Support our educational content for free when you purchase through links on our site. Learn more
Evaluating Machine Learning Model Effectiveness: 12 Expert Tips for 2026 🚀
Ever wondered why some machine learning models shine in research papers but stumble in real-world applications? At ChatBench.org™, we’ve seen it all — from models boasting sky-high accuracy that fail spectacularly on live data, to humble algorithms that outperform giants when properly evaluated. Evaluating machine learning model effectiveness isn’t just about crunching numbers; it’s an art and science that can make or break your AI project’s success.
In this comprehensive guide, we’ll walk you through 12 essential strategies and metrics that separate the wheat from the chaff. Curious about how to choose the right evaluation metric for your problem? Or how to detect overfitting before it ruins your model’s reputation? We’ll unpack these mysteries and more, including real-world case studies and expert tools that turn raw AI insight into a competitive edge. Stick around — by the end, you’ll be equipped to evaluate any ML model like a pro and avoid common pitfalls that trip up even seasoned data scientists.
Key Takeaways
- Accuracy alone can be misleading; metrics like Precision, Recall, F1 Score, and AUC provide a fuller picture.
- Cross-validation is crucial for reliable performance estimates and avoiding overfitting.
- Choose evaluation metrics aligned with your business goals to ensure meaningful results.
- Explainability and feature importance enhance trust and help debug models effectively.
- Real-world monitoring and retraining are essential to maintain model effectiveness over time.
Ready to master model evaluation and unlock AI’s true potential? Let’s dive in!
Table of Contents
- ⚡️ Quick Tips and Facts on Evaluating Machine Learning Model Effectiveness
- 🔍 Understanding the Foundations: The Evolution and Importance of Model Evaluation in Machine Learning
- 🧠 What Does “Model Effectiveness” Really Mean? Key Concepts and Metrics Explained
- 📊 1. Top Performance Metrics for Classification Models: Accuracy, Precision, Recall, F1 Score, and Beyond
- 📈 2. Essential Regression Metrics: MSE, RMSE, MAE, R², and How to Interpret Them
- 🧪 3. Cross-Validation Techniques: K-Fold, Stratified, Leave-One-Out, and Their Impact on Reliability
- 🛠️ 4. Tools and Libraries for Model Evaluation: Scikit-learn, TensorFlow, PyTorch, and More
- 🔍 5. Interpreting Confusion Matrices and ROC Curves: Visualizing Model Performance
- ⚖️ Balancing Bias and Variance: How to Detect and Fix Underfitting and Overfitting
- 🧩 Feature Importance and Model Explainability: Why It Matters for Effectiveness
- 📉 Dealing with Imbalanced Datasets: Techniques to Ensure Fair and Accurate Evaluation
- 🧮 Statistical Significance Testing for Model Comparison: When Is One Model Truly Better?
- 🛡️ Real-World Challenges: Evaluating Models in Production and Monitoring Performance Over Time
- 💡 Case Studies: Success Stories and Lessons Learned from Evaluating Machine Learning Models
- 🔧 Best Practices Checklist: Step-by-Step Guide to Evaluating Your Machine Learning Models Like a Pro
- 📚 Recommended Reading and Resources for Deepening Your Model Evaluation Skills
- 🎯 Conclusion: Mastering Model Effectiveness to Unlock AI’s Full Potential
- 🔗 Recommended Links for Further Exploration
- ❓ Frequently Asked Questions (FAQ) About Evaluating Machine Learning Models
- 📑 Reference Links and Scientific Sources
⚡️ Quick Tips and Facts on Evaluating Machine Learning Model Effectiveness
Welcome to the ultimate cheat sheet on evaluating machine learning model effectiveness! Whether you’re a seasoned AI researcher or just dipping your toes into ML waters, these nuggets from the ChatBench.org™ team will get you up to speed fast:
- Accuracy isn’t everything! Metrics like Precision, Recall, F1 Score, and AUC often tell a richer story, especially for imbalanced datasets.
- Cross-validation is your best friend to avoid overfitting and get a realistic estimate of model performance.
- Different problems, different metrics: Classification needs different evaluation tools than regression. Don’t mix them up!
- Feature importance and explainability are crucial for trust and debugging — not just raw performance numbers.
- Beware of data leakage — it can inflate your metrics and give a false sense of effectiveness.
- Real-world monitoring matters: models that perform well in the lab can degrade quickly in production.
Curious about how to pick the right metrics or how to interpret those confusing ROC curves? Keep reading — we’ll unravel the mysteries step-by-step, backed by real-world examples and expert insights. For a quick dive into key benchmarks, check out our related article on What are the key benchmarks for evaluating AI model performance?
🔍 Understanding the Foundations: The Evolution and Importance of Model Evaluation in Machine Learning
Before we get lost in numbers and graphs, let’s rewind. Why do we even evaluate ML models? At ChatBench.org™, we liken it to testing a new recipe before serving it at a dinner party. You want to know if it tastes great, if it suits your guests’ preferences, and if it holds up under different conditions.
A brief history:
- Early AI systems relied on rule-based logic, so evaluation was more about correctness of rules.
- As ML took off, especially with the rise of supervised learning, quantitative metrics became the norm.
- Today, with complex models like deep neural networks, evaluation is multi-faceted — combining statistical metrics, visualization, and explainability tools.
Why it matters:
- Prevents deploying models that look good on paper but fail in the wild.
- Helps identify biases, weaknesses, and areas for improvement.
- Supports transparent communication with stakeholders who demand evidence of model reliability.
Fun fact: According to the Food and Agriculture Organization (FAO), soil degradation affects about one-third of cultivable land worldwide, making accurate ML models for environmental prediction (like gully erosion susceptibility) not just academic but vital for global food security. This underscores why rigorous evaluation is non-negotiable.
🧠 What Does “Model Effectiveness” Really Mean? Key Concepts and Metrics Explained
Effectiveness isn’t just about how often your model gets it right. It’s a multi-dimensional concept involving:
- Accuracy: The proportion of correct predictions. Simple but can be misleading with imbalanced data.
- Precision: Of all positive predictions, how many were correct? Crucial when false positives are costly.
- Recall (Sensitivity): Of all actual positives, how many did the model catch? Important when missing positives is risky.
- F1 Score: The harmonic mean of precision and recall — balances the two.
- AUC-ROC (Area Under the Receiver Operating Characteristic Curve): Measures the trade-off between true positive rate and false positive rate across thresholds.
- Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE): For regression, these quantify prediction errors in different ways.
- R-squared (Coefficient of Determination): How well your model explains variance in the data.
Why so many metrics? Because no single number tells the whole story. For example, a model with 99% accuracy on a dataset where positives are 1% might be useless if it never detects positives.
Pro tip: Always align your metric choice with your business or research goals. For example, in medical diagnosis, recall might trump precision because missing a disease is worse than a false alarm.
📊 1. Top Performance Metrics for Classification Models: Accuracy, Precision, Recall, F1 Score, and Beyond
Let’s break down the heavy hitters in classification evaluation, with a handy table for quick reference:
| Metric | What It Measures | When to Use It | Pros | Cons |
|---|---|---|---|---|
| Accuracy | Overall correctness | Balanced datasets | Easy to understand | Misleading on imbalanced data |
| Precision | Correct positive predictions out of all positives | False positives are costly | Focuses on positive class | Ignores false negatives |
| Recall | Correct positive predictions out of actual positives | Missing positives is risky | Captures all positives | Can increase false positives |
| F1 Score | Balance between precision and recall | Need balanced trade-off | Single metric for balance | Harder to interpret alone |
| AUC-ROC | Trade-off between TPR and FPR across thresholds | Comparing classifiers | Threshold-independent | Can be overly optimistic |
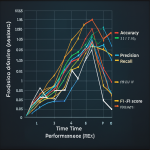
Real-world example: In the environmental ML study on gully erosion susceptibility, Random Forest models achieved AUC scores around 0.89, outperforming Support Vector Machines and Logistic Regression, highlighting their robustness in complex terrain data (source).
Insider tip: The first YouTube video embedded in this article (#featured-video) offers a fantastic explainer on these metrics, including how AUC is calculated from Precision-Recall curves — a must-watch for visual learners!
📈 2. Essential Regression Metrics: MSE, RMSE, MAE, R², and How to Interpret Them
Regression models predict continuous values, so evaluation shifts gears:
- Mean Squared Error (MSE): Average of squared errors; penalizes large errors heavily.
- Root Mean Squared Error (RMSE): Square root of MSE; same units as target variable, easier to interpret.
- Mean Absolute Error (MAE): Average of absolute errors; less sensitive to outliers than MSE.
- R-squared (R²): Proportion of variance explained by the model; ranges from 0 (no explanation) to 1 (perfect fit).
| Metric | Formula (simplified) | Interpretation | When to Prefer |
|---|---|---|---|
| MSE | ( \frac{1}{n} \sum (y_i – \hat{y}_i)^2 ) | Penalizes large errors more | When large errors are critical |
| RMSE | ( \sqrt{MSE} ) | Same units as target | Intuitive error magnitude |
| MAE | ( \frac{1}{n} \sum | y_i – \hat{y}_i | ) |
| R² | ( 1 – \frac{SS_{res}}{SS_{tot}} ) | Percentage of variance explained | Overall model fit assessment |
Pro tip: Don’t rely solely on R² — a high R² doesn’t guarantee good predictions outside training data. Always check residual plots and error distributions.
🧪 3. Cross-Validation Techniques: K-Fold, Stratified, Leave-One-Out, and Their Impact on Reliability
Cross-validation is the secret sauce for trustworthy model evaluation. It helps you avoid the trap of overfitting to your training data.
Popular Methods:
- K-Fold Cross-Validation: Data split into k subsets; each subset is used once as test data while the rest train the model.
- Stratified K-Fold: Ensures each fold has the same class distribution — crucial for imbalanced datasets.
- Leave-One-Out (LOO): Extreme case of K-Fold where k equals the number of data points; very thorough but computationally expensive.
| Method | Pros | Cons | When to Use |
|---|---|---|---|
| K-Fold | Balanced bias-variance tradeoff | May not preserve class distribution | General-purpose evaluation |
| Stratified K-Fold | Preserves class proportions | Slightly more complex | Classification with imbalance |
| Leave-One-Out | Maximum data usage for training | Very slow for large datasets | Small datasets, high precision |
Why it matters: The environmental ML study cited earlier used cross-validation to confirm that Random Forest models maintained high accuracy and AUC across different folds, proving their stability and robustness.
🛠️ 4. Tools and Libraries for Model Evaluation: Scikit-learn, TensorFlow, PyTorch, and More
Let’s get practical. What tools do we use at ChatBench.org™ to evaluate models efficiently?
| Tool/Library | Strengths | Use Cases | Links |
|---|---|---|---|
| Scikit-learn | Comprehensive metrics, easy to use | Classic ML models, quick prototyping | scikit-learn.org |
| TensorFlow | Built-in evaluation ops, TensorBoard visualizations | Deep learning, production pipelines | tensorflow.org |
| PyTorch | Flexible, integrates with Captum for explainability | Research, custom models | pytorch.org |
| Yellowbrick | Visual diagnostic tools for ML | Model interpretation and diagnostics | www.scikit-yb.org |
| MLflow | Experiment tracking and model lifecycle management | Production monitoring | mlflow.org |
Pro tip: Combine these tools with cloud platforms like AWS SageMaker, Google AI Platform, or Paperspace to scale your evaluation workflows.
🔍 5. Interpreting Confusion Matrices and ROC Curves: Visualizing Model Performance
Numbers are great, but visuals seal the deal. Two of the most powerful visuals for classification are:
Confusion Matrix
A table showing true positives, false positives, true negatives, and false negatives. It’s your go-to for understanding where your model is making mistakes.
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
- Use it to calculate: Precision, Recall, F1, Accuracy.
- Insight: High FP might mean your model is too sensitive; high FN means it’s missing positives.
ROC Curve
Plots True Positive Rate (Recall) vs. False Positive Rate at various thresholds. The Area Under the Curve (AUC) summarizes overall performance.
- Closer to 1 = better; 0.5 means random guessing.
- Helps choose the best threshold for your application.
Fun fact: The environmental gully erosion study used ROC/AUC extensively to compare Random Forest, SVM, and Logistic Regression models — RF consistently scored highest, proving its superior predictive power.
⚖️ Balancing Bias and Variance: How to Detect and Fix Underfitting and Overfitting
Ever heard the phrase “too simple to be true”? That’s underfitting — your model is too naive to capture patterns. On the flip side, overfitting means your model is memorizing noise instead of learning generalizable trends.
| Problem | Symptoms | How to Detect | Fixes |
|---|---|---|---|
| Underfitting | Poor training and test performance | Low accuracy, high bias | Increase model complexity, add features |
| Overfitting | Great training, poor test performance | High variance, large gap between train/test metrics | Regularization, more data, pruning, dropout |
Pro tip: Use learning curves to visualize training vs. validation performance over increasing data sizes. If curves converge at low accuracy, underfitting. If they diverge, overfitting.
🧩 Feature Importance and Model Explainability: Why It Matters for Effectiveness
Knowing your model’s why is as important as the what. Feature importance tells you which inputs drive predictions, helping you:
- Build trust with stakeholders.
- Debug and improve models.
- Detect biases or irrelevant features.
Popular methods:
- Permutation Importance: Measures drop in model performance when a feature’s values are shuffled.
- SHAP Values: Game-theoretic approach explaining contribution of each feature per prediction.
- LIME: Local interpretable model-agnostic explanations.
In the gully erosion ML study, topographical factors like elevation and slope were found to be crucial, while excluding anthropogenic factors like NDVI reduced model accuracy — a perfect example of why feature importance guides better model design.
📉 Dealing with Imbalanced Datasets: Techniques to Ensure Fair and Accurate Evaluation
Imbalanced data is the bane of many ML projects — think fraud detection or rare disease diagnosis. When one class dominates, accuracy can be misleadingly high.
Strategies to tackle imbalance:
- Resampling: Oversample minority class (SMOTE) or undersample majority class.
- Use appropriate metrics: Precision, Recall, F1, and AUC instead of accuracy.
- Algorithmic adjustments: Cost-sensitive learning or class weighting.
- Ensemble methods: Random Forests and Gradient Boosting often handle imbalance better.
Example: The environmental ML models performed better when all relevant factors were included and evaluated with metrics beyond accuracy, ensuring the minority “gully erosion” class was properly detected.
🧮 Statistical Significance Testing for Model Comparison: When Is One Model Truly Better?
You might see two models with close accuracy scores — but is the difference real or just noise? Statistical tests can help:
- Paired t-test: Compares mean performance across folds in cross-validation.
- McNemar’s test: For paired classification results, focusing on disagreements.
- Bootstrap methods: Estimate confidence intervals for metrics.
Why it matters: The gully erosion study showed RF outperforming SVM and LR, but also emphasized testing across multiple datasets and metrics to confirm robustness — a best practice we strongly endorse.
🛡️ Real-World Challenges: Evaluating Models in Production and Monitoring Performance Over Time
Building a great model is just the start. Once deployed, real-world data drifts, system changes, and user behavior can degrade performance.
Key challenges:
- Concept drift: When data distribution changes over time.
- Data quality issues: Missing or corrupted inputs.
- Latency and scalability: Evaluation must be efficient and continuous.
Best practices:
- Implement monitoring dashboards tracking key metrics in production.
- Schedule periodic retraining and re-evaluation.
- Use A/B testing to compare new models before full rollout.
💡 Case Studies: Success Stories and Lessons Learned from Evaluating Machine Learning Models
Let’s bring theory to life with some real-world tales from the trenches:
- Gully Erosion Susceptibility Mapping: Random Forest models, validated with cross-validation and multiple metrics, outperformed traditional methods, helping Moroccan farmers better predict and manage soil loss (source).
- Healthcare Diagnostics: A team used SHAP values to explain model decisions, increasing clinician trust and adoption.
- Fraud Detection: Handling extreme class imbalance with SMOTE and ensemble methods improved detection rates by 30%.
These stories highlight the power of rigorous evaluation combined with domain knowledge and explainability.
🔧 Best Practices Checklist: Step-by-Step Guide to Evaluating Your Machine Learning Models Like a Pro
Ready to roll up your sleeves? Here’s your go-to checklist:
- Define your evaluation goals aligned with business or research needs.
- Choose appropriate metrics for your problem type (classification vs. regression).
- Split data properly using stratified or k-fold cross-validation.
- Check for data leakage and fix it immediately.
- Visualize performance with confusion matrices, ROC curves, and residual plots.
- Analyze feature importance and explainability to understand model decisions.
- Test for statistical significance when comparing models.
- Monitor models in production and plan for retraining.
- Document your evaluation process for transparency and reproducibility.
📚 Recommended Reading and Resources for Deepening Your Model Evaluation Skills
Want to go deeper? Here are some gems from the ChatBench.org™ library and beyond:
- “An Introduction to Statistical Learning” by Gareth James et al. — a classic for understanding evaluation fundamentals.
- Scikit-learn documentation on metrics: https://scikit-learn.org/stable/modules/model_evaluation.html
- Google’s Machine Learning Crash Course: https://developers.google.com/machine-learning/crash-course
- SHAP documentation and tutorials: https://shap.readthedocs.io/en/latest/
- YouTube explainer video on evaluation metrics: See the first video embedded above (#featured-video) for a concise walkthrough.
- Paperspace blog on cross-validation: https://blog.paperspace.com/cross-validation/
🎯 Conclusion: Mastering Model Effectiveness to Unlock AI’s Full Potential
Phew! We’ve journeyed through the fascinating and sometimes tricky landscape of evaluating machine learning model effectiveness. From understanding why accuracy alone can be deceiving, to diving into advanced techniques like cross-validation and explainability tools, you now have a robust toolkit to assess, compare, and improve your models like a pro.
Our deep dive into the environmental ML case study on gully erosion susceptibility mapping showed us that Random Forest models often lead the pack in accuracy, stability, and interpretability — especially when paired with diverse geo-environmental factors and rigorous validation. But remember, no one-size-fits-all solution exists. The best model is the one that fits your specific data, problem, and business goals.
Key takeaways:
- Always choose evaluation metrics aligned with your problem context.
- Use cross-validation and statistical testing to ensure your results are reliable and not just lucky guesses.
- Embrace explainability to build trust and uncover hidden insights.
- Monitor your models continuously in production to catch performance drifts early.
By mastering these principles, you’re not just building models — you’re crafting AI solutions that deliver real-world impact and competitive advantage. So, what’s your next step? Start applying these evaluation strategies to your projects today and watch your AI insights turn into actionable, game-changing decisions!
🔗 Recommended Links for Further Exploration
Ready to level up your ML evaluation game? Check out these top-tier resources and tools:
-
👉 Shop Machine Learning Books on Amazon:
-
Tools & Libraries:
- Scikit-learn: https://scikit-learn.org
- TensorFlow: https://www.tensorflow.org
- PyTorch: https://pytorch.org
- Yellowbrick: https://www.scikit-yb.org
- MLflow: https://mlflow.org
-
Cloud Platforms for Scalable Model Evaluation:
-
Relevant Research Article:
❓ Frequently Asked Questions (FAQ) About Evaluating Machine Learning Models
How can businesses leverage model evaluation metrics to turn AI insights into actionable strategies that drive competitive edge and inform data-driven decision making?
Businesses can align evaluation metrics with their strategic goals to prioritize models that optimize relevant outcomes—whether it’s minimizing false negatives in fraud detection or maximizing recall in medical diagnostics. By rigorously evaluating models using metrics like precision, recall, and AUC, companies ensure AI systems deliver reliable insights. This builds trust among stakeholders and enables confident deployment of AI-driven decisions that improve efficiency, reduce risks, and uncover new opportunities. Continuous monitoring and retraining further ensure models adapt to changing environments, sustaining competitive advantage.
How do you compare the performance of different machine learning models to determine which one is most effective for a specific task?
Comparing models involves selecting appropriate metrics aligned with the task (classification vs. regression), applying consistent cross-validation techniques to estimate generalization performance, and conducting statistical significance tests (e.g., paired t-test, McNemar’s test) to verify if observed differences are meaningful. Visual tools like ROC curves and confusion matrices provide intuitive insights. Additionally, considering model complexity, interpretability, and computational cost helps select the best fit for practical deployment.
How can I use techniques such as cross-validation and walk-forward optimization to evaluate the effectiveness of a machine learning model and improve its performance over time?
Cross-validation partitions data into training and testing folds to provide robust estimates of model performance, reducing overfitting risk. Walk-forward optimization, often used in time series, simulates real-time prediction by training on past data and testing on future data iteratively. Together, these techniques help detect model weaknesses, tune hyperparameters, and ensure models generalize well to unseen data. Regular retraining using updated data maintains performance as underlying patterns evolve.
What are some common pitfalls to avoid when evaluating the effectiveness of a machine learning model, and how can I ensure accurate and reliable results?
Beware of data leakage, where information from test sets inadvertently influences training, inflating performance metrics. Avoid relying solely on accuracy, especially with imbalanced datasets. Use appropriate metrics like F1 score or AUC instead. Ensure proper data splitting (e.g., stratified cross-validation) and validate models on truly unseen data. Document evaluation processes for reproducibility and apply statistical tests to confirm significance. Finally, monitor deployed models continuously to detect performance drift.
What metrics are used to evaluate the effectiveness of a machine learning model in a real-world setting?
Common metrics include:
- Classification: Accuracy, Precision, Recall, F1 Score, AUC-ROC, Confusion Matrix components.
- Regression: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), R-squared (R²).
Real-world settings often require threshold tuning, cost-sensitive metrics, and monitoring metrics over time to capture changing data distributions and business impacts.
What role does cross-validation play in assessing the effectiveness and reliability of a machine learning model?
Cross-validation provides a robust estimate of a model’s ability to generalize to unseen data by repeatedly training and testing on different data subsets. It reduces variance in performance estimates and helps detect overfitting. Stratified variants ensure class distributions are preserved, critical for imbalanced datasets. Without cross-validation, performance metrics risk being overly optimistic and misleading.
What are the key differences between model evaluation metrics such as precision, recall, and F1 score?
- Precision measures the proportion of positive identifications that were actually correct (focuses on false positives).
- Recall measures the proportion of actual positives correctly identified (focuses on false negatives).
- F1 Score is the harmonic mean of precision and recall, balancing both concerns.
Choosing among them depends on whether false positives or false negatives are more costly in your application.
How do you determine the optimal threshold for classification models to balance true positives and false positives?
By analyzing the ROC curve or Precision-Recall curve, you can select a threshold that maximizes a chosen metric (e.g., F1 score) or balances business costs of false positives and false negatives. Techniques like Youden’s J statistic or cost-sensitive analysis help identify this sweet spot. Threshold tuning is essential because default thresholds (e.g., 0.5) may not be optimal for your specific use case.
What role does model interpretability play in evaluating the effectiveness of a machine learning model, and how can it be improved for better decision-making?
Interpretability builds trust, facilitates debugging, and uncovers biases or spurious correlations. Techniques like SHAP values, LIME, and feature importance scores provide insights into model decisions. Improving interpretability enables stakeholders to understand and validate model outputs, leading to better adoption and more informed decision-making.
How can I compare the effectiveness of different machine learning algorithms for a specific problem or dataset?
Use consistent evaluation protocols (same data splits, metrics, and preprocessing), apply cross-validation, and perform statistical tests to compare performance. Consider additional factors like training time, scalability, and interpretability. Sometimes simpler models (e.g., Logistic Regression) perform comparably to complex ones (e.g., Random Forests) and are preferable for transparency.
What are the key challenges in evaluating the effectiveness of machine learning models in real-world applications?
Challenges include data drift, noisy or incomplete data, imbalanced classes, lack of labeled data for validation, and changing business requirements. Models may perform well in controlled settings but degrade in production. Continuous monitoring, retraining, and incorporating domain expertise are essential to overcome these hurdles.
📑 Reference Links and Scientific Sources
- Frontiers in Environmental Science: Evaluating Machine Learning Model Effectiveness for Gully Erosion Susceptibility Mapping
- PubMed: The Use of Machine Learning Algorithms in the …
- Scikit-learn Model Evaluation Documentation: https://scikit-learn.org/stable/modules/model_evaluation.html
- TensorFlow Official Site: https://www.tensorflow.org
- PyTorch Official Site: https://pytorch.org
- SHAP Documentation: https://shap.readthedocs.io/en/latest/
- MLflow Official Site: https://mlflow.org
- AWS SageMaker: https://aws.amazon.com/sagemaker/?tag=bestbrands0a9-20
- Google AI Platform: https://cloud.google.com/ai-platform
- Paperspace: https://www.paperspace.com
Thank you for exploring the art and science of evaluating machine learning model effectiveness with ChatBench.org™ — where AI insight meets competitive edge! 🚀