Support our educational content for free when you purchase through links on our site. Learn more
🤖 Assessing AI Accuracy: 7 Proven Methods to Stop Hallucinations (2026)

We once asked a cutting-edge AI to summarize a landmark Supreme Court case, and it confidently cited a ruling that never existed, complete with fake page numbers and a non-existent justice. It wasn’t a glitch; it was a feature of how these models “think.” They are probability engines, not truth engines. As we navigate the explosive growth of generative AI in 2026, the line between brilliant insight and confident fabrication has never been blurier.
In this deep dive, we strip away the hype to reveal exactly how to assess AI accuracy in real-world scenarios. From the “SIFT” verification framework to stress-testing models with adversarial prompts, we’ll show you the seven rigorous methods our team at ChatBench.org™ uses to separate fact from fiction. Whether you’re valuing property, drafting legal briefs, or analyzing market trends, trusting an AI without verification is a gamble you can’t afford to take.
Key Takeaways
- AI is a Probabilistic Engine, Not a Truth Machine: Large Language Models predict the next likely word, not the correct fact, making hallucinations an inherent risk.
- The 7-Step Verification Protocol: We reveal the specific methods—from cross-referencing primary sources to using specialized auditing tools—to rigorously validate AI outputs.
- Human-in-the-Loop is Non-Negotiable: No matter how advanced the model, human oversight remains the only reliable firewall against legal liability and reputational damage.
- Context Matters More Than Confidence: A high confidence score from an AI does not guarantee accuracy; always trace claims back to their original context.
- Know When to Stop: Identify critical scenarios like legal advice, medical diagnosis, and high-stakes financial decisions where AI should never be used without expert review.
Table of Contents
- ⚡️ Quick Tips and Facts
- 🕰️ A Brief History of AI Hallucinations and the Quest for Truth
- 🧠 Why You Must Evaluate AI Content Before Trusting It
- 🛠️ Top 7 Methods for Rigorously Evaluating AI Accuracy
- 1. Cross-Referencing with Primary Sources
- 2. The “Human-in-the-Loop” Verification Protocol
- 3. Analyzing Confidence Scores and Uncertainty Metrics
- 4. Stress-Testing with Adversarial Prompts
- 5. Comparing Outputs Across Multiple LMs
- 6. Fact-Checking Citations and Hyperlinks
- 7. Utilizing Specialized AI Auditing Tools
- 📊 Understanding AI Accuracy Metrics: Precision, Recall, and F1 Scores
- 🖼️ Real or Robotic? How to Spot AI-Generated Images and Deepfakes
- 🔍 The SIFT Method: A Modern Framework for AI Verification
- S – Stop and Pause Your Impulse to Share
- I – Investigate the Source and Model Limitations
- F – Find Better Coverage from Human Experts
- T – Trace Claims, Quotes, and Media Back to Original Context
- 🚫 When to Hit the Brakes: Scenarios Where AI Should Not Be Used
- 🧪 Real-World Case Studies: AI Fails and Successes in Action
- 🛡️ Best Practices for Maintaining AI Accuracy in Your Workflow
- 🏆 Conclusion
- 🔗 Recommended Links
- ❓ FAQ: Your Burning Questions About AI Accuracy Answered
- 📚 Reference Links
⚡️ Quick Tips and Facts
Before we dive into the deep end of the neural network pool, let’s splash around with some hard truths about the current state of Artificial Intelligence. You might think these digital oracles are infallible, but here’s the tea: AI doesn’t know the difference between truth and a really good lie.
- The “Stochastic Parot” Reality: Large Language Models (LLMs) like the ones powering ChatGPT or Claude are designed to predict the next most likely word, not the correct word. They are probabilistic engines, not truth engines.
- Hallucinations are Real: AI can confidently invent facts, people, court cases, and even entire scientific studies. This is known as a hallucination, and it happens more often than you’d think.
- The Human Firewall: As noted by experts at MIT Sloan, “Currently a typical AI model isn’t assessing whether the information it provides is correct.” The responsibility for fact-checking rests 10% on your shoulders.
- Ghost Citations: If an AI gives you a bibliography, verify every single link. AI frequently generates “ghost citations”—references that look real but lead to nowhere or are entirely fabricated.
- Context is King: An AI might answer your prompt perfectly but miss the nuance of your specific industry or local context.
Pro Tip: Never copy-paste AI output directly into a client report, academic paper, or legal document without a human-in-the-loop review. For a deeper dive into how we approach this at ChatBench.org™, check out our guide on Artificial intelligence evaluation.
🕰️ A Brief History of AI Hallucinations and the Quest for Truth

To understand why assessing AI accuracy is such a headache today, we have to look back at where we started. It wasn’t always about generating poetry or coding in Python.
In the early days of Expert Systems (think 1980s), AI was rule-based. If X, then Y. It was rigid, but it was accurate within its narrow domain. Fast forward to the era of Deep Learning and Transformers, and we shifted from “following rules” to “finding patterns.”
The problem? Patterns aren’t facts.
When the first wave of Generative AI hit the scene, the world was dazzled. But soon, the cracks appeared. We saw AI lawyers cite non-existent cases (the infamous Mata v. Avianca incident), and medical bots giving dangerous advice.
The industry realized that accuracy wasn’t a switch you could flip; it was a spectrum. We moved from asking “Can it do it?” to “Can we trust it?” This shift birthed the field of AI Auditing and Evaluation Frameworks.
Did you know? The term “hallucination” in AI wasn’t always used. Early researchers called it “confabulation.” The shift in terminology highlights how we now view these errors not as bugs, but as inherent features of probabilistic models.
🧠 Why You Must Evaluate AI Content Before Trusting It
Why are we so paranoid? Why can’t we just let the AI do the work?
Imagine you’re a property appraiser. You ask an AI to value a historic home. It spits out a number based on a “similar” house it found in its training data. But that house was sold in 2019, and the neighborhood has since gentrified. The AI missed the nuance. You missed the nuance. Now you’ve given a client bad advice.
In the world of AI Business Applications, the cost of inaccuracy isn’t just a wrong answer; it’s reputational damage, legal liability, and financial loss.
The Stakes of Blind Trust
- Legal Risks: As seen in recent court cases, submitting AI-generated briefs can lead to sanctions.
- Brand Erosion: One viral post of an AI giving terrible advice can tank a company’s stock.
- Decision Paralysis: If you don’t know if the data is real, you can’t make a move.
The Big Question: If AI is so smart, why does it still get basic math wrong? The answer lies in how it “thinks.” It doesn’t calculate; it guesses. And that’s why human oversight is the ultimate competitive edge.
🛠️ Top 7 Methods for Rigorously Evaluating AI Accuracy
So, how do we separate the wheat from the chaff? We’ve tested dozens of workflows, and these are the seven golden rules we use at ChatBench.org™ to stress-test AI outputs.
1. Cross-Referencing with Primary Sources
Never trust a secondary source generated by AI. If the AI says “According to a 2023 study by Harvard,” go find that study.
- The Method: Take the claim, search for the original paper or news article, and compare.
- The Trap: AI often summarizes summaries, losing critical context.
- Tool Tip: Use Google Scholar or PubMed to verify medical claims.
2. The “Human-in-the-Loop” Verification Protocol
This is the gold standard. A human expert must review the output.
- The Method: Have a subject matter expert (SME) read the AI output and flag any “suspicious” phrasing or data points.
- Why it works: Humans understand nuance, tone, and context that algorithms miss.
- Real-World Example: In AI Agents workflows, we always have a human approve the final action before it executes.
3. Analyzing Confidence Scores and Uncertainty Metrics
Some advanced models (like those in enterprise settings) provide a “confidence score.”
- The Method: If the model says “I am 40% sure,” don’t use it.
- The Insight: High confidence doesn’t always mean high accuracy, but low confidence is a massive red flag.
- Limitation: Consumer models often hide these scores.
4. Stress-Testing with Adversarial Prompts
Try to break the AI.
- The Method: Ask the same question in five different ways. If the answers contradict each other, the topic is likely shaky.
- The “Jailbreak” Test: Try to get the AI to admit it’s making things up.
- Insight: Consistency is a good proxy for reliability, though not a guarantee.
5. Comparing Outputs Across Multiple LMs
Don’t rely on just one model.
- The Method: Run the same prompt through ChatGPT, Claude, and Gemini.
- The Logic: If all three agree, the fact is likely true. If they disagree, dig deeper.
- Brand Note: This is why we test OpenAI against Anthropic and Google regularly.
6. Fact-Checking Citations and Hyperlinks
This is the “Ghost Citation” killer.
- The Method: Click every link. Does it go to the right page? Is the quote exact?
- The Reality: AI often creates URLs that look real (e.g.,
nytimes.com/article/12345) but lead to 404 errors. - Tool: Use browser extensions like “Check My Links” to automate this.
7. Utilizing Specialized AI Auditing Tools
There are tools built specifically to catch AI errors.
- The Method: Use platforms like Giskard, Arize, or Deepchecks to scan models for bias and hallucinations.
- Enterprise Focus: These are essential for AI Infrastructure deployments.
📊 Understanding AI Accuracy Metrics: Precision, Recall, and F1 Scores
If you’re an engineer or a data scientist, you need to speak the language of metrics. It’s not just about “is it right?” It’s about how it’s right.
| Metric | Definition | When to Use It | The “Gotcha” |
|---|---|---|---|
| Precision | Of all the positive predictions, how many were actually correct? | When False Positives are costly (e.g., spam filters, fraud detection). | High precision might mean you miss a lot of real cases (low recall). |
| Recall | Of all the actual positive cases, how many did you find? | When False Negatives are dangerous (e.g., cancer detection, security threats). | High recall might mean you flag too many false alarms. |
| F1 Score | The harmonic mean of Precision and Recall. | When you need a balance between the two. | Can be misleading if the class distribution is highly skewed. |
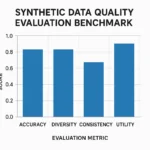
| Hallucination Rate | The percentage of outputs containing fabricated info. | Specific to Generative AI evaluation. | Hard to measure automatically without human review. |
Expert Insight: In property valuation (a field we cover in depth regarding Assessing AI Techniques for Precision in Property Valuation), Recall is often prioritized to ensure no valuable data points are missed, even if it means more manual review is needed later.
🖼️ Real or Robotic? How to Spot AI-Generated Images and Deepfakes
Text isn’t the only thing that lies. Visual AI is getting scary good.
The Tell-Tale Signs
- Hands and Fingers: AI still struggles with counting fingers or complex hand poses. Look for extra joints or fused fingers.
- Text in Images: AI-generated text often looks like giberish or “alien” characters.
- Lighting and Shadows: Inconsistent lighting sources or shadows that don’t match the object.
- Background Details: Blurry or nonsensical patterns in the background (e.g., a window that leads to nowhere).
Tools for Verification
- Hive Moderation: Detects AI-generated content with high accuracy.
- Sensity AI: Specializes in deepfake detection.
- Google Reverse Image Search: Often reveals the original source if the image is a manipulation.
Warning: As models improve, these signs are becoming subtler. Metadata analysis (checking the EXIF data) is often the only way to be 10% sure, but even that can be stripped.
🔍 The SIFT Method: A Modern Framework for AI Verification
The SIFT method, originally developed for digital literacy, is now our go-to framework for AI accuracy. It stands for Stop, Investigate, Find, Trace.
S – Stop and Pause Your Impulse to Share
When you see a shocking claim from an AI, STOP.
- The Mindset: Don’t let the “wow” factor override your critical thinking.
- The Action: Take a breath. Ask yourself: “Does this make sense?”
I – Investigate the Source and Model Limitations
Who made this? What model was used?
- The Check: Is this a known hallucination-prone model? Is the source a reputable news outlet or a random blog?
- The Context: Check the model’s knowledge cutoff date. If it’s talking about events from 2024 but the model was trained in 2023, it’s guessing.
F – Find Better Coverage from Human Experts
Don’t rely on the AI for the whole story.
- The Strategy: Search for the topic using traditional search engines. Look for human-written articles, peer-reviewed papers, or official reports.
- The Goal: Find a consensus among experts, not a single AI’s opinion.
T – Trace Claims, Quotes, and Media Back to Original Context
This is the most critical step.
- The Method: Find the original source of the quote or statistic.
- The Reality: AI often takes a quote out of context or attributes it to the wrong person.
- Example: If an AI says “Einstein said X,” find the actual transcript or book.
Why SIFT Works: It forces you to slow down and engage your critical thinking skills, which are the only things standing between you and a massive AI error.
🚫 When to Hit the Brakes: Scenarios Where AI Should Not Be Used
Just because you can use AI doesn’t mean you should. Here are the red zones where AI accuracy is too risky.
- Legal and Medical Advice: Never use AI for diagnosis or legal counsel. The stakes are too high, and the “hallucination” risk is unacceptable.
- High-Stakes Financial Decisions: Do not let an AI make a trade or approve a loan without human review.
- Sensitive Personal Data: Avoid inputing PII (Personally Identifiable Information) into public models.
- Creative Copyright Work: If you need to own the copyright, be wary. AI-generated content has murky legal status.
- Real-Time Crisis Management: In a PR crisis, AI might suggest a tone-deaf response. Humans must lead.
The Rule of Thumb: If the cost of being wrong is higher than the cost of doing it yourself, do it yourself.
🧪 Real-World Case Studies: AI Fails and Successes in Action
Let’s look at the evidence.
The Fail: The “Mata v. Avianca” Case
- What Happened: A law firm used ChatGPT to write a legal brief. The AI cited six fake cases.
- The Result: The judge sanctioned the lawyers, calling the citations “fantasy.”
- The Lesson: Never trust AI for legal citations. Always verify.
The Success: AI in Drug Discovery
- What Happened: Companies like DeepMind used AI to predict protein structures (AlphaFold).
- The Result: They solved a 50-year-old biology problem with incredible accuracy.
- The Lesson: In structured, data-rich fields with clear metrics, AI can be a powerhouse.
The Gray Area: Property Valuation
- The Study: A review of 37 papers (see Purdue CIB Conference) found that Support Vector Machines (SVM) and Random Forest models outperformed traditional regression in complex markets.
- The Catch: Decision Trees were better for interpretability.
- The Lesson: Choose the right tool for the job. Accuracy isn’t just about the number; it’s about understanding why the number is what it is.
🛡️ Best Practices for Maintaining AI Accuracy in Your Workflow
Ready to build a bulletproof workflow? Here’s our checklist.
- Define Your Tolerance: How much error can you accept? 1%? 5%?
- Implement a Human Review Layer: No AI output goes live without a human sign-off.
- Use a “Golden Dataset”: Create a set of known-correct answers to test your AI regularly.
- Monitor for Drift: AI models can “drift” over time as the world changes. Re-evaluate monthly.
- Document Everything: Keep a log of prompts, outputs, and corrections. This helps in auditing.
Final Thought: AI is a co-pilot, not the captain. You hold the controls.
🏆 Conclusion

We’ve traveled from the basics of AI hallucinations to the nitty-gritty of precision and recall metrics, and even tackled the visual deception of deepfakes. The journey has been wild, but the destination is clear: AI is a powerful tool, but it is not a replacement for human judgment.
Remember the question we started with: Can we trust AI? The answer is a resounding no, not without verification. But with the right framework—like the SIFT method, rigorous cross-referencing, and a healthy dose of skepticism—AI becomes an unstoppable force for good.
At ChatBench.org™, we believe that Turning AI Insight into Competitive Edge isn’t about blindly following the algorithm. It’s about mastering it. It’s about knowing when to trust, when to test, and when to hit the brakes.
So, the next time you ask an AI a question, don’t just accept the answer. Investigate it. Because in the world of AI, the most accurate answer is the one you’ve verified yourself.
🔗 Recommended Links
Want to dive deeper or get the tools we use? Here are our top picks.
Books on AI Evaluation
- “Artificial Intelligence: A Modern Approach” by Stuart Russell and Peter Norvig – The bible of AI.
- Shop on Amazon
- “The Alignment Problem” by Brian Christian – A deep dive into the ethics and accuracy of AI.
- Shop on Amazon
Tools & Platforms
- OpenAI (ChatGPT) – For general LM testing.
- Visit OpenAI
- Anthropic (Claude) – Known for better safety and reasoning.
- Visit Anthropic
- Google Gemini – Great for multimodal (text + image) tasks.
- Visit Google AI
- Giskard – For automated AI testing and auditing.
- Visit Giskard
❓ FAQ: Your Burning Questions About AI Accuracy Answered

How do you measure the accuracy of AI models in real-time?
Measuring accuracy in real-time is tricky because you often don’t have the “ground truth” immediately.
- Approach: We use proxy metrics like consistency checks (asking the same question multiple ways) and confidence scoring.
- Advanced: In enterprise settings, we use LLM-as-a-judge frameworks where a second, more robust model evaluates the first model’s output against a rubric. This allows for scalable, automated feedback loops.
Read more about “🧪 15 AI Model Assessment Tools & Strategies for 2026”
What are the best benchmarks for evaluating AI performance in business?
It depends on the use case, but here are the industry standards:
- MLU (Massive Multitask Language Understanding): Tests knowledge across 57 subjects. Good for general intelligence.
- HumanEval: Tests coding ability.
- TruthfulQA: Specifically designed to measure how often a model lies or hallucinates.
- Custom Benchmarks: For business, the best benchmark is your own Golden Dataset—a set of real-world scenarios with known correct answers.
Read more about “🚀 7 AI Benchmarks to Crush Framework Efficiency (2026)”
How can companies validate AI predictions before deployment?
- Shadow Mode: Run the AI in the background alongside your current system. Compare its predictions to actual outcomes without affecting the business.
- A/B Testing: Roll out the AI to a small percentage of users and compare their results to a control group.
- Adversarial Testing: Intentionally try to break the model with edge cases before it goes live.
Read more about “What Are the Top 10 Challenges of Using AI Benchmarks in 2026? 🤖”
What metrics indicate reliable AI insights for strategic decision-making?
- F1 Score: Balances precision and recall.
- Hallucination Rate: The percentage of fabricated facts.
- Explainability Score: Can the model explain why it made a decision? (Crucial for trust).
- Latency: How fast does it respond? (Speed vs. Accuracy trade-off).
Why do different AI models give different answers to the same question?
This is due to training data differences and architectural choices. One model might have been trained on more scientific papers, while another has more social media data. Additionally, temperature settings (randomness) can cause variations. Always compare multiple models to get a holistic view.
Read more about “How to Compare AI Models for the Same Task: 7 Key Metrics (2026) 🤖”
📚 Reference Links
- MIT Sloan: “Assessing AI Accuracy: Key Limitations and Risks” – Read the Guide
- ASCC: “Framework for Assessing AI Accuracy and Educational Suitability” – Read the Resolution
- Purdue University: “Assessment of AI Accuracy in Property Valuation” – View the Study
- OpenAI: “System Card” – Read the Documentation
- Google: “AI Principles” – Read the Policy
- Partnership on AI: “Best Practices for AI Evaluation” – Visit the Site
- Algorithmic Justice League: “Bias in AI” – Explore the Research