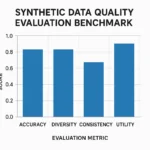
Support our educational content for free when you purchase through links on our site. Learn more
🧠 Vision vs. Speech: How DL Benchmarks Differ (2026)
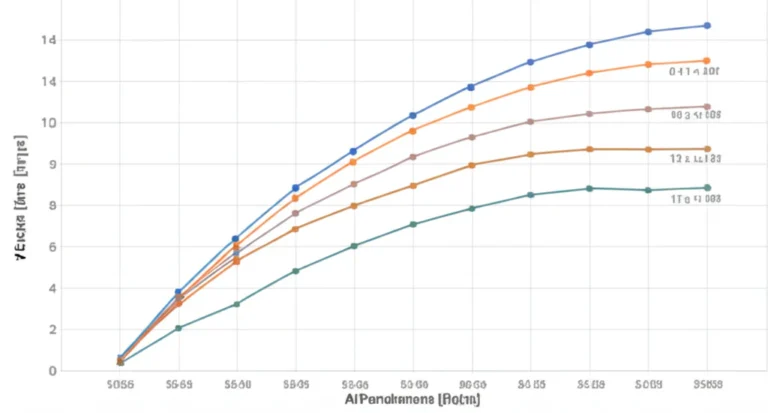
Why does a computer vision model that scores 9% on ImageNet crumble when it sees a fogy street, while a speech model that flawlessly transcribes audiobooks fails to hear a whisper in a crowded bar? The answer lies in the…