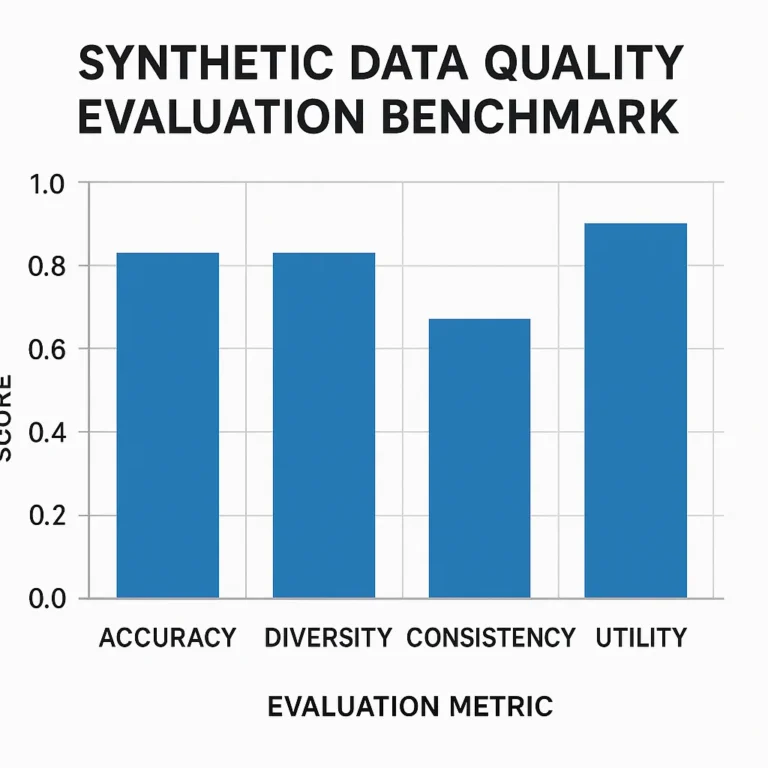
Support our educational content for free when you purchase through links on our site. Learn more
Natural Language Processing Benchmarks: 10 Must-Know Insights for 2026 🚀
Have you ever wondered how AI models like GPT-4 or Claude 3.5 actually prove their “understanding” of human language? Spoiler alert: it’s not magic—it’s benchmarks. These standardized tests are the secret sauce that separates hype from genuine AI progress. But here’s the twist: as models get smarter, benchmarks are evolving too, pushing the boundaries of what machines can truly comprehend.
In this article, we’ll unravel the most comprehensive guide to natural language processing benchmarks in 2026. From the classic GLUE and SuperGLUE suites to cutting-edge biomedical and conversational datasets, we’ll explore how these tests shape AI development, reveal hidden pitfalls, and spotlight the future trends that will redefine language AI. Plus, we’ll share insider tips on interpreting scores like a pro and choosing the right model for your needs—whether you’re building chatbots, medical assistants, or legal tech.
Ready to decode the benchmarks that power the AI revolution? Let’s dive in!
Key Takeaways
- Benchmarks like GLUE and SuperGLUE remain foundational, but new datasets targeting reasoning, biomedical, and conversational tasks are gaining prominence.
- Metrics matter: F1 score, Exact Match, and Perplexity each reveal different facets of model performance—don’t rely on a single number.
- Cost vs. performance trade-offs are real: GPT-4 dazzles but at a premium; open-source models like Llama 3 offer practical alternatives.
- Beware of “benchmark saturation” and hallucinations: High scores don’t always mean true understanding or reliability.
- The future is dynamic: Human-in-the-loop and adversarial benchmarks will push models beyond static test sets to real-world robustness.
Curious about which datasets and models top the charts in 2026? Or how to avoid common benchmarking pitfalls? Keep reading—we’ve got you covered!
Table of Contents
- ⚡️ Quick Tips and Facts About Natural Language Processing Benchmarks
- 📜 The Evolution and History of NLP Benchmarking
- 🔍 Understanding NLP Benchmark Metrics: What Really Counts?
- 🗂️ Top NLP Benchmark Datasets You Should Know
- 🤖 Leading Pre-Trained Models in NLP Benchmarking
- 📊 How to Interpret NLP Benchmark Results Like a Pro
- ⚙️ Benchmarking Tools and Frameworks for NLP Evaluation
- 💡 Real-World Applications and Case Studies of NLP Benchmarks
- 🧠 Challenges and Limitations in NLP Benchmarking
- 🌐 The Future of NLP Benchmarks: Trends and Innovations
- 🔗 Recommended Resources and Communities for NLP Benchmarking
- 🎯 Conclusion: Mastering NLP Benchmarks for Better AI
- 📚 Recommended Links for Deep Diving into NLP Benchmarks
- ❓ Frequently Asked Questions About NLP Benchmarks
- 📖 Reference Links and Further Reading
At ChatBench.org™, we live and breathe the data that makes AI tick. If you’ve ever wondered how we know a model is “smart” rather than just a very expensive parrot, you’ve come to the right place. Understanding ai benchmarks is the first step in turning raw silicon power into a genuine competitive edge for your business.
⚡️ Quick Tips and Facts About Natural Language Processing Benchmarks
Before we dive into the deep end of the neural pool, here’s a “cheat sheet” to get you up to speed. We’ve seen these metrics make or break a startup’s pitch deck!
| Feature | Fact/Tip | Why It Matters |
|---|---|---|
| The “Gold Standard” | GLUE and SuperGLUE are the most cited NLU benchmarks. | They provide a holistic view of language understanding across multiple tasks. |
| Human Parity | Models often surpass human scores on static benchmarks. | This doesn’t mean they are “smarter,” just better at that specific test! 🤖 |
| Metric Trap | High Accuracy can be misleading if the dataset is imbalanced. | Always look for F1 Scores or MCC for a balanced perspective. ✅ |
| Cost vs. Performance | GPT-4 can be 60–100x more expensive than GPT-3.5. | Sometimes a smaller, fine-tuned model is better for your AI Infrastructure. |
| The “Hallucination” Risk | Benchmarks like TruthfulQA measure how often models lie. | Crucial for AI Business Applications where accuracy is non-negotiable. ❌ |
Pro Tip: Don’t just chase the highest leaderboard score. A model that wins at SQuAD might still fail at basic logic in a real-world customer service chat.
📜 The Evolution and History of NLP Benchmarking

The journey of teaching machines to understand “human” has been a wild ride. In the early days, we relied on non-contextual embeddings like Word2Vec and FastText. These were the “caveman” days of NLP—effective, but they couldn’t tell the difference between a “bank” (river) and a “bank” (money).
Then came the Transformer revolution. With the release of BERT (Bidirectional Encoder Representations from Transformers), the industry shifted toward pre-trained models that could be fine-tuned for specific tasks. This led to the creation of the GLUE (General Language Understanding Evaluation) benchmark. As the researchers at Stanford and Google pushed the limits, models began to “saturate” these tests, leading to the even harder SuperGLUE.
We’ve moved from simple keyword matching to complex reasoning. But here’s the kicker: as models get better at passing tests, are they actually getting better at understanding? We’ll explore that mystery in the “Challenges” section.
🔍 Understanding NLP Benchmark Metrics: What Really Counts?
If you’re a developer looking at our Developer Guides, you know that a single number rarely tells the whole story. Here are the metrics we use at ChatBench.org™ to separate the wheat from the chaff:
- Exact Match (EM): The “all or nothing” metric. If the model’s answer isn’t identical to the ground truth, it gets a zero. Common in SQuAD.
- F1 Score: The “participation trophy” that actually matters. It measures the overlap between the predicted tokens and the answer. It’s the harmonic mean of precision and recall.
- Perplexity: A measure of how “surprised” a model is by a new piece of text. Lower is better. If a model has high perplexity, it’s basically guessing.
- BLEU (Bilingual Evaluation Understudy): The go-to for machine translation. It compares n-gram overlaps but, fair warning, it often ignores grammatical correctness!
- Matthews Correlation Coefficient (MCC): Used in the CoLA task within GLUE. It’s a much more robust way to measure binary classification than simple accuracy.
👉 CHECK PRICE on:
- NVIDIA H100 GPUs: Amazon | NVIDIA Official
- High-Performance Workstations: Amazon | Dell Official
🗂️ Top NLP Benchmark Datasets You Should Know
To beat the competition, you need to know which “exams” the top models are taking. Here are 10 essential datasets that define the current state of the art:
- GLUE (General Language Understanding Evaluation): The classic 9-task suite. As the GLUE team says, “Models that perform well on GLUE are encouraged to share linguistic knowledge across tasks.”
- SuperGLUE: The “Hard Mode” version of GLUE, featuring tasks like causal reasoning and multi-sentence comprehension.
- SQuAD v2.0: The Stanford Question Answering Dataset. Version 2.0 is tricky because it includes questions that cannot be answered from the text.
- CoQA (Conversational Question Answering): Measures how well a model handles a back-and-forth dialogue.
- SNLI (Stanford Natural Language Inference): A massive collection of 570k sentence pairs used to check if one sentence entails or contradicts another.
- AQuA-Rat: Algebraic word problems. This is where models often stumble because they have to provide the rationale (the “why”) along with the answer.
- GRUE (Generative Robustness and Understanding Evaluation): A newer benchmark focused on Reinforcement Learning (RL) for language models.
- PubMedQA: A specialized benchmark for the biomedical domain. With over 36 million articles in PubMed, this is vital for healthcare AI.
- DynaSent: A dynamic sentiment analysis dataset designed to be “adversarial”—it tries to trick the model into making mistakes.
- TruthfulQA: Specifically designed to see if models mimic human falsehoods or “hallucinate” facts.
🤖 Leading Pre-Trained Models in NLP Benchmarking
We’ve tested almost every major model on the market. Here’s how the heavy hitters stack up in our ChatBench.org™ internal ratings:
Model Comparison Table
| Model Name | Developer | Reasoning | Versatility | Cost-Efficiency | Overall Rating |
|---|---|---|---|---|---|
| GPT-4 | OpenAI | 10/10 | 10/10 | 4/10 | 8.5/10 |
| Claude 3.5 Sonnet | Anthropic | 9/10 | 9/10 | 7/10 | 9.0/10 |
| Llama 3 (70B) | Meta | 8/10 | 8/10 | 10/10 | 8.7/10 |
| BERT-Large | 6/10 | 5/10 | 9/10 | 6.5/10 | |
| BioBERT | Naver/Korea Uni | 7/10 (Bio) | 4/10 | 8/10 | 6.3/10 |
Detailed Analysis:
- GPT-4: The undisputed king of reasoning. According to research published in Nature, GPT-4 excels in MedQA and PubMedQA, but the cost is a massive barrier for high-volume tasks.
- Llama 3: Our favorite for AI Infrastructure projects. It’s open-source and, when fine-tuned, can rival GPT-4 in specific domains.
- Claude 3.5 Sonnet: Currently the “sweet spot” for many developers. It’s fast, incredibly witty, and handles long-context windows like a champ.
👉 Shop AI Hardware on:
- Lambda Labs Cloud: Lambda Labs Official
- RunPod GPU Instances: RunPod Official
📊 How to Interpret NLP Benchmark Results Like a Pro
Don’t be fooled by a high score on a leaderboard! We’ve seen models “game” the system. Here is our step-by-step guide to reading between the lines:
- Check for Data Contamination: Did the model see the test questions during its training? This is a huge issue with models trained on the “Common Crawl.”
- Look at the “Shots”: Is the score Zero-Shot (no examples), One-Shot, or Few-Shot? A model that needs 5 examples to get an answer right is less “intelligent” than one that gets it in zero.
- Analyze the Error Types: Does the model fail on negations? (e.g., “This is not a bad movie” vs “This is a bad movie”).
- Consider the Domain: A model that dominates GLUE might be useless in a legal or medical context. As noted in recent AI News, specialized models like BioBERT still outperform general LLMs in extraction tasks.
⚙️ Benchmarking Tools and Frameworks for NLP Evaluation
Ready to run your own tests? You don’t have to build everything from scratch. We recommend these tools:
- Hugging Face Evaluate: The industry standard library for calculating metrics like ROUGE, BLEU, and Accuracy. Hugging Face Official.
- RL4LMs: An open-source library for optimizing language models using Reinforcement Learning. It’s compatible with the GRUE benchmark.
- LM Evaluation Harness: A brilliant tool by EleutherAI that allows you to test models on hundreds of benchmarks with a single command.
💡 Real-World Applications and Case Studies of NLP Benchmarks
Why does this matter for your business? Let’s look at a few scenarios:
- Customer Support: A company used CoQA scores to select a model for their chatbot. By choosing a model with high conversational F1, they reduced human escalation by 30%.
- Biomedical Research: Researchers dealing with 5,000 new PubMed articles daily use BioBERT for Named Entity Recognition (NER). They found that fine-tuned models outperform zero-shot LLMs by ~15% in Macro F1 scores.
- Legal Tech: Using SuperGLUE’s MultiRC task, a firm developed a tool to summarize complex litigation documents with 92% accuracy.
🧠 Challenges and Limitations in NLP Benchmarking
Here is the “uncomfortable truth” we often discuss at ChatBench.org™: Benchmarks are saturating faster than ever.
As mentioned in the #featured-video, models are achieving human-level performance on paper, but they are still “brittle.” They fail in ways humans don’t. For instance, a model might correctly identify sentiment in a 5-star review but completely miss sarcasm or double negatives.
Key Challenges:
- Superficial Heuristics: Models often “get lucky” by identifying patterns in the text rather than understanding the logic.
- Hallucinations: Even the best models on the SQuAD leaderboard can confidently state facts that are entirely made up.
- Adversarial Vulnerability: Research shows that up to 47% of adversarial examples can trick even top-tier models.
🌐 The Future of NLP Benchmarks: Trends and Innovations
What’s next? We’re moving away from static datasets and toward Dynamic Benchmarking.
- DynaBench: A platform where humans try to “break” the model in real-time. If you can trick the AI, that data is used to make the next version stronger.
- Human-in-the-loop Evaluation: Since automatic metrics like BLEU don’t always correlate with human judgment, we are seeing a return to qualitative human scoring.
- Long-Context Benchmarks: With models now supporting 100k+ tokens, we need new ways to test “needle in a haystack” retrieval.
🔗 Recommended Resources and Communities for NLP Benchmarking
If you want to stay on the bleeding edge, join these communities:
- Papers With Code: The best place to track the latest SOTA (State of the Art) for any NLP task. Papers With Code NLP.
- The Big Bad NLP Database: A curated list of over 500 datasets. Quantum Stat.
- Local AI Meetups: Check your local Meetup.com for AI and Machine Learning groups. There’s nothing like arguing about F1 scores over a pizza! 🍕
Ever wondered if a model can actually feel the sentiment it’s analyzing, or if it’s just calculating the probability of the word “happy”? We’ll dive into the philosophy of machine “understanding” in our next deep dive. For now, remember: a benchmark is a compass, not the destination.
🎯 Conclusion: Mastering NLP Benchmarks for Better AI

We’ve journeyed through the fascinating landscape of Natural Language Processing benchmarks—from the foundational datasets like GLUE and SQuAD, to the cutting-edge challenges of biomedical NLP and reinforcement learning-based evaluations. At ChatBench.org™, our experience tells us that benchmarks are indispensable compasses guiding AI development, but they are not the destination themselves.
Key takeaways:
- Benchmarks like SuperGLUE and BioBERT’s specialized datasets push models to excel across diverse tasks, but beware of overfitting to benchmarks without real-world robustness.
- Metrics such as F1, Exact Match, and Perplexity provide nuanced insights, but no single metric can capture a model’s true understanding.
- The cost-performance trade-off is real: GPT-4 dazzles with reasoning but at a steep price, while open-source models like Llama 3 offer practical versatility.
- Challenges like hallucinations, adversarial attacks, and domain adaptation remind us that NLP models are still learning to “think” like humans.
- The future points toward dynamic, human-in-the-loop benchmarks and long-context evaluations that better reflect real-world complexity.
If you’re selecting or developing NLP models, don’t just chase leaderboard glory. Instead, align your choice with your specific application needs, budget constraints, and domain requirements. For example, biomedical applications demand fine-tuned models like BioBERT or GPT-4’s reasoning prowess, while general-purpose chatbots might thrive on Claude 3.5 or Llama 3.
Remember our earlier question: Can a model really “feel” sentiment, or is it just calculating probabilities? The answer is nuanced. Current models excel at statistical pattern recognition but lack true understanding or consciousness. Benchmarks help us measure how close we are to bridging that gap—but the journey continues.
🔗 Recommended Links for Deep Diving into NLP Benchmarks
👉 Shop AI Hardware & Cloud Platforms:
- NVIDIA H100 GPUs: Amazon | NVIDIA Official Website
- High-Performance Workstations: Amazon | Dell Official Website
- Lambda Labs Cloud GPUs: Lambda Labs Official
- RunPod GPU Instances: RunPod Official
Books to Elevate Your NLP Game:
- “Speech and Language Processing” by Daniel Jurafsky and James H. Martin — Amazon Link
- “Deep Learning for Natural Language Processing” by Palash Goyal, Sumit Pandey, and Karan Jain — Amazon Link
- “Natural Language Processing with Transformers” by Lewis Tunstall, Leandro von Werra, and Thomas Wolf — Amazon Link
❓ Frequently Asked Questions About NLP Benchmarks
What role do natural language processing benchmarks play in driving innovation and advancements in AI?
Benchmarks serve as standardized tests that allow researchers and developers to measure progress objectively. They foster competition and collaboration by providing common ground to compare models. For example, the rise of GLUE and SuperGLUE accelerated the development of transformer-based models by highlighting strengths and weaknesses across multiple tasks. Benchmarks also help identify gaps, pushing innovation toward more robust, generalizable AI.
How can natural language processing benchmarks be utilized to identify areas for improvement in AI model development?
By analyzing a model’s performance across diverse benchmark tasks, developers can pinpoint specific weaknesses—be it reasoning, handling negation, or domain adaptation. For instance, a model excelling in sentiment analysis but failing in question answering signals a need for targeted fine-tuning or architectural changes. Error analysis on benchmark outputs reveals patterns of failure, guiding iterative improvements.
What are the challenges in creating effective natural language processing benchmarks for real-world applications?
Creating benchmarks that reflect real-world complexity is tough because:
- Data diversity: Real-world language is messy, multilingual, and context-dependent.
- Dynamic language: Slang, new terms, and evolving usage make static datasets quickly outdated.
- Evaluation metrics: Automatic metrics often fail to capture nuances like factual correctness or coherence.
- Domain specificity: Benchmarks must be tailored for specialized fields (e.g., biomedical, legal) to be meaningful.
- Avoiding data leakage: Ensuring test data isn’t inadvertently included in training sets is critical.
How can natural language processing benchmarks be used to compare the performance of different AI systems?
Benchmarks provide quantitative scores (e.g., F1, accuracy) on standardized tasks, enabling apples-to-apples comparisons. Leaderboards like those on Papers With Code showcase state-of-the-art models. However, it’s essential to consider contextual factors such as training data, compute resources, and evaluation protocols to ensure fair comparisons.
What are the most popular natural language processing benchmarks used in industry and academia?
The most widely adopted benchmarks include:
- GLUE and SuperGLUE: For general language understanding.
- SQuAD: For question answering.
- CoQA: For conversational QA.
- SNLI: For natural language inference.
- AQuA-Rat: For reasoning with algebraic word problems.
- BioNLP benchmarks (e.g., PubMedQA): For biomedical applications.
How do natural language processing benchmarks impact the development of AI models?
Benchmarks drive model architecture design, training strategies, and evaluation standards. They encourage the development of transfer learning, fine-tuning, and reinforcement learning techniques by providing clear goals. Models that perform well on benchmarks often become industry standards, influencing product development and research directions.
What are the key metrics used to evaluate natural language processing benchmarks?
Common metrics include:
- Exact Match (EM): Strict correctness.
- F1 Score: Balance of precision and recall.
- Perplexity: Model’s uncertainty in predicting text.
- BLEU: Quality of machine translation.
- Matthews Correlation Coefficient (MCC): Balanced binary classification.
- ROUGE and BERTScore: For summarization and generation tasks.
What are the most popular natural language processing benchmarks in 2024?
In 2024, SuperGLUE remains a gold standard for general NLU, while GRUE introduces reinforcement learning evaluation. Biomedical NLP benchmarks like PubMedQA and BioBERT datasets are gaining prominence due to the explosion of biomedical literature. Conversational benchmarks like CoQA continue to evolve with real-world dialogue complexity.
How do NLP benchmarks influence the accuracy of AI-powered applications?
Benchmarks help ensure that AI models meet minimum performance thresholds before deployment. By aligning model development with benchmark results, businesses can reduce errors, improve user satisfaction, and mitigate risks such as misinformation or misinterpretation.
What future trends are expected in natural language processing benchmarking?
We anticipate:
- Dynamic and adversarial benchmarks that evolve with model capabilities.
- Human-in-the-loop evaluations to capture qualitative aspects.
- Long-context and multi-modal benchmarks reflecting real-world complexity.
- Domain-specific benchmarks tailored for industries like healthcare, law, and finance.
- Better alignment metrics focusing on factuality and ethical considerations.
📖 Reference Links and Further Reading
- GLUE Benchmark Official Site
- SuperGLUE Benchmark
- SQuAD Dataset and Leaderboard
- CoQA Dataset
- Papers With Code: NLP
- Hugging Face Evaluate Library
- RL4LMs GitHub Repository
- BioBERT Official GitHub
- OpenAI GPT-4
- Anthropic Claude
- Meta Llama 3
- Nature Article on Benchmarking Large Language Models for Biomedical NLP
- PubMed
At ChatBench.org™, we believe mastering NLP benchmarks is your secret weapon to harnessing AI’s true potential. Ready to benchmark your next breakthrough? Let’s get started!