Support our educational content for free when you purchase through links on our site. Learn more
How Do I Measure AI Model Accuracy in Real-World Applications? 🔍 (2026)
Measuring the accuracy of your AI model in real-world scenarios is like trying to hit a moving target in a foggy forest—tricky, but absolutely essential. At ChatBench.org™, we’ve witnessed firsthand how models that boast stellar accuracy in the lab can falter spectacularly once deployed. Why? Because accuracy isn’t just a number; it’s a story with many chapters—from the choice of metrics to data quality, from model drift to ethical considerations.
In this article, we’ll unravel the mystery behind AI accuracy measurement, going beyond the simple percentage scores to explore precision, recall, F1 scores, and the critical role of continuous monitoring. Curious how companies like Microsoft leverage observability tools to keep their AI honest? Or how you can detect subtle biases before they cause real harm? Stick around, because by the end, you’ll be equipped to measure your AI model’s true effectiveness in the wild—and avoid costly pitfalls.
Key Takeaways
- Accuracy alone can be misleading—especially with imbalanced or biased data.
- Precision, recall, and F1 score provide a fuller picture of model performance tailored to your use case.
- Continuous monitoring and drift detection are essential for maintaining accuracy post-deployment.
- Human expertise and ethical oversight complement metrics to ensure fairness and trustworthiness.
- Real-world AI evaluation requires a multi-metric, context-aware approach to truly measure success.
Ready to transform your AI evaluation from guesswork to mastery? Let’s dive in!
Table of Contents
- ⚡️ Quick Tips and Facts on Measuring AI Model Accuracy
- 🔍 Understanding AI Model Accuracy: A Data-Driven Background
- 📊 Key Metrics to Measure AI Model Accuracy in Real-World Applications
- 🛠️ Tools and Frameworks for Evaluating AI Model Accuracy
- 🌐 Challenges of Measuring AI Accuracy in Real-World Scenarios
- 🔄 Continuous Monitoring and Model Drift Detection: Keeping AI Honest
- 💡 Best Practices for Validating AI Models Before Deployment
- ⚠️ Real-World Consequences of Inaccurate AI Models
- 🎯 Critical Factors for a True Assessment of AI Model Accuracy
- 🧩 Integrating User Feedback and Domain Expertise in Accuracy Measurement
- 📈 Case Studies: How Top Companies Measure AI Model Accuracy
- 🔧 Troubleshooting Common Pitfalls in AI Accuracy Evaluation
- 📚 Recommended Reading and Resources for AI Model Evaluation
- 📝 Conclusion: Mastering AI Model Accuracy in the Wild
- 🔗 Recommended Links for Further Exploration
- ❓ Frequently Asked Questions (FAQ) About AI Model Accuracy
- 📑 Reference Links and Citations
⚡️ Quick Tips and Facts on Measuring AI Model Accuracy
Welcome to the wild world of AI, where numbers tell a story, but not always the whole truth! At ChatBench.org™, we’ve seen countless models shine in the lab only to stumble in the real world. Why? Because measuring AI model accuracy isn’t just about a single number; it’s a nuanced art and science. If you’re looking to truly understand how to evaluate AI model performance beyond the basics, you’ve come to the right place. We’ll dive deep into key benchmarks for evaluating AI model performance and ensure your AI isn’t just “accurate” but genuinely effective.
Here are some rapid-fire insights from our trenches:
- Accuracy is a Liar (Sometimes!): Don’t get fooled by a high accuracy score, especially with imbalanced datasets. A model predicting “no disease” 99% of the time in a population where only 1% has the disease will have 99% accuracy, but it’s utterly useless! ❌
- Context is King 👑: The “best” metric depends entirely on your application. Is it critical to avoid false positives (e.g., flagging a healthy person as sick)? Or false negatives (e.g., missing a cancerous tumor)? Your answer dictates your focus.
- Beyond the Lab: Real-world data is messy, dynamic, and full of surprises. Model drift and data shift are your biggest enemies post-deployment. Continuous monitoring isn’t optional; it’s essential. ✅
- Human-in-the-Loop: AI isn’t a silver bullet. Integrating domain expertise and user feedback is crucial for a holistic understanding of performance and identifying subtle failures that metrics alone might miss.
- Bias Bites Back: Even highly accurate models can perpetuate and amplify existing societal biases if trained on skewed data. Fairness metrics and bias detection are non-negotiable.
🔍 Understanding AI Model Accuracy: A Data-Driven Background

Remember the early days of machine learning? Simpler times, right? We’d train a model, get an accuracy score of 90%, and high-five each other. “Nailed it!” we’d exclaim. But as AI moved from academic papers to real-world applications—from predicting stock prices to diagnosing diseases—we quickly learned that accuracy is a far more complex beast than it appears.
At its core, AI model accuracy refers to how well an AI system’s predictions or classifications align with the actual, known outcomes in a given dataset. It’s a fundamental measure of a model’s correctness. However, as the experts at UNU.edu wisely point out, there’s a critical distinction: “Accuracy in AI refers to aligning predictions with a given set of data or expected outcomes. It is a technical measure, quantifiable and concrete.” But here’s the kicker: “AI accuracy is not necessarily the truth!” (UNU.edu).
This isn’t just semantics; it’s a profound insight. A model can be “accurate” in predicting a pattern it learned from historical data, but if that data was biased or incomplete, its predictions might be far from the “truth” of the real world. For instance, an AI trained on historical hiring data might accurately predict who was hired in the past, but if that past data showed a bias against certain demographics, the AI will perpetuate that bias, regardless of its statistical accuracy. Amazon famously had to scrap an AI recruiting tool because it showed bias against women, simply because it was trained on historical data from a male-dominated tech industry (Reuters). The model was “accurate” in replicating past hiring patterns, but it certainly wasn’t “truthful” or fair.
This realization has pushed the field of machine learning engineering to evolve beyond simple accuracy percentages. We now understand the need for a more holistic approach to AI model evaluation, incorporating a suite of metrics, continuous monitoring, and a deep understanding of the problem domain. The journey from “accuracy is enough” to “accuracy is just one piece of the puzzle” has been a bumpy but enlightening one for us at ChatBench.org™. It’s why we emphasize data-driven validation and ethical AI development in all our projects.
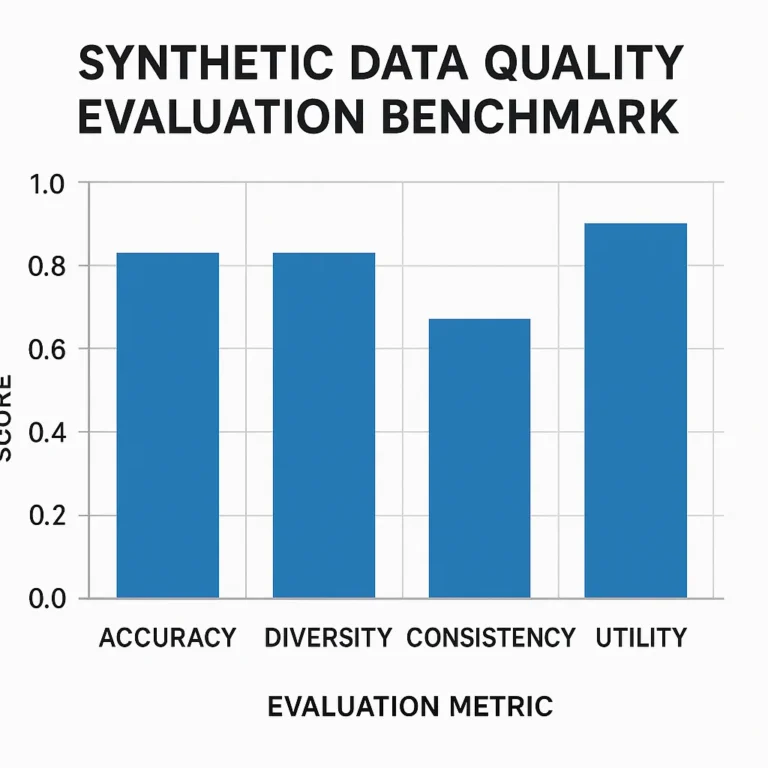
📊 Key Metrics to Measure AI Model Accuracy in Real-World Applications
Alright, let’s get down to brass tacks. If you’re still relying solely on a single “accuracy” percentage, you’re missing a huge chunk of the story. As the first YouTube video on “How do I measure the accuracy of my AI model in real-world applications?” emphatically states, “Accuracy is not the only measure of an AI model’s performance.” We need a richer vocabulary to describe how our models are truly performing, especially when the stakes are high.
Think of it like a doctor diagnosing a patient. They don’t just look at one symptom; they consider a whole range of indicators. Similarly, evaluating an AI model requires a suite of metrics to understand its strengths, weaknesses, and potential pitfalls. The PMC article on AI in healthcare highlights this, noting that “Rigorous assessment helps identify strengths, weaknesses, and areas for improvement, ultimately enhancing the reliability of AI-based healthcare solutions.” (PMC).
Here are the essential metrics we use at ChatBench.org™ to get a comprehensive view of our AI models in action:
1. Accuracy, Precision, Recall, and F1 Score Explained
These four metrics are the bread and butter of classification model evaluation. They help us understand different facets of a model’s performance, especially when dealing with imbalanced datasets or when certain types of errors are more costly than others.
-
Accuracy:
- What it is: The proportion of total predictions that were correct.
- Formula: (True Positives + True Negatives) / Total Predictions
- When to use: Good for balanced datasets where false positives and false negatives have similar costs.
- Drawback: Can be misleading with imbalanced classes. If 95% of emails are not spam, a model that always predicts “not spam” will have 95% accuracy but miss all spam.
-
Precision:
- What it is: Of all the positive predictions made by the model, how many were actually correct? It measures the quality of positive predictions.
- Formula: True Positives / (True Positives + False Positives)
- When to use: Crucial when the cost of a False Positive is high. Imagine an AI flagging a healthy person for a serious disease – high precision minimizes these costly mistakes.
- Analogy: “When the model says it’s positive, how sure are you it really is?”
-
Recall (Sensitivity):
- What it is: Of all the actual positive cases, how many did the model correctly identify? It measures the model’s ability to find all positive instances.
- Formula: True Positives / (True Positives + False Negatives)
- When to use: Critical when the cost of a False Negative is high. For example, in cancer detection, missing a cancerous tumor (a false negative) is far more dangerous than a false positive.
- Analogy: “Of all the actual positives out there, how many did the model catch?”
-
F1 Score:
- What it is: The harmonic mean of Precision and Recall. It provides a single score that balances both metrics.
- Formula: 2 * (Precision * Recall) / (Precision + Recall)
- When to use: Ideal when you need a balance between Precision and Recall, especially with uneven class distribution. It’s a great go-to metric when you can’t decide which error type is strictly worse.
- Why harmonic mean? It penalizes extreme values more heavily, so a low precision or low recall will result in a low F1 score.
Let’s visualize this with a quick comparison table:
| Metric | Focus | Best for Scenarios Where… | Potential Pitfall
📝 Conclusion: Mastering AI Model Accuracy in the Wild

Phew! What a journey through the labyrinth of AI model accuracy. If you’ve stuck with us, you now know that measuring AI accuracy in real-world applications is far from a simple checkbox exercise. It’s a multi-dimensional challenge that demands a blend of technical rigor, domain expertise, and ethical mindfulness.
Here’s the bottom line from the AI researchers and machine-learning engineers at ChatBench.org™:
- Accuracy alone is not enough. It’s a starting point, but without precision, recall, F1 score, and other metrics, you’re flying blind.
- Context is everything. The “best” metric depends on your use case — whether it’s healthcare, finance, or customer service.
- Real-world data is messy and dynamic. Continuous monitoring and observability tools like those from Microsoft Azure AI Foundry are essential to catch model drift and maintain trustworthiness.
- Human judgment remains critical. AI should augment, not replace, domain experts who can interpret nuanced failures and ethical implications.
- Beware of bias and data limitations. Even the most “accurate” model can perpetuate harmful biases if trained on skewed data.
By combining rigorous validation strategies, continuous evaluation, and ethical oversight, you can ensure your AI models don’t just perform well on paper but deliver real value and fairness in the wild.
If you’re curious about tools to help you on this journey, consider exploring Microsoft Azure AI Foundry’s observability features or open-source frameworks like TensorBoard and MLflow for monitoring and evaluation.
So, next time you see a shiny accuracy score, ask yourself: Is this model truly telling the whole story? If not, now you know how to dig deeper.
🔗 Recommended Links for Further Exploration
Ready to level up your AI evaluation toolkit? Check out these top resources and products:
-
Microsoft Azure AI Foundry Observability:
Microsoft Azure AI Foundry Observability -
MLflow (Open-source ML lifecycle platform):
MLflow on Amazon -
TensorBoard (TensorFlow’s visualization toolkit):
TensorBoard Official Site -
Books on AI Model Evaluation and Ethics:
- “Interpretable Machine Learning” by Christoph Molnar — Amazon Link
- “Fairness and Machine Learning” by Solon Barocas et al. — Amazon Link
- “Machine Learning Yearning” by Andrew Ng — Amazon Link
-
👉 Shop AI Infrastructure Platforms:
- Microsoft Azure: Azure AI Services
- Amazon Web Services (AWS): AWS Machine Learning
- Google Cloud AI: Google Cloud AI Platform
❓ Frequently Asked Questions (FAQ) About AI Model Accuracy
 About AI Model Accuracy by ChatBench.org")
What role does data quality play in measuring the accuracy of AI models, and how can I ensure that my data is reliable and relevant?
Data quality is the foundation of any trustworthy AI model. Poor data quality—such as missing values, incorrect labels, or unrepresentative samples—can lead to misleading accuracy metrics and biased predictions. To ensure reliability:
- Clean and preprocess your data thoroughly. Remove duplicates, handle missing values, and standardize formats.
- Use diverse and representative datasets. Avoid training on data that overrepresents or underrepresents certain groups or scenarios.
- Validate labels rigorously. For supervised learning, ensure labels are accurate and consistent, possibly through expert review or consensus.
- Continuously update datasets. Real-world data evolves; keep your training and validation sets fresh to reflect current realities.
At ChatBench.org™, we always emphasize data governance and quality assurance as the first step before any model evaluation.
What are the key challenges in measuring the accuracy of AI models in real-world applications, and how can they be addressed?
Several challenges complicate real-world accuracy measurement:
- Data drift and concept drift: The statistical properties of input data or target concepts may change over time, degrading model performance.
- Imbalanced datasets: Many real-world problems have skewed class distributions, making accuracy misleading.
- Bias and fairness issues: Historical biases in data can cause models to perform unevenly across demographics.
- Lack of ground truth: In some domains, true labels are unavailable or expensive to obtain.
- Complexity of multi-modal data: Combining text, images, and sensor data complicates evaluation.
Addressing these requires:
- Continuous monitoring and observability tools (e.g., Azure AI Foundry) to detect drift early.
- Using appropriate metrics like precision, recall, and AUC instead of accuracy alone.
- Incorporating fairness audits and bias detection frameworks.
- Active learning and human-in-the-loop systems to gather new labels and feedback.
- Robust validation strategies including cross-validation and testing on diverse datasets.
How can I ensure that my AI model generalizes well to new, unseen data in real-world applications?
Generalization is the holy grail of AI. To improve it:
- Use diverse and representative training data that captures the variability of real-world scenarios.
- Avoid overfitting by employing regularization techniques, dropout, or early stopping during training.
- Validate your model on separate test sets and real-world data before deployment.
- Perform cross-validation to assess stability across different data splits.
- Monitor model performance post-deployment to detect degradation and retrain as necessary.
- Leverage domain knowledge to engineer meaningful features and constraints.
Remember, a model that performs well in the lab but poorly in production is a costly mistake.
What metrics are most effective for evaluating the performance of AI models in real-world scenarios?
The choice depends on your application, but generally:
- Classification tasks: Precision, recall, F1 score, ROC-AUC, confusion matrix.
- Regression tasks: Mean Squared Error (MSE), Mean Absolute Error (MAE), R-squared.
- Ranking tasks: Mean Average Precision (MAP), Normalized Discounted Cumulative Gain (NDCG).
- Fairness and bias: Demographic parity, equalized odds, disparate impact.
- Robustness: Performance under adversarial or noisy inputs.
Combining multiple metrics provides a fuller picture. For example, in healthcare, high recall (sensitivity) is often prioritized to avoid missing critical cases, while in spam detection, precision is key to avoid false alarms.
How can I validate my AI model’s predictions with live data?
Validating with live data involves:
- Shadow testing: Run the model alongside existing systems without affecting decisions to compare outputs.
- A/B testing: Deploy the model to a subset of users and compare outcomes against a control group.
- Feedback loops: Collect user feedback or expert reviews on model predictions to identify errors.
- Monitoring key performance indicators (KPIs): Track metrics like accuracy, latency, and error rates in production.
- Automated alerts: Set thresholds for performance drops and trigger retraining or human review.
This continuous validation ensures your model adapts and stays reliable in dynamic environments.
What are common challenges in measuring AI accuracy outside of training data?
Outside training data, challenges include:
- Data distribution shifts: New data may differ significantly from training data.
- Label scarcity: Ground truth may be unavailable or delayed.
- Unseen edge cases: Rare or novel inputs can cause unpredictable behavior.
- Operational constraints: Real-time requirements or limited compute resources affect evaluation.
- Ethical and legal considerations: Privacy laws may restrict data access for validation.
Mitigation strategies involve robust monitoring, active learning, simulated testing environments, and ethical data management.
How do I interpret AI model accuracy to improve business decision-making?
Accuracy metrics are tools, not answers. To leverage them effectively:
- Align metrics with business goals. For example, if false negatives cost more than false positives, prioritize recall.
- Translate technical metrics into business impact. Quantify how improved model performance affects revenue, customer satisfaction, or risk.
- Use visualizations and dashboards to communicate model health to stakeholders.
- Incorporate qualitative feedback from users to complement quantitative metrics.
- Iterate and experiment. Use insights from accuracy analysis to refine models and strategies.
At ChatBench.org™, we help businesses bridge the gap between AI metrics and actionable insights, turning data into competitive advantage.
How important is explainability in measuring AI model accuracy?
Explainability helps stakeholders understand why a model makes certain predictions, which is critical for trust and compliance. Techniques like SHAP and LIME reveal feature importance and decision pathways, complementing accuracy metrics by highlighting model behavior and potential biases.
Can I rely solely on accuracy metrics for high-stakes AI applications?
❌ No. High-stakes domains like healthcare, finance, or criminal justice require multi-faceted evaluation including fairness, robustness, interpretability, and ethical considerations. Accuracy is necessary but insufficient.
What role does continuous monitoring play in maintaining AI accuracy?
Continuous monitoring detects model drift, data anomalies, and performance degradation in real time, enabling timely interventions. Without it, models can silently fail, causing costly errors.
Are there industry standards or frameworks for AI model evaluation?
Yes. Organizations like NIST, ISO, and IEEE are developing AI evaluation frameworks emphasizing transparency, fairness, and robustness. Microsoft’s AI Foundry observability tools align with these principles, supporting lifecycle-wide evaluation.
📑 Reference Links and Citations
-
UNU Centre for Policy Research, “Never Assume Accuracy of AI Information Equals Truth”
https://unu.edu/article/never-assume-accuracy-artificial-intelligence-information-equals-truth -
National Center for Biotechnology Information (NCBI), “How to measure the accuracy of AI models in healthcare”
https://pmc.ncbi.nlm.nih.gov/articles/PMC11047988/ -
Microsoft Azure AI Foundry, “Observability in Generative AI”
https://learn.microsoft.com/en-us/azure/ai-foundry/concepts/observability?view=foundry-classic -
Reuters, “Amazon scraps secret AI recruiting tool after it showed bias against women”
https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-after-it-showed-bias-against-women-idUSKCN1MK08G -
TensorFlow, “TensorBoard”
https://www.tensorflow.org/tensorboard -
MLflow, “Open Source Platform for the Machine Learning Lifecycle”
https://mlflow.org/ -
Christoph Molnar, “Interpretable Machine Learning” (Book)
https://christophm.github.io/interpretable-ml-book/ -
Solon Barocas et al., “Fairness and Machine Learning” (Book)
https://fairmlbook.org/ -
Andrew Ng, “Machine Learning Yearning” (Book)
https://www.mlyearning.org/
Thank you for joining us on this deep dive! For more insights on AI Business Applications and AI Infrastructure, keep exploring ChatBench.org™ — where we turn AI insight into your competitive edge.