence and avoid common pitfalls that even seasoned engineers fall into.
Stick around, because later we’ll reveal how explainability tools can expose hidden flaws behind seemingly perfect AI predictions—and why continuous monitoring is your secret weapon to keep AI reliable over time. Whether you’re building AI for healthcare, finance, or autonomous vehicles, mastering these insights will give you a competitive edge and peace of mind.
Key Takeaways
- Accuracy is multifaceted: Don’t rely on a single metric; combine precision, recall, F1 score, ROC-AUC, and confusion matrices for a full picture.
- Data quality and diversity are critical: AI accuracy depends heavily on the representativeness and cleanliness of your training data.
- Context matters: Metrics must be interpreted in light of domain-specific risks and consequences.
- Continuous validation is essential: AI models degrade over time—monitor and retrain regularly to maintain performance.
- Explainability complements accuracy: Understanding why AI makes decisions helps uncover biases and build trust.
Ready to dive deeper? Let’s decode the art and science of assessing AI accuracy like a pro!
Table of Contents
- ⚡️ Quick Tips and Facts on AI Accuracy Assessment
- 🔍 Understanding the Evolution of AI Accuracy Measurement
- 📊 1. Top Metrics for Assessing AI System Accuracy
- 🧪 2. Testing and Validation Techniques for AI Accuracy
- ⚖️ 3. Balancing Bias and Variance in AI Accuracy
- 🧠 4. The Role of Data Quality and Quantity in AI Accuracy
- 🌍 Real-World Implications of AI Accuracy in Various Industries
- 🛠️ Tools and Frameworks for Evaluating AI Accuracy
- 🔍 Common Pitfalls and How to Avoid Misleading Accuracy Results
- 🧩 Integrating Explainability with Accuracy Assessment
- 📈 Continuous Monitoring and Updating AI Accuracy Over Time
- 🧑 💻 Expert Tips for Practitioners Assessing AI Accuracy
- 🎯 Conclusion: Mastering the Art of AI Accuracy Assessment
- 🔗 Recommended Links for Deepening Your AI Accuracy Knowledge
- ❓ Frequently Asked Questions (FAQ) About AI Accuracy
- 📚 Reference Links and Further Reading
⚡️ Quick Tips and Facts on AI Accuracy Assessment
Welcome to the thrilling world of assessing AI system accuracy—where numbers meet nuance, and precision dances with context! At ChatBench.org™, we’ve seen firsthand how AI accuracy can make or break business decisions, healthcare outcomes, and even social justice. Here’s a quick cheat sheet to get you started:
- Accuracy ≠ Truth: High accuracy in AI predictions doesn’t guarantee the output reflects reality or fairness. (More on this in Understanding the Evolution of AI Accuracy Measurement)
- Multiple Metrics Matter: Don’t just look at accuracy percentage; precision, recall, F1 score, ROC-AUC, and confusion matrices provide a fuller picture.
- Data Quality is King: Garbage in, garbage out. The quality, diversity, and representativeness of your training data heavily influence accuracy.
- Context is Crucial: AI accuracy in one domain or dataset may not translate to another—beware of overgeneralization.
- Continuous Validation: AI models evolve; so should your evaluation methods. Regular monitoring prevents performance drift.
- Beware Biases: Historical biases in data can lead to AI systems that are “accurate” but unfair or unethical.
For a deep dive into benchmarks, check out our related article on key benchmarks for evaluating AI model performance.
🔍 Understanding the Evolution of AI Accuracy Measurement
Before we dive into metrics and methods, let’s unravel the history and conceptual evolution of AI accuracy assessment. Spoiler alert: it’s not as straightforward as it sounds!
From Simple Accuracy to Complex Truth
Back in the early days of AI, accuracy was often just the percentage of correct predictions — simple and seductive. But as AI tackled more complex, real-world problems, researchers realized that accuracy alone can be misleading.
- Accuracy measures how often the AI’s prediction matches the labeled data.
- Truthfulness, however, is about whether the AI’s output aligns with reality, ethics, and fairness — a much trickier beast.
As the UNU article points out, “The precision of AI predictions can be seductive, leading many to conflate high accuracy with truth.” This is a critical distinction that still trips up many practitioners.
The Rise of Sophisticated Metrics
To capture nuances beyond raw accuracy, the AI community embraced metrics like:
- Precision and Recall: Balancing false positives and false negatives.
- F1 Score: The harmonic mean of precision and recall, great for imbalanced datasets.
- ROC Curve and AUC: Visualizing trade-offs between sensitivity and specificity.
These metrics help us understand not just how often AI is right, but how it’s right — or wrong.
The Challenge of Dynamic AI Systems
Modern AI systems, especially those based on deep learning or generative models like ChatGPT, continuously evolve. This means:
- Static accuracy assessments become outdated quickly.
- Continuous monitoring and re-validation are essential.
As we’ll explore later, this ongoing evaluation is critical for maintaining trust and effectiveness.
📊 1. Top Metrics for Assessing AI System Accuracy
Let’s get technical! Here’s a detailed breakdown of the most important metrics you’ll encounter when assessing AI accuracy.
Precision, Recall, and F1 Score Explained
- Precision: Of all the positive predictions the AI made, how many were actually correct?
- Formula: TP / (TP + FP)
- High precision means fewer false positives.
- Recall (Sensitivity): Of all actual positives, how many did the AI correctly identify?
- Formula: TP / (TP + FN)
- High recall means fewer false negatives.
- F1 Score: The balance between precision and recall.
- Formula: 2 * (Precision * Recall) / (Precision + Recall)
- Useful when you need a single metric for imbalanced classes.
Example: In healthcare AI, missing a disease diagnosis (false negative) can be catastrophic, so recall is often prioritized.
Confusion Matrix and Its Role
A confusion matrix is a table that shows the counts of:
- True Positives (TP)
- True Negatives (TN)
- False Positives (FP)
- False Negatives (FN)
This matrix provides a granular view of AI performance, helping you spot where the model errs.
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | TP | FN |
| Actual Negative | FP | TN |
ROC Curve and AUC: What They Reveal
- ROC Curve plots the true positive rate (recall) against the false positive rate at various threshold settings.
- AUC (Area Under the Curve) quantifies the overall ability of the model to discriminate between classes.
- An AUC of 1 means perfect discrimination; 0.5 means no better than chance.
These are especially useful for binary classification problems with varying decision thresholds.
🧪 2. Testing and Validation Techniques for AI Accuracy
Metrics are only as good as the testing methods used to generate them. Here’s how we at ChatBench.org™ rigorously validate AI systems.
Cross-Validation Strategies
-
K-Fold Cross-Validation: Split your dataset into k parts; train on k-1 parts and test on the remaining part, repeating k times.
- Pros: Reduces overfitting, provides robust estimates.
- Cons: Computationally expensive for large datasets.
-
Stratified Cross-Validation: Ensures each fold maintains the class distribution, crucial for imbalanced datasets.
Holdout and Bootstrapping Methods
- Holdout Method: Simple split into training and testing sets. Quick but can be less reliable.
- Bootstrapping: Sampling with replacement to create multiple training sets, useful for estimating confidence intervals of accuracy metrics.
Real-World Testing vs. Synthetic Data
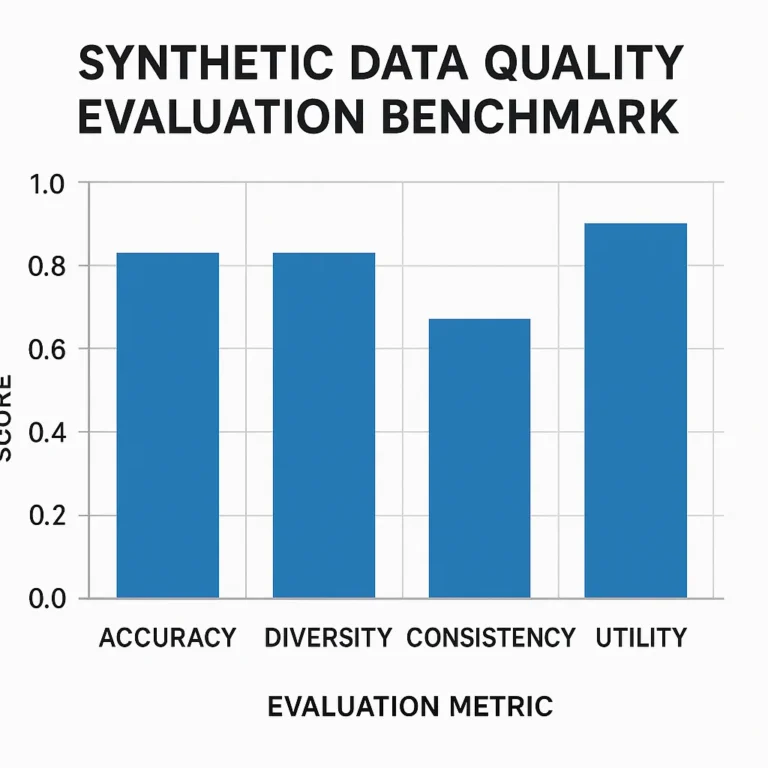
- Synthetic datasets or clinical vignettes (as in digital triage AI studies) are useful but may not capture real-world complexity.
- Observational studies and randomized controlled trials (RCTs) provide higher external validity but are costlier and slower.
⚖️ 3. Balancing Bias and Variance in AI Accuracy
One of the trickiest parts of AI accuracy assessment is managing the bias-variance tradeoff:
- Bias: Error due to overly simplistic assumptions in the model. High bias = underfitting.
- Variance: Error due to sensitivity to small fluctuations in the training set. High variance = overfitting.
Finding the sweet spot means your AI system generalizes well to new data — a key to real-world accuracy.
🧠 4. The Role of Data Quality and Quantity in AI Accuracy
We can’t stress this enough: data is the foundation of AI accuracy. Here’s why:
- Quantity: More data generally improves accuracy but with diminishing returns.
- Quality: Noisy, biased, or unrepresentative data leads to misleading accuracy.
- Diversity: Diverse datasets reduce bias and improve generalizability.
Anecdote: We once worked on a retail AI recommendation system trained on data from a single region. It scored high accuracy locally but failed miserably when deployed nationwide. Lesson learned: data diversity matters!
🌍 Real-World Implications of AI Accuracy in Various Industries
Accuracy isn’t just a number — it has real consequences. Let’s explore some high-stakes domains.
🏥 Healthcare: Patient Diagnosis and Treatment
- AI tools like IBM Watson Health and Google DeepMind’s AI have shown promise in diagnostics.
- Sensitivity and specificity are critical to avoid misdiagnosis.
- Bias in training data can lead to disparities in care, as seen in some dermatology AI models underperforming on darker skin tones.
- Continuous validation and human oversight are essential.
🚗 Autonomous Vehicles: Safety and Decision Making
- Tesla Autopilot and Waymo rely on AI accuracy for life-or-death decisions.
- False positives (e.g., unnecessary braking) and false negatives (missing obstacles) have different safety implications.
- Real-world testing under diverse conditions is mandatory.
💼 Finance: Fraud Detection and Risk Assessment
- AI models from firms like FICO and SAS detect fraudulent transactions with high precision.
- False negatives (missed fraud) cost money; false positives (flagging legitimate transactions) frustrate customers.
- Models must adapt to evolving fraud tactics.
🛠️ Tools and Frameworks for Evaluating AI Accuracy
Here’s a curated list of popular tools and frameworks that make accuracy assessment easier:
| Tool/Framework | Features | Best For | Link |
|---|---|---|---|
| scikit-learn | Wide range of metrics, easy to use | General ML model evaluation | https://scikit-learn.org/ |
| TensorBoard | Visualization of training metrics | Deep learning models | https://www.tensorflow.org/tensorboard |
| MLflow | Experiment tracking and comparison | Model lifecycle management | https://mlflow.org/ |
| Weights & Biases | Real-time monitoring, collaboration | Production AI systems | https://wandb.ai/ |
| Google Cloud AI Platform | Integrated evaluation tools | Scalable cloud AI projects | https://cloud.google.com/ai-platform |
👉 CHECK PRICE on:
- AWS AI Services: Amazon
- Google Cloud AI: Google Cloud
- Microsoft Azure AI: Microsoft Azure
🔍 Common Pitfalls and How to Avoid Misleading Accuracy Results
Beware! Even seasoned AI engineers can fall into these traps:
- Overfitting: Model performs well on training data but poorly on new data.
- Data Leakage: Test data inadvertently influences training, inflating accuracy.
- Imbalanced Datasets: Accuracy looks great but model ignores minority classes.
- Ignoring Context: Metrics without domain understanding can mislead.
- Static Evaluation: Failing to monitor model drift over time.
Pro tip: Always combine quantitative metrics with qualitative domain expertise.
🧩 Integrating Explainability with Accuracy Assessment
Accuracy is necessary but not sufficient. Explainability helps us understand why AI makes certain predictions, boosting trust and uncovering hidden flaws.
- Tools like LIME, SHAP, and Google’s Explainable AI provide insights into model decisions.
- Explainability can reveal if a model relies on spurious correlations or biased features.
- This is especially important in regulated industries like healthcare and finance.
📈 Continuous Monitoring and Updating AI Accuracy Over Time
AI accuracy is not a “set it and forget it” deal. Models degrade due to:
- Changing data distributions (concept drift).
- New user behaviors or external factors.
- Software updates and feature changes.
Best practices:
- Implement automated monitoring dashboards.
- Schedule periodic retraining with fresh data.
- Use alerting systems for performance drops.
At ChatBench.org™, we recommend adopting MLOps frameworks to streamline this lifecycle.
🧑 💻 Expert Tips for Practitioners Assessing AI Accuracy
From our trenches at ChatBench.org™, here are some golden nuggets:
- Don’t rely on a single metric. Use a suite of metrics tailored to your problem.
- Validate on real-world data as early and often as possible.
- Engage domain experts to interpret results and spot anomalies.
- Document your evaluation process for transparency and reproducibility.
- Be skeptical of “perfect” accuracy—it often signals data leakage or bias.
- Combine accuracy with explainability to build trust with stakeholders.
Stay tuned for the next sections, where we’ll wrap up with a powerful conclusion, recommended resources, and an FAQ to answer your burning questions!
🎯 Conclusion: Mastering the Art of AI Accuracy Assessment

Phew! We’ve journeyed through the intricate landscape of assessing AI system accuracy—from foundational concepts to real-world implications, and from metrics to monitoring. Here’s the bottom line: accuracy is a multifaceted gem, not just a single number. It demands a blend of rigorous metrics, thoughtful validation, high-quality data, and continuous oversight.
Remember our early tease about accuracy versus truth? We’ve now seen why high accuracy does not guarantee fairness, truthfulness, or ethical soundness. The Amazon AI hiring tool’s bias saga is a cautionary tale that accuracy alone can mask deep societal issues.
For practitioners and businesses, the key takeaway is to embrace a holistic approach:
- Use multiple complementary metrics like precision, recall, F1, and AUC.
- Validate AI models with diverse, real-world data and domain expertise.
- Monitor performance continuously to catch drift and degradation.
- Integrate explainability to build trust and uncover hidden biases.
- Stay vigilant against common pitfalls like overfitting and data leakage.
By doing so, you’ll not only measure AI accuracy but also ensure it translates into reliable, fair, and actionable insights that drive competitive advantage.
At ChatBench.org™, we confidently recommend adopting these best practices and leveraging robust tools like scikit-learn, TensorBoard, and Weights & Biases for your AI evaluation workflows. Whether you’re in healthcare, finance, autonomous vehicles, or any AI-powered domain, mastering accuracy assessment is your secret weapon for success.
🔗 Recommended Links for Deepening Your AI Accuracy Knowledge
Ready to level up your AI accuracy game? Here are some top resources and tools we endorse:
-
👉 Shop AI Evaluation Tools on Amazon:
-
Books on AI Evaluation and Ethics:
- Artificial Intelligence: A Guide for Thinking Humans by Melanie Mitchell — Amazon Link
- Prediction Machines: The Simple Economics of Artificial Intelligence by Ajay Agrawal — Amazon Link
- Weapons of Math Destruction by Cathy O’Neil (on AI bias and fairness) — Amazon Link
-
Frameworks and Libraries:
-
Ethics and Bias in AI:
❓ Frequently Asked Questions (FAQ) About AI Accuracy
 About AI Accuracy by ChatBench.org")
How can organizations balance the benefits of AI adoption with the need to mitigate potential risks and errors associated with AI system inaccuracy?
Balancing AI’s benefits and risks requires a multi-layered strategy:
- Rigorous validation: Use diverse datasets and multiple metrics to evaluate accuracy before deployment.
- Human oversight: Incorporate expert review to catch errors and ethical concerns AI might miss.
- Transparency: Clearly communicate AI limitations to stakeholders.
- Bias mitigation: Actively identify and correct biases in training data and models.
- Continuous monitoring: Track AI performance post-deployment to detect drift or degradation.
This approach ensures AI adds value without unintended harm.
What are the key challenges in assessing the accuracy of AI systems, and how can they be overcome?
Key challenges include:
- Lack of universal gold standards: Especially in complex domains like healthcare, where “truth” can be subjective.
- Data variability: Differences in data quality, distribution, and representation across contexts.
- Rapid AI evolution: Continuous updates make static evaluation obsolete quickly.
- Bias and fairness concerns: Accuracy metrics may hide systemic biases.
Overcoming these requires:
- Developing domain-specific benchmarks.
- Using real-world, diverse datasets.
- Implementing continuous validation pipelines.
- Combining quantitative metrics with explainability and ethical reviews.
What methods can be used to evaluate the performance of AI systems in real-world applications?
Effective methods include:
- Cross-validation and holdout testing on representative datasets.
- Clinical vignettes or synthetic data for initial testing (with caution).
- Observational studies and randomized controlled trials (RCTs) for high-stakes domains.
- Real-time monitoring and feedback loops post-deployment.
Combining these ensures robust, trustworthy performance evaluation.
How can businesses ensure the reliability of AI-driven decision making in their operations?
Reliability stems from:
- Robust model training and validation using diverse, high-quality data.
- Explainability tools to understand AI decisions.
- Human-in-the-loop systems for critical decisions.
- Regular audits and compliance checks aligned with industry standards.
- Clear documentation and transparency for accountability.
How can the accuracy of AI systems be continuously monitored and improved over time to maintain a competitive edge in the market and drive business growth?
Continuous improvement involves:
- Implementing MLOps frameworks for automated retraining and deployment.
- Setting up monitoring dashboards to track key metrics and detect drift.
- Collecting new data reflecting evolving conditions and user behavior.
- Engaging domain experts to interpret changes and guide updates.
- Incorporating user feedback to refine models.
This proactive approach keeps AI relevant and effective.
What are the common pitfalls and challenges in evaluating AI system accuracy, and how can organizations overcome them to ensure reliable insights?
Common pitfalls:
- Overfitting and data leakage.
- Ignoring class imbalance.
- Relying solely on accuracy without other metrics.
- Neglecting domain context and explainability.
To overcome:
- Use comprehensive metrics and validation techniques.
- Maintain strict data hygiene.
- Collaborate with domain experts.
- Integrate explainability and ethical reviews.
What metrics and benchmarks can be used to assess the accuracy and performance of AI systems in various industries and applications?
Metrics vary by domain but generally include:
- Classification: Accuracy, precision, recall, F1 score, ROC-AUC.
- Regression: Mean Squared Error (MSE), Mean Absolute Error (MAE), R-squared.
- Ranking/Recommendation: Precision@K, Recall@K, NDCG.
Benchmarks often come from industry datasets (e.g., ImageNet for vision, MIMIC for healthcare) or standardized challenges.
How can businesses evaluate the reliability of AI-driven predictions and recommendations to inform strategic decision-making?
Reliability evaluation involves:
- Testing predictions on holdout and real-world datasets.
- Measuring confidence intervals and uncertainty in outputs.
- Validating against business KPIs and outcomes.
- Incorporating human judgment and domain expertise.
- Monitoring long-term model performance and recalibrating as needed.
How can businesses measure the accuracy of AI systems effectively?
Effective measurement requires:
- Selecting appropriate metrics aligned with business goals.
- Ensuring data representativeness and quality.
- Applying robust validation techniques like cross-validation.
- Using explainability tools to interpret results.
- Documenting and communicating findings transparently.
What are the common challenges in assessing AI system performance?
Challenges include:
- Data scarcity or imbalance.
- Dynamic environments causing concept drift.
- Lack of standardized benchmarks.
- Ethical and fairness considerations.
- Complexity of AI models making interpretation difficult.
Which metrics are best for evaluating AI accuracy in competitive industries?
It depends on the application, but generally:
- Precision and recall for fraud detection and healthcare diagnostics.
- F1 score for imbalanced classification problems.
- ROC-AUC for binary classification with varying thresholds.
- Mean Squared Error for regression tasks like price prediction.
Choosing metrics aligned with business impact is key.
How does AI accuracy impact decision-making and business strategy?
AI accuracy directly influences:
- Trust and adoption of AI systems by stakeholders.
- Quality of automated decisions, affecting customer satisfaction and risk.
- Operational efficiency through reliable predictions.
- Competitive advantage by enabling data-driven strategies.
Poor accuracy can lead to costly errors, reputational damage, and missed opportunities.
📚 Reference Links and Further Reading
- UNU Article on AI Accuracy vs. Truth: Daily Maverick
- PLOS ONE Review on AI Triage Systems: PLOS ONE
- BMJ Open Quality on AI Accuracy in Healthcare: BMJ Open Quality
- IEEE Paper on Prediction Metrics: IEEE Xplore
- Google Gemini AI Overview: Google Gemini
- Amazon AI Hiring Tool Bias Case Study: BBC News
- scikit-learn Library: scikit-learn.org
- TensorBoard Visualization: TensorFlow
- Weights & Biases Platform: wandb.ai
- AWS AI Services: AWS AI
- Google Cloud AI Platform: Google Cloud AI
- Microsoft Azure Cognitive Services: Microsoft Azure AI
For a detailed case study on evaluating AI accuracy in patient classification, see:
If you want to stay ahead in AI, mastering accuracy assessment is non-negotiable. Ready to sharpen your AI edge? Dive into our resources and keep experimenting—because in AI, the journey to truth is as important as the destination! 🚀