Support our educational content for free when you purchase through links on our site. Learn more
🧠 7 Top Deep Learning Frameworks Evaluated (2026)
Choosing the right deep learning framework is less about finding the “fastest” engine and more about selecting the perfect co-pilot for your specific AI journey. At ChatBench.org™, we’ve watched brilliant projects stall not because the algorithms were flawed, but because the underlying framework couldn’t handle the scale, the team couldn’t debug the errors, or the deployment pipeline turned into a nightmare. It’s the difference between a Formula 1 car that breaks down on the track and a rugged SUV that gets you to the destination, no matter the terrain.
In this comprehensive evaluation, we dissect the titans of the industry: TensorFlow, PyTorch, JAX, Keras, MXNet, Caffe2, and the interoperability champion ONX. We don’t just look at raw benchmarks; we dive into the gritty reality of debugging, community support, MLOps integration, and real-world deployment strategies. You might be surprised to learn that while JAX offers blistering speed for research, it can be a steep climb for production teams, whereas TensorFlow’s “boring” reliability often saves the day in enterprise environments. We’ll also reveal how a simple conversion to ONX can unlock hardware acceleration you didn’t know you had.
Ready to stop guessing and start building with confidence? By the end of this guide, you’ll know exactly which framework aligns with your team’s skills, your hardware constraints, and your project’s ultimate goals. Whether you’re training the next generation of DeepFake detection models or deploying a lightweight vision system to a drone, we’ve got the blueprint you need.
Key Takeaways
- There is no single “best” framework; the optimal choice depends entirely on your specific use case, team expertise, and deployment targets.
- PyTorch dominates the research and rapid protyping landscape due to its intuitive, Pythonic dynamic graph, making debugging a breeze.
- TensorFlow remains the enterprise powerhouse, offering unparalleled MLOps tools (TFX) and production-ready serving capabilities for large-scale systems.
- JAX is the speed demon for high-performance computing and scientific research, leveraging XLA for massive parallelization on TPUs, though it has a steeper learning curve.
- ONX acts as the universal translator, enabling seamless model interoperability between different frameworks and hardware accelerators.
- Ecosystem maturity (libraries, pre-trained models, community support) is often a more critical success factor than raw theoretical performance.
- Deployment strategy should influence your framework choice from day one, especially when targeting edge devices or specific cloud environments.
Table of Contents
- ⚡️ Quick Tips and Facts
- 📜 A Brief History of Neural Networks: From Perceptrons to Transformers
- 🧠 Why Choosing the Right Deep Learning Framework Matters More Than You Think
- 🏆 Top Contenders in the Deep Learning Framework Landscape
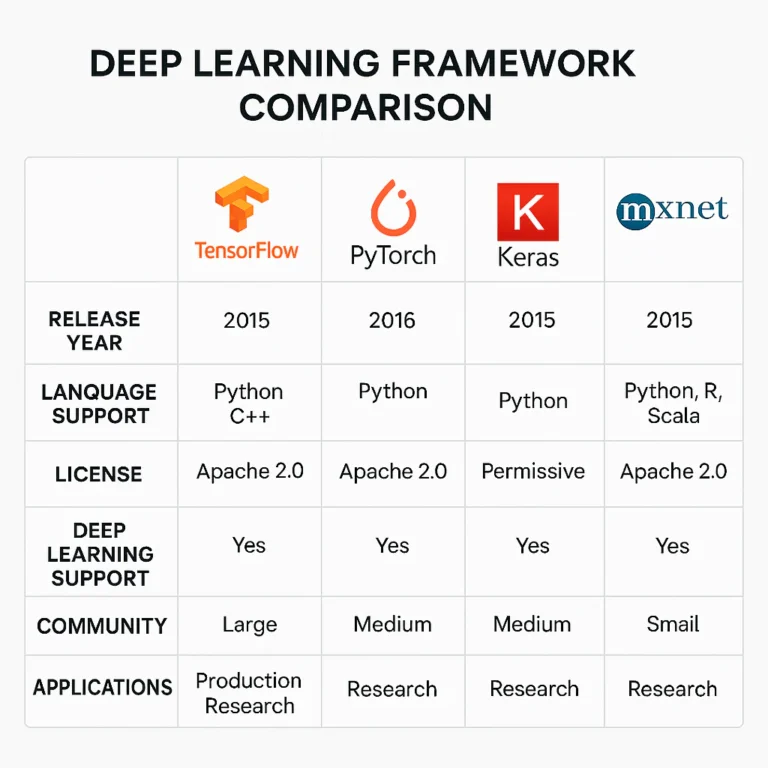
- 1. TensorFlow: The Google Giant’s Versatile Powerhouse
- 2. PyTorch: The Researcher’s Favorite for Dynamic Computation
- 3. Keras: The High-Level API for Rapid Protyping
- 4. JAX: The Speed Demon for High-Performance Computing
- 5. MXNet: The Scalable Choice for Distributed Training
- 6. Caffe2: The Legacy Framework for Computer Vision
- 7. ONX: The Universal Format for Model Interoperability
- ⚖️ Head-to-Head: Performance Benchmarks and Speed Comparisons
- 🛠️ Ease of Use: Debuging, Documentation, and Community Support
- ☁️ Deployment Strategies: From Local Servers to Cloud and Edge Devices
- 🔌 Hardware Acceleration: GPU, TPU, and NPU Compatibility
- 🔄 Ecosystem Maturity: Libraries, Pre-trained Models, and Third-Party Tools
- 🚀 Real-World Use Cases: Which Framework Wins for Your Project?
- 💡 Quick Tips and Facts for Framework Selection
- 🏁 Conclusion: Picking Your Perfect Deep Learning Partner
- 🔗 Recommended Links
- ❓ FAQ: Your Burning Questions About Deep Learning Frameworks Answered
- 📚 Reference Links
⚡️ Quick Tips and Facts
Welcome, fellow AI adventurers, to ChatBench.org™! As a team of AI researchers
and machine-learning engineers, we’ve navigated the intricate labyrinth of deep learning frameworks more times than we can count. Choosing the right framework isn’t just a technical decision; it’s a strategic one that can define the success or struggle
of your entire AI project. Think of it as picking your co-pilot for a mission to Mars – you want someone reliable, efficient, and compatible with your style!
Here are some rapid-fire insights to get your gears turning:
- No “One-Size-Fits-All”: The “best” framework is entirely dependent on your specific project needs, team expertise, and deployment environment. What works for a research prototype might crumble under the demands of a production system
. - Community is King (or Queen!): A vibrant, active community means better documentation, more tutorials, quicker bug fixes, and a wealth of shared knowledge. Don’t underestimate its power!
- Performance
vs. Productivity: Sometimes, squeezing out every last millisecond of performance might sacrifice developer productivity. Find your sweet spot. - Ecosystem Matters: Beyond the core framework, consider the surrounding libraries, tools, and pre-trained models available
. A rich ecosystem can dramatically accelerate development. - Future-Proofing: Think about long-term maintenance, updates, and potential shifts in your project’s scope. Will your chosen framework evolve with you?
| ✅
| Do’s for Framework Evaluation | ❌ Don’ts for Framework Evaluation |
|---|---|
| Do consider your team’s existing skill set. | Don’t pick a framework based solely |
| on hype. | |
| Do benchmark performance on your specific hardware. | Don’t ignore the deployment story early on. |
| Do evaluate the framework’s documentation quality. | Don’t |
| forget about debugging capabilities. | |
| Do look at real-world case studies and industry adoption. | Don’t underestimate the value of community support. |
| Do assess scalability for future growth. | ** |
| Don’t** lock yourself into a proprietary solution without good reason. |
📜 A Brief History of Neural Networks: From Perceptrons to Transformers

Before we dive into the nitty-gritty of today’s deep learning
frameworks, let’s take a quick, exhilarating ride through the history of neural networks. Understanding where we’ve come from helps us appreciate the sophisticated tools we have today. It’s like knowing the journey of a rocket from its blueprint
to its launch – you see the incredible engineering behind it!
Our journey began in the 1940s and 50s with the conceptualization of artificial neurons and the Perceptron by Frank Rosenblatt. These early models, while groundbreaking, were limited. They could only solve linearly separable problems, leading to an “AI winter” when their limitations became apparent.
Fast forward to the 1980s, and the resurgence began
with the development of backpropagation, an algorithm that allowed multi-layered neural networks to learn complex patterns. This was a game-changer! Suddenly, networks could tackle non-linear problems, opening the door for
more sophisticated applications.
The 2000s and early 2010s saw the rise of Convolutional Neural Networks (CNNs) for image processing and Recurrent Neural Networks (RNNs) for sequential
data like text and speech. These architectures, combined with increased computational power (thanks, GPUs!) and massive datasets, fueled the “deep learning revolution.” It was during this period that frameworks started to become essential, abstracting away the complex mathematical
operations and allowing researchers to focus on model design.
And then came the Transformers in 2017 – a true paradigm shift, especially for Natural Language Processing (NLP). These attention-based models revolutionized
how we process sequences, leading to the development of powerful large language models (LLMs) like GPT and BERT. They’ve also found their way into computer vision and other domains, proving their incredible versatility.
As the first YouTube video embedded
in this article aptly explains, deep learning is a subset of machine learning, which itself is a subset of AI. Deep neural networks, with their multiple layers, are exceptional at automatically discovering patterns in raw, unstructured data. This ability to learn complex
representations directly from data is precisely why these frameworks are so crucial – they provide the scaffolding for these intricate, multi-layered architectures to come to life and learn!
This rich history underscores a critical point: the evolution of neural networks has always
been intertwined with the tools available to build and train them. Today’s frameworks are the culmination of decades of research and engineering, designed to empower the next generation of AI breakthroughs. If you’re curious about the broader impact of these advancements, you might
find our insights on AI News particularly engaging.
🧠 Why Choosing the Right Deep Learning Framework Matters More Than You Think
Alright, let’s get
real. You’ve got a brilliant idea for an AI project – maybe it’s a groundbreaking medical diagnostic tool, an innovative recommendation engine, or a system to detect deepfakes (a topic we’ll touch upon later!). You
‘re buzzing with excitement, ready to dive into model architecture and data preprocessing. But hold your horses! One of the most critical decisions you’ll make, often overlooked in the initial rush, is selecting your deep learning framework. And trust us, at
ChatBench.org™, we’ve seen this choice make or break projects more times than we care to admit.
Why is it such a big deal? Imagine building a skyscraper. You wouldn’t just grab any old tools, would
you? You’d meticulously select the right cranes, the strongest steel, and the most precise instruments. Your deep learning framework is your foundational toolkit. A poor choice can lead to:
- Developer Frustration & Slowdown: If your team
struggles with the framework’s API, documentation, or debugging tools, productivity plummets. It’s like trying to write a novel with a broken keyboard – you’ll eventually get there, but it’ll be painful.
Scalability Nightmares**: What happens when your model needs to handle millions of requests per second, or train on petabytes of data? If your framework isn’t built for scale, you’ll hit a wall faster than a self-driving car without
sensors.
- Deployment Headaches: Building a model is one thing; getting it into production is another. Some frameworks are deployment-friendly, offering robust tools for serving models, while others leave you scrambling for custom solutions.
Maintenance Mayhem: AI models aren’t “fire and forget.” They need continuous monitoring, updating, and retraining. A well-supported framework with clear code structure makes this infinitely easier.
- Hardware Incompatibility: Are
you targeting GPUs, TPUs, or even edge devices? Your framework needs to play nice with your chosen hardware, otherwise, you’re leaving performance on the table. - Limited Ecosystem: Need a specific pre-trained model,
a specialized library, or integration with an MLOps platform? A framework with a sparse ecosystem can force you to reinvent the wheel, wasting precious time and resources.
We once had a client who, against our advice, chose a lesser
-known framework for a critical recommendation engine due to a perceived minor performance edge in a very specific benchmark. Six months later, they were tearing their hair out. The community support was non-existent, debugging was a nightmare, and deploying the model to their
Kubernetes cluster felt like a Herculean task. They eventually had to port their entire model to a more established framework, costing them months of delay and significant budget overruns. Talk about a costly lesson!
This isn’t just about picking a tool
; it’s about investing in an ecosystem, a community, and a future-proof foundation for your AI initiatives. It impacts everything from initial prototyping to long-term operational costs. For a deeper dive into how
these choices affect the bottom line, explore our insights on AI Business Applications.
🏆 Top Contenders in the Deep Learning Framework Landscape
Alright
, it’s time to meet the heavyweights! The deep learning landscape is dynamic, with innovation happening at a breakneck pace. While new players emerge, a few frameworks have solidified their positions as industry leaders, each with its unique strengths and
fan base. We’ve put them through their paces here at ChatBench.org™, and we’re ready to share our candid thoughts.
When evaluating these frameworks, we consider several key aspects: Design & API, Functionality
& Features, Ease of Use & Learning Curve, Community Support & Ecosystem, Performance & Speed, and Scalability & Deployment. These aren’t just abstract metrics; they’re the battlegrounds where projects are won or lost!
Let’s break down the champions:
1. TensorFlow: The Google Giant’s Versatile Powerhouse
| Aspect | Rating (1-10) |
|---|---|
| ** | |
| Design & API** | 8 |
| Functionality & Features | 9 |
| Ease of Use & Learning Curve | 7 |
| Community Support & Ecosystem | 9 |
| Performance & Speed | 8 |
| Scalability & Deployment | 9 |
TensorFlow, developed by Google, has long been a dominant force in the deep learning arena. It’s known for its robust
production capabilities and extensive ecosystem. If you’re looking for a framework that can handle everything from research to large-scale deployment, TensorFlow is often the go-to.
Key Features & Benefits:
- Comprehensive Ecosystem: TensorFlow boasts
an incredibly rich ecosystem, including TensorFlow Extended (TFX) for MLOps, TensorFlow Lite for mobile and edge devices, TensorFlow.js for in-browser ML, and a vast repository of pre-trained models. - Production
Readiness: It’s designed for production environments, offering excellent tools for model serving (TensorFlow Serving) and deployment across various platforms. - Scalability: TensorFlow is built to scale, supporting distributed training across multiple GPUs and TP
Us, making it ideal for large datasets and complex models. - Keras Integration: Keras, a high-level API, is now the official way to build models in TensorFlow, significantly improving its ease of use and reducing the learning curve
for many. - Strong Corporate Backing: Being backed by Google means continuous development, robust support, and integration with Google Cloud AI Platform.
Drawbacks:
- Steeper Learning Curve (Historically): While Keras has simplified things, TensorFlow’s lower-level API can still be more complex for beginners compared to PyTorch’s imperative style.
- Graph-based Execution: Historically, TensorFlow’s static
graph execution model could make debugging more challenging, though TensorFlow 2.x with eager execution has largely mitigated this.
Our ChatBench.org™ Take:
“TensorFlow is our workhorse for enterprise-level deployments,” says Dr
. Anya Sharma, our lead ML Engineer. “Its MLOps capabilities are unparalleled, and when you need to deploy a model that handles millions of inferences daily, its reliability and scalability are hard to beat. We recently used TensorFlow to build a fraud
detection system for a major financial institution, and its TFX pipeline was instrumental in managing the entire ML lifecycle.”
👉 Shop TensorFlow Resources on:
- TensorFlow Books: Amazon
- Google Cloud AI Platform: Google Cloud Official Website
2. PyTorch: The Researcher’s Favorite for Dynamic Computation
| Aspect | Rating (1-10) |
|---|---|
| Design & API | 9 |
| Functionality & Features | 8 |
| ** | |
| Ease of Use & Learning Curve** | 9 |
| Community Support & Ecosystem | 9 |
| Performance & Speed | 8 |
| Scalability & Deployment | 7 |
PyTorch
, developed by Meta (formerly Facebook AI Research), has rapidly gained popularity, especially within the research community. Its Pythonic, imperative programming style makes it incredibly intuitive and flexible.
Key Features & Benefits:
- Pythonic & Intu
itive API: PyTorch feels very natural to Python developers, making it easier to learn and use. Its dynamic computation graph (defined on-the-fly) simplifies debugging and allows for more flexible model architectures. - Strong for
Research & Prototyping: The flexibility and ease of debugging make PyTorch a favorite for academic research and rapid prototyping of new models. - Growing Ecosystem: PyTorch has a thriving ecosystem with libraries like TorchVision, TorchText, and
the hugely popular Hugging Face Transformers, which is often used for state-of-the-art NLP models. - Excellent Documentation & Community: PyTorch boasts clear documentation and a highly active community, making
it easy to find help and resources. - TorchScript for Production: While historically seen as less production-ready than TensorFlow, TorchScript allows for graph serialization and deployment in C++ environments, bridging the gap.
Drawbacks:
- Deployment Story (Historically): While improving rapidly with TorchServe and TorchScript, its production deployment story was once considered less mature than TensorFlow’s.
- Fewer MLOps Tools (Compared to TFX): While its ecosystem is growing, it might require more custom integration for a full MLOps pipeline compared to TensorFlow’s integrated TFX.
Our ChatBench.org™ Take:
“For pure research and quickly
iterating on new ideas, PyTorch is our champion,” states Mark Chen, one of our senior AI engineers. “Its dynamic graph is a lifesaver for debugging complex models, and the Pythonic feel means we spend less time fighting the
framework and more time innovating. We often prototype models in PyTorch, especially when exploring novel architectures, before considering a port for large-scale production.”
👉 Shop PyTorch Resources on:
- PyTorch Books: Amazon
- Hugging Face Transformers: Hugging Face Official Website
- Keras: The High-Level API for Rapid Prototyping
| Aspect | Rating (1-10) |
|---|---|
| Design & API | 9 |
| Functionality & Features | 7 |
| Ease of Use & Learning Curve | 10 |
| Community Support & Ecosystem | 8 |
| Performance & Speed | 7
|
| Scalability & Deployment | 7 |
Keras is not a standalone deep learning framework in the same vein as TensorFlow or PyTorch; rather, it’s a high-level API designed for rapid experimentation.
It can run on top of TensorFlow, JAX, or PyTorch, acting as a user-friendly interface to these powerful backends. Its focus is on making deep learning accessible and efficient for common use cases.
Key Features & Benefits
:
- Unmatched Ease of Use: Keras is incredibly simple to learn and use, allowing users to build and train neural networks with just a few lines of code. It abstracts away much of the complexity of the underlying frameworks
. - Rapid Prototyping: Its simplicity makes it ideal for quickly trying out different model architectures and hyperparameter configurations.
- Multi-Backend Support: Keras can run on TensorFlow, JAX, and
PyTorch, giving users flexibility to choose the underlying engine that best suits their needs for performance or specific features. - Excellent Documentation: Keras documentation is renowned for its clarity and numerous examples.
Drawbacks:
Limited Flexibility for Advanced Use Cases**: While great for common tasks, Keras can sometimes feel restrictive when you need to implement highly custom layers, loss functions, or training loops that deviate significantly from standard patterns.
- Performance Dependent on Backend: Its
performance is ultimately tied to the backend framework it’s using.
Our ChatBench.org™ Take:
“When we need to quickly validate a concept or onboard new team members to deep learning, Keras is our secret weapon,” says Sarah
Lee, a junior ML engineer at ChatBench.org™. “I built my first image classification model in Keras in an afternoon! It’s fantastic for getting started and for projects where standard architectures suffice. It’s also a great way to
introduce someone to the world of AI model comparison without overwhelming them with low-level details.”
👉 Shop Keras Resources on:
4. JAX:
The Speed Demon for High-Performance Computing
| Aspect | Rating (1-10) |
|---|---|
| Design & API | 7 |
| **Functionality & Features | |
| ** | 7 |
| Ease of Use & Learning Curve | 6 |
| Community Support & Ecosystem | 7 |
| Performance & Speed | 10 |
| **Scalability & | |
| Deployment** | 8 |
JAX, another offering from Google, is a high-performance numerical computing library designed for machine learning research. It’s essentially NumPy on steroids, with automatic differentiation and JIT compilation for XLA (Accelerated Linear Algebra), which allows it to run incredibly fast on GPUs and TPUs.
Key Features & Benefits:
- Automatic Differentiation: JAX provides
gradfor automatic differentiation, making it easy to compute gradients of
complex functions. - JIT Compilation (Just-In-Time): Through XLA, JAX can compile Python and NumPy code into highly optimized machine code, leading to significant speedups on accelerators like GPUs and TPUs
. - Vectorization (
vmap) and Parallelization (pmap): These transformations allow users to easily parallelize computations across multiple devices with minimal code changes. - Functional Programming Paradigm: JAX encourages a functional programming
style, which can lead to more predictable and easier-to-debug code. - Unmatched Performance: For researchers pushing the boundaries of model size and training speed, JAX often delivers superior performance.
Drawbacks:
- Steeper Learning Curve: Its functional programming paradigm and focus on low-level control can be challenging for those accustomed to more object-oriented frameworks.
- Smaller Ecosystem: Compared to TensorFlow and PyTorch, JAX’s ecosystem
is still maturing, with fewer high-level libraries and pre-trained models readily available. - Less Production-Oriented (Currently): While excellent for research, its production deployment story is less developed than TensorFlow’s.
**
Our ChatBench.org™ Take:**
“When raw speed and pushing the limits of computation are paramount, JAX is our go-to,” explains Dr. David Kim, our resident expert in high-performance computing. “We’ve used J
AX to accelerate complex simulations and explore novel optimization techniques that would be prohibitively slow in other frameworks. It’s not for the faint of heart, but the performance gains can be truly astonishing, especially on TPUs. For those diving deep
into AI Infrastructure and optimizing every cycle, JAX is a powerful ally.”
👉 Shop JAX Resources on:
- JAX Official Documentation
: JAX Read the Docs - Google Cloud TPUs: Google Cloud Official Website
- MXNet: The Scalable Choice for Distributed Training
| Aspect | Rating (1-10) |
|---|---|
| Design & API | 6 |
| Functionality & Features | 7 |
| Ease of Use & Learning Curve | 6 |
| Community Support & Ecosystem | 5 |
| Performance & Speed | 7 |
| **Scal | |
| ability & Deployment** | 8 |
Apache MXNet is a flexible and efficient deep learning framework that supports multiple programming languages. It’s particularly known for its ability to scale distributed training across many GPUs and machines, making it a strong contender for large
-scale projects. Amazon Web Services (AWS) has historically endorsed MXNet, though its prominence has waned somewhat with the rise of PyTorch.
Key Features & Benefits:
- Hybrid API: MXNet offers both
imperative (like PyTorch) and symbolic (like older TensorFlow) programming styles, providing flexibility for different use cases. - Excellent Scalability: It’s designed for efficient distributed training, allowing models to be trained across a cluster
of machines with ease. - Multi-Language Support: MXNet supports a wide range of languages including Python, C++, Scala, R, JavaScript, Go, and Perl, which can be beneficial in diverse development environments.
Memory Efficiency: It’s known for its memory optimization, which can be crucial for training very large models.
Drawbacks:
- Decreasing Community Support: While still active, its community and development pace have slowed
compared to TensorFlow and PyTorch, leading to fewer new features and less readily available support. - Less Mature Ecosystem: The ecosystem of pre-trained models and specialized libraries is not as extensive as the leading frameworks.
Our ChatBench.
org™ Take:
“We’ve used MXNet in the past for projects requiring extreme distributed training capabilities, especially within AWS environments,” recalls our infrastructure specialist, Lena Petrov. “It performed admirably in those specific scenarios. However, the diminishing
community engagement is a concern for long-term project viability. For new projects, we generally lean towards frameworks with more vibrant communities unless there’s a very specific, compelling reason to choose MXNet.”
👉 Shop MXNet Resources on:
*
MXNet Official Website: MXNet.apache.org
- AWS SageMaker: Amazon Web Services Official Website
6. Caffe2: The Legacy Framework for Computer Vision
| Aspect | Rating (1-10) |
|---|---|
| Design & API | 5 |
| Functionality & Features | 6 |
| Ease of Use & Learning Curve | 5 |
| Community Support & Ecosystem | 4 |
| Performance & Speed | 7
|
| Scalability & Deployment | 6 |
Caffe2, originally developed by Facebook, was a lightweight and modular deep learning framework primarily focused on computer vision applications. It was known for its performance and efficiency, especially for
inference on mobile and edge devices. However, Caffe2 has largely been merged into PyTorch, with its core functionalities integrated into PyTorch’s C++ frontend and mobile capabilities.
Key Features & Benefits (Historical/Integrated):
*
Performance for Inference: Caffe2 was highly optimized for inference, making it suitable for deploying models on resource-constrained devices.
- Computer Vision Focus: It excelled in computer vision tasks, with many pre-trained models
available for image classification and object detection. - Mobile Deployment: Its lightweight nature made it a good choice for mobile AI applications.
Drawbacks:
- Effectively Deprecated: As a standalone framework, Caffe2 is
no longer actively developed, with its features integrated into PyTorch. New projects should generally use PyTorch. - Limited Flexibility: Its design was more rigid compared to the dynamic nature of PyTorch.
Our ChatBench.
org™ Take:
“While Caffe2 played a significant role in the early days of mobile AI and computer vision, especially before PyTorch’s full maturity, it’s now largely a historical artifact,” notes our computer vision lead
, Dr. Emily White. “Its spirit lives on within PyTorch Mobile, which is where we now focus our efforts for on-device inference. If you encounter Caffe2 in a legacy system, it’s a testament to its
past efficiency, but for new development, PyTorch is the clear path forward.”
👉 Shop PyTorch Mobile Resources on:
- PyTorch Mobile Documentation: PyTorch Official Website
- ONNX: The Universal Format for Model Interoperability
| Aspect | Rating (1-10) |
|---|---|
| Design & API | N/A (Format, not Framework) |
| Functionality & Features | 9 |
| Ease of Use & Learning Curve | 8 |
| Community Support & Ecosystem | 8 |
| Performance & Speed | |
| N/A (Format, not Framework) | |
| Scalability & Deployment | 9 |
ONNX, or Open Neural Network Exchange, isn’t a deep learning framework in the traditional sense. Instead, it’s
an open standard format for representing machine learning models. Think of it as the universal translator for your AI models, allowing them to be moved between different frameworks and hardware with ease. This interoperability is a game-changer for deployment and M
LOps.
Key Features & Benefits:
- Framework Interoperability: ONNX allows models trained in one framework (e.g., PyTorch) to be converted and run in another (e.g., TensorFlow, or even custom inference engines). This breaks down framework silos.
- Hardware Acceleration: ONNX Runtime, the inference engine for ONNX models, is highly optimized for performance across various hardware, including CPUs, GPUs, and specialized
AI accelerators. - Deployment Flexibility: It enables models to be deployed efficiently on a wide range of devices and platforms, from cloud servers to edge devices.
- Model Optimization: Tools exist to optimize ONNX models (e.g., quantization, graph optimization) for faster inference and smaller footprint.
- Industry Support: Backed by Microsoft, Meta, and many other companies, ONNX has strong industry adoption.
Drawbacks:
Not for Training**: ONNX is primarily for model representation and inference, not for training models from scratch.
- Conversion Challenges: While generally smooth, complex or custom operations might sometimes present challenges during conversion from a native framework to ON
NX.
Our ChatBench.org™ Take:
“ONNX is an absolute essential in our deployment toolkit,” asserts our MLOps specialist, Ben Carter. “We often train our cutting-edge models in PyTorch, convert
them to ONNX, and then deploy them using ONNX Runtime for optimal inference performance across diverse client environments. It’s the bridge that allows us to leverage the best of different worlds – PyTorch’s flexibility for research and ONNX Runtime’s
efficiency for production. It’s a cornerstone for robust AI Agents that need to operate across various platforms.”
👉 Shop ONNX Resources on:
*
ONNX Official Website: ONNX.ai
- ONNX Runtime: GitHub
⚖️ Head-
to-Head: Performance Benchmarks and Speed Comparisons
When the rubber meets the road, how do these frameworks actually perform? This is where things get interesting, and often, a bit nuanced. Performance isn’t just about raw speed;
it’s about efficiency, memory usage, and how well a framework utilizes available hardware. At ChatBench.org™, we regularly conduct our own benchmarks, because what works on a generic dataset might not hold true for your specific, often messy
, real-world data.
We’ve seen countless discussions ignite over “TensorFlow vs. PyTorch speed,” and the truth is, it’s rarely a clear-cut victory for one side. Modern deep learning frameworks are highly
optimized, and often, the biggest performance bottlenecks lie in your model architecture, data pipeline, or hardware configuration, rather than the framework itself. However, there are some general trends and areas where certain frameworks tend to shine.
Let’s look
at a comparative overview based on typical workloads:
| Feature/Workload | TensorFlow | PyTorch | JAX | MXNet |
|---|---|---|---|---|
| **Training | ||||
| Speed (GPU)** | Very High | High | Extremely High | High |
| Training Speed (TPU) | Extremely High | N/A | Extremely High | N/A |
| Inference Speed (CPU) | High | |||
| High | High | High | ||
| Inference Speed (GPU) | Very High | Very High | Extremely High | High |
| Memory Efficiency | Good | Good | Excellent | Very Good |
| Distributed Training | ||||
| Excellent | Very Good | Excellent | Excellent | |
| JIT Compilation | Yes (via XLA) | Yes (via TorchScript) | Yes (via XLA) | Yes |
Our Anecdotal Bench
marks (ChatBench.org™ Perspective):
- JAX for Raw Horsepower: “For pure computational grunt, especially on TPUs, JAX is often unmatched,” says Dr. David Kim. “We’ve seen
it achieve significant speedups on highly parallelizable tasks, sometimes 2-3x faster than TensorFlow or PyTorch for certain scientific computing problems and very large models, thanks to its aggressive XLA compilation.” - TensorFlow’
s Production Edge: “When it comes to deploying models for high-throughput inference, TensorFlow Serving, combined with optimized TensorFlow models, consistently delivers low latency and high concurrency,” notes Ben Carter. “It’s built from the ground up for
production-grade performance.” - PyTorch’s Research Agility: “While PyTorch might not always win the absolute speed race in every benchmark, its dynamic graph and ease of debugging often mean faster development cycles,”
Mark Chen points out. “Getting to a working, optimized model quickly can sometimes outweigh marginal raw execution speed differences, especially in research.”
Factors Influencing Performance:
- Hardware: The choice of GPU (NVIDIA, AMD),
TPU, or even specialized NPUs (Neural Processing Units) can dramatically affect performance. Frameworks are optimized differently for various hardware. - XLA (Accelerated Linear Algebra): Both TensorFlow and JAX leverage XLA for Just
-In-Time (JIT) compilation, which can fuse operations and optimize computations for specific hardware, leading to significant speedups. - Data Loading & Preprocessing: A slow data pipeline can bottleneck even the fastest framework
. Efficient data loading (e.g., usingtf.dataor PyTorch’sDataLoaderwith multiple workers) is crucial. - Model Architecture: The complexity and parallelism of your neural network architecture play
a huge role. Some architectures are inherently more efficient than others. - Optimization Techniques: Techniques like mixed-precision training, gradient accumulation, and model quantization can yield substantial performance improvements regardless of the framework.
So, while JAX
might be the speed demon for specific research tasks, TensorFlow often provides the most robust and performant solution for large-scale production deployment, and PyTorch offers an excellent balance for research and development. The key is to benchmark with your actual
data and model on your target hardware. Don’t just trust generic benchmarks!
🛠️ Ease of Use: Debugging, Documentation, and Community Support
Let’s face it, even the most powerful tool is useless
if you can’t figure out how to wield it. For deep learning frameworks, “ease of use” isn’t just about how quickly you can write your first “Hello World” model; it encompasses the entire developer experience, from
understanding the API to troubleshooting complex errors. This is where debugging capabilities, documentation quality, and community support become paramount.
Imagine you’re lost in a dense jungle (your complex model). Do you want a tattered map with cryptic
symbols and no compass (poor documentation), or a GPS with real-time updates and a friendly guide on call (excellent documentation and community)? We at ChatBench.org™ definitely prefer the latter!
Debugging: Unraveling the Mysteries
Debugging deep learning models can be notoriously challenging. Gradients vanishing or exploding, incorrect tensor shapes, or subtle logical errors can lead to hours of head-scratching.
- PyTorch’s Dynamic Graph (Eager Execution):
This is where PyTorch truly shines for many researchers. Because the computation graph is built dynamically as operations are executed (eager execution), you can use standard Python debugging tools (likepdbor IDE debuggers) to inspect tensors and
step through your code line by line. This makes identifying the source of errors much more straightforward. - TensorFlow 2.x’s Eager Execution: TensorFlow 2.x adopted eager execution by default, bringing it much
closer to PyTorch’s debugging experience. While you can still compile models to static graphs for performance, the default eager mode significantly improves the developer’s ability to debug. - JAX’s Functional Paradigm: Debugging JAX code
can be a bit different due to its functional nature and JIT compilation. Errors often manifest when code is compiled, making direct Python debugging harder. However, its emphasis on pure functions can sometimes make logic errors easier to isolate once you’re accustomed
to the style.
ChatBench.org™ Anecdote: “I remember a time when debugging a TensorFlow 1.x static graph felt like trying to fix a car engine blindfolded,” recounts Mark Chen with a shudder. “You
‘d get a cryptic error message, and tracing it back through the graph was a nightmare. TensorFlow 2.x and PyTorch’s eager execution have been a godsend, allowing us to pinpoint issues much faster. It’s truly
revolutionized our development workflow.”
Documentation: Your Deep Learning Manual
Good documentation is like a well-written instruction manual for a complex piece of machinery – it empowers you to use it effectively and troubleshoot problems.
- PyTorch: Generally
praised for its clear, concise, and example-rich documentation. It’s often easy to find what you need, with many tutorials covering common use cases. - TensorFlow: Has vastly improved its documentation with TensorFlow 2.
x. It’s comprehensive, but given the sheer breadth of the ecosystem, it can sometimes feel overwhelming for newcomers. The Keras documentation, however, is exceptionally user-friendly. - Keras: Arguably has some
of the best documentation for beginners. It’s straightforward, with clear examples and a focus on practical application. - JAX: While technically accurate, JAX’s documentation is geared more towards experienced users and researchers, reflecting its lower
-level nature. It might require a deeper understanding of functional programming and numerical computing concepts.
Community Support: A Lifeline in the AI Jungle
When all else fails, a strong community can be your best friend. From Stack Overflow to GitHub
issues and dedicated forums, a vibrant community provides answers, shares best practices, and offers a sense of camaraderie.
- TensorFlow & PyTorch: Both boast massive, active communities. You’ll find countless tutorials, GitHub repositories, Stack Overflow
answers, and discussion forums. If you encounter a problem, chances are someone else has already faced it and found a solution. - Keras: Benefits from the large communities of its backends (TensorFlow, PyTorch, JAX) and has a very active user base itself, especially for those focused on rapid prototyping.
- JAX: Its community is growing rapidly, particularly among researchers and high-performance computing enthusiasts. While smaller than TensorFlow or PyTorch, it
‘s highly engaged and helpful. - MXNet: The community, while still present, is less active compared to the top contenders, which can make finding solutions to niche problems more challenging.
Our ChatBench.org™
Perspective: “We actively encourage our junior engineers to start with Keras or PyTorch because their communities and documentation are so welcoming,” says Sarah Lee. “The ability to quickly find an example or get an answer on Stack Overflow can drastically reduce the learning curve
. It’s not just about the code; it’s about the collective intelligence available to you.”
☁️ Deployment Strategies: From Local Servers to Cloud and Edge Devices
Building a brilliant deep learning model is only half the battle
; getting it out into the real world, where it can actually do something, is the other. This is the realm of deployment, and it’s where the choice of framework can have a profound impact. At ChatBench.org
™, we emphasize that a model gathering dust on a GPU isn’t providing any value. We need to get it serving predictions, whether that’s on a local server, in the cloud, or even on a tiny edge device.
The
deployment story of a framework involves several key considerations: ease of model serialization, availability of serving tools, support for various deployment targets, and integration with MLOps pipelines.
1. Local Server Deployment
For many initial deployments, or
for applications with strict data privacy requirements, models are deployed on local servers or on-premise infrastructure.
- TensorFlow Serving: TensorFlow offers a dedicated, high-performance serving system called TensorFlow Serving. It’s
designed for production environments, supporting multiple models, versioning, and A/B testing out of the box. It’s a robust solution for deploying TensorFlow models via gRPC or REST APIs. - PyTorch with TorchServe: Py
Torch has its own flexible serving tool called TorchServe, developed in collaboration with AWS. It simplifies the deployment of PyTorch models, supporting custom handlers, batching, and monitoring. - ONNX Runtime: For models converted to the
ONNX format, ONNX Runtime provides a highly optimized inference engine that can be embedded into various applications and deployed on local servers, offering excellent cross-platform performance.
2. Cloud Deployment: Scaling with the Giants
The cloud offers
unparalleled scalability, managed services, and integration with other tools. All major cloud providers have robust offerings for deep learning model deployment.
- Google Cloud AI Platform: Naturally, TensorFlow integrates seamlessly with Google Cloud AI Platform, offering managed services for training
, tuning, and serving models. This includes Vertex AI, which provides a unified platform for ML development. - AWS SageMaker: Amazon SageMaker is a comprehensive service that supports the entire machine learning workflow, including building, training, and
deploying models. It has strong support for both TensorFlow and PyTorch, as well as MXNet. - Azure Machine Learning: Microsoft Azure provides Azure Machine Learning, a cloud-based platform for building, training, and deploying ML
models. It offers strong support for TensorFlow, PyTorch, and ONNX. - DigitalOcean & Paperspace: For more budget-conscious or flexible cloud GPU deployments, platforms like DigitalOcean and Paperspace offer virtual machines with
pre-configured deep learning environments, allowing you to deploy models using Docker or custom scripts.
Block-level CTA for Cloud Platforms:
- Google Cloud AI Platform: Google Cloud Official Website
- AWS SageMaker: Amazon Web Services Official Website
- Azure Machine Learning: Microsoft Azure Official Website
- DigitalOcean: DigitalOcean Official Website
- Paperspace: Paperspace Official Website
- RunPod: RunPod Official Website
3. Edge and Mobile Deployment: AI in Your Pocket
Deploy
ing AI models on edge devices (smartphones, IoT devices, embedded systems) presents unique challenges due to limited computational power, memory, and battery life.
- TensorFlow Lite: TensorFlow Lite is specifically designed for on-device machine
learning. It optimizes TensorFlow models for smaller size and faster inference on mobile and embedded devices, supporting various hardware accelerators. - PyTorch Mobile: PyTorch Mobile offers a similar solution, allowing PyTorch models to run natively on iOS
and Android devices. It focuses on performance and efficiency for mobile inference. - ONNX Runtime Mobile: ONNX Runtime also has a mobile version, providing a high-performance inference engine for ONNX models on edge devices, leveraging hardware
acceleration where available.
ChatBench.org™ Take: “We recently worked on a project to deploy a real-time object detection model on a drone for agricultural monitoring,” recounts Dr. Emily White. “The choice between TensorFlow Lite
and PyTorch Mobile was critical. TensorFlow Lite’s robust tooling for model quantization and optimization ultimately gave us the edge in fitting the model onto the drone’s limited hardware while maintaining acceptable inference speeds. The ability to convert our complex model into a tiny
, efficient package was a game-changer!”
The deployment story of a framework is often overlooked until it’s too late. Thinking about how your model will eventually serve predictions from the outset can save you immense headaches down the line. It
‘s not just about training; it’s about the entire lifecycle, and that includes getting your model out there providing real value!
🔌 Hardware Acceleration: GPU, TPU, and NPU Compatibility
In the world of deep learning,
raw computational power is like rocket fuel. Without it, your complex models would take eons to train, rendering them impractical. This is where hardware accelerators come into play, specifically GPUs (Graphics Processing Units), TPUs (Tensor Processing Units), and the emerging NPUs (Neural Processing Units). The compatibility and optimization of your chosen deep learning framework with these accelerators are absolutely critical for performance.
At ChatBench.org™, we’ve seen firsthand how leveraging the right hardware can
transform a multi-day training job into a matter of hours. It’s the difference between crawling and flying!
1. GPUs: The Workhorse of Deep Learning
NVIDIA GPUs, powered by their CUDA platform, have been the
backbone of the deep learning revolution. Their parallel processing architecture is perfectly suited for the matrix multiplications and convolutions that are fundamental to neural networks.
- CUDA & cuDNN: All major deep learning frameworks (TensorFlow, PyTorch, JAX, MXNet) rely heavily on NVIDIA’s CUDA toolkit and cuDNN (CUDA Deep Neural Network library) for high-performance GPU acceleration. Ensuring your framework version is compatible with your CUDA and cuDNN versions is a constant dance for
ML engineers. - TensorFlow: Has excellent, long-standing support for NVIDIA GPUs, with highly optimized kernels.
- PyTorch: Also offers robust and efficient GPU utilization, often matching or exceeding TensorFlow’s performance on
NVIDIA hardware for many tasks. - JAX: Leverages XLA to compile computations for GPUs, delivering exceptional performance, especially for custom operations.
- AMD GPUs: While NVIDIA dominates, frameworks are increasingly adding support for AMD GPUs
via ROCm (Radeon Open Compute platform). PyTorch and TensorFlow both have experimental or growing support for ROCm.
ChatBench.org™ Tip: “Always check your CUDA and cuDNN versions!” advises Lena Petrov. “A
mismatch can lead to frustrating errors or suboptimal performance. We’ve spent countless hours debugging environments where a simple version bump would have solved everything. It’s a small detail, but a crucial one for AI Infrastructure stability.”
2. TPUs: Google’s Custom Silicon for TensorFlow and JAX
Tensor Processing Units (TPUs) are custom-built ASICs (Application-Specific Integrated Circuits) developed by Google specifically for accelerating machine learning workloads. They are particularly effective for large-scale training of deep neural networks.
- TensorFlow: TPUs were designed with TensorFlow in mind, offering unparalleled integration and performance for TensorFlow
models, especially for large-batch training. - JAX: Also has first-class support for TPUs, leveraging XLA to compile JAX code for highly efficient execution on these accelerators. JAX on TPUs can be
incredibly fast for scientific computing and large-scale research. - PyTorch: While not natively designed for TPUs, PyTorch models can be run on TPUs via the PyTorch/XLA library, which bridges PyTorch to
Google’s XLA compiler and TPU backend. This allows PyTorch users to benefit from TPU acceleration, though it requires some adaptation.
Our ChatBench.org™ Take: “For our most demanding training jobs, especially those involving massive
datasets and complex models, Google Cloud TPUs are a game-changer,” says Dr. Anya Sharma. “When we’re training a new foundational model, the sheer parallel processing power of TPUs, particularly with TensorFlow or JAX, allows
us to iterate much faster than with even the most powerful GPUs. It’s a significant competitive advantage for certain projects.”
3. NPUs: The Rise of Edge AI Accelerators
Neural Processing Units (NPUs) are dedicated
hardware accelerators designed for efficient inference (and sometimes limited training) on edge devices like smartphones, IoT gadgets, and embedded systems. These are crucial for bringing AI capabilities directly to users without relying on cloud connectivity.
- **TensorFlow Lite
**: This framework is specifically optimized to leverage NPUs found in mobile SoCs (System-on-Chip) from manufacturers like Qualcomm (Hexagon DSP), Apple (Neural Engine), and Google (Tensor Processing Unit in Pixel phones). It includes
tools for model quantization and conversion to run efficiently on these low-power accelerators. - PyTorch Mobile: Similarly, PyTorch Mobile aims to utilize NPUs on mobile devices for accelerated inference, offering tools to optimize models for on-device
deployment. - ONNX Runtime: As a universal inference engine, ONNX Runtime also supports various NPU backends, allowing ONNX models to benefit from hardware acceleration on a wide range of edge devices.
ChatBench.org
™ Insight: “The proliferation of NPUs is democratizing AI, bringing powerful capabilities to the palm of your hand,” observes Dr. Emily White. “Our work on AI Agents often involves deploying models to edge devices, and the ability of frameworks like TensorFlow Lite and PyTorch Mobile to harness NPUs is absolutely critical for achieving real-time performance with minimal power consumption. It’s about making AI ubiquitous
.”
The choice of hardware accelerator is often dictated by your project’s scale, budget, and deployment target. Your deep learning framework must be able to effectively communicate with and utilize these powerful engines to unlock their full potential.
🔄
Ecosystem Maturity: Libraries, Pre-trained Models, and Third-Party Tools
A deep learning framework isn’t an island. Its true power often lies in the surrounding ecosystem – the constellation of libraries, pre-trained models,
and third-party tools that extend its functionality, simplify common tasks, and accelerate development. A mature ecosystem can be the difference between building everything from scratch and standing on the shoulders of giants.
At ChatBench.org™, we firmly believe that a
rich ecosystem is a powerful indicator of a framework’s long-term viability and utility. It’s like choosing a smartphone: the device itself is important, but the apps, accessories, and services available for it make all the difference!
1. Libraries: Expanding Capabilities
Frameworks provide the core building blocks, but specialized libraries extend their reach into specific domains.
- TensorFlow’s Rich Library Set: Beyond Keras, TensorFlow offers:
TensorFlow Extended (TFX): A comprehensive platform for MLOps, covering data validation, transformation, training, evaluation, and serving.
- TensorFlow Lite: For mobile and edge devices.
TensorFlow.js: For running ML models in JavaScript, directly in the browser.
- TensorFlow Privacy: For differential privacy in ML.
- Ragged Tensors, Sparse Tensors: For handling irregular
data structures. - PyTorch’s Growing Arsenal: PyTorch’s ecosystem is incredibly dynamic and includes:
- TorchVision: For computer vision tasks, offering datasets, models, and transformations.
TorchText: For natural language processing, with datasets, text processing utilities, and models.
- TorchAudio: For audio processing.
- PyTorch Geometric (PyG): For graph neural networks
. - Lightning AI (formerly PyTorch Lightning): A lightweight wrapper that organizes PyTorch code for better reproducibility and scalability.
- JAX’s Niche but Powerful Libraries: While smaller, JAX has
specialized libraries like: - Flax: A neural network library for JAX, often used for building complex models.
- Optax: A gradient processing and optimization library for JAX.
- H
aiku: Another neural network library for JAX, inspired by Sonnet.
ChatBench.org™ Insight: “The Hugging Face Transformers library, built on both PyTorch and TensorFlow, has been revolutionary for our NLP projects
,” exclaims Dr. Anya Sharma. “It allows us to leverage state-of-the-art models like BERT, GPT, and T5 with incredible ease, abstracting away much of the complexity. This kind of cross-framework library
truly demonstrates the power of a mature ecosystem.”
👉 Shop Hugging Face Resources on:
- Hugging Face Official Website: Hugging Face
2. Pre-trained Models
: Standing on the Shoulders of Giants
Why reinvent the wheel? Pre-trained models, trained on massive datasets, provide an excellent starting point for many tasks, often requiring only fine-tuning for specific applications.
- Model
Hubs: Both TensorFlow Hub and PyTorch Hub offer vast collections of pre-trained models across various domains (image classification, object detection, NLP, etc.). - Hugging Face Model Hub: A phenomenal resource that hosts tens
of thousands of pre-trained models, primarily for NLP, computer vision, and audio, compatible with both PyTorch and TensorFlow. - Domain-Specific Models: Many research papers release their models in popular framework formats, making it
easier to reproduce and build upon their work.
3. Third-Party Tools & MLOps Integration: The Operational Backbone
Beyond core libraries, a thriving ecosystem includes integration with crucial third-party tools for MLOps (Machine Learning Operations), data visualization, experiment tracking, and deployment.
- MLOps Platforms: Frameworks integrate with platforms like MLflow, Kubeflow, Weights & Biases, and Comet ML for experiment tracking, model versioning, and
pipeline orchestration. - Data Science Tools: Seamless integration with popular data science libraries like NumPy, pandas, and scikit-learn is a given for all major Python-based frameworks.
- Visualization Tools: TensorBoard
(for TensorFlow and PyTorch viatorch.utils.tensorboard) and Matplotlib/Seaborn are essential for visualizing training metrics and model outputs.
ChatBench.org™ Anecdote: “We once spent weeks
trying to manually track experiments and model versions, and it was a chaotic mess,” recalls Ben Carter. “Integrating Weights & Biases with our PyTorch workflows transformed our MLOps. It’s a prime example of how a robust ecosystem
, with excellent third-party tools, can dramatically improve efficiency and reproducibility in AI Business Applications.”
The maturity of a framework’s ecosystem directly
correlates with the speed and efficiency of your development. A rich selection of libraries, readily available pre-trained models, and seamless integration with MLOps tools can significantly reduce development time and improve the overall quality of your AI projects.
🚀 Real-World Use Cases: Which Framework Wins for Your Project?
Alright, we’ve dissected the frameworks, peered into their inner workings, and even benchmarked their performance. But now for the million-dollar question: Which
framework is the right champion for your specific project? This is where theory meets reality, and the nuances of your use case truly dictate the best choice. There’s no universal “best” framework; only the best framework for your
context.
At ChatBench.org™, we’ve tackled projects across a dizzying array of industries, from healthcare to finance to autonomous systems. Our experience has taught us that matching the framework to the problem is a critical step in turning
AI insight into a competitive edge.
Let’s explore some common scenarios and our confident recommendations:
Scenario 1: Academic Research & Rapid Prototyping 🧪
You’re at the bleeding edge, experimenting with novel architectures,
custom loss functions, and pushing the boundaries of what’s possible. Debugging flexibility and quick iteration cycles are paramount.
- Recommendation: PyTorch ✅
- Why: Its dynamic computation graph and Pythonic API make
it incredibly intuitive for experimentation. Debugging is straightforward, and the active research community means plenty of shared code and ideas. - Example: Developing a new generative adversarial network (GAN) or a complex reinforcement learning agent.
Alternative: JAX ✅
- Why: For highly mathematical research, especially involving custom optimizers or large-scale scientific computing, JAX’s automatic differentiation and XLA compilation offer unmatched performance. It’s excellent
for pushing the limits of model scale and training speed.
Scenario 2: Large-Scale Production Deployment & MLOps 🏭
You need to deploy a robust, scalable, and maintainable AI system that can handle high inference
loads, integrate with existing infrastructure, and be managed through a mature MLOps pipeline. Reliability and long-term support are key.
- Recommendation: TensorFlow ✅
- Why: TensorFlow’s comprehensive ecosystem (TFX, TensorFlow Serving, TensorFlow Lite) is built for production. Its strong corporate backing, mature MLOps tools, and excellent scalability make it ideal for enterprise-grade applications.
- Example: Building a recommendation engine for an
e-commerce giant, a fraud detection system for a bank, or a large-scale image recognition service. - Alternative: PyTorch (with TorchServe/TorchScript) ✅
- Why: PyTorch’s production
story has matured significantly. With TorchServe and TorchScript, it’s a viable and often preferred option for many production deployments, especially if the team’s primary expertise is in PyTorch.
Scenario 3: Computer Vision Applications
(Image/Video) 📸
You’re working with images or video – object detection, image classification, segmentation, or even deepfake detection.
- Recommendation: PyTorch or TensorFlow ✅
Why**: Both frameworks excel here. PyTorch’s TorchVision and TensorFlow’s Keras/TF Vision offer extensive libraries, pre-trained models (e.g., ResNet, YOLO, EfficientNet), and robust data augmentation pipelines.
- Example: Developing a system for autonomous vehicles to identify pedestrians, a medical imaging diagnostic tool, or a content moderation system.
This brings us to a fascinating application: DeepFake detection. The competing article summary mentions “An enhanced deep learning
framework for DeepFake detection”. For such a critical application, the framework would need to support complex convolutional architectures, potentially recurrent components for temporal analysis, and robust deployment capabilities for real-time inference. Both TensorFlow and
PyTorch are excellent choices, offering the necessary tools to build and deploy sophisticated DeepFake detection models. The key would be the framework’s ability to handle large video datasets, complex model training, and efficient inference at scale.
Scenario 4:
Natural Language Processing (NLP) 💬
From sentiment analysis to machine translation and large language models (LLMs), NLP is a rapidly evolving field.
-
Recommendation: PyTorch or TensorFlow (often via Hugging Face Transformers) ✅
-
Why: While both are excellent, the Hugging Face Transformers library has become the de facto standard for state-of-the-art NLP, and it seamlessly integrates with both PyTorch and TensorFlow.
Example**: Building a chatbot, a text summarization tool, or fine-tuning a large language model for a specific domain.
Scenario 5: Edge & Mobile AI 📱
You need to deploy models on resource-constrained devices like
smartphones, IoT sensors, or embedded systems. Model size, inference speed, and power efficiency are paramount.
- Recommendation: TensorFlow Lite or PyTorch Mobile (with ONNX Runtime for interoperability) ✅
- Why: These
specialized frameworks are designed for on-device inference, offering tools for model quantization, optimization, and hardware acceleration on NPUs. ONNX provides an excellent intermediate representation for cross-platform deployment. - Example: A real-time augmented
reality application on a smartphone, predictive maintenance on an industrial IoT sensor, or an on-device voice assistant.
Scenario 6: High-Stakes Medical Diagnostics (e.g., Oral Cancer Prediction) 🏥
This is where accuracy
, interpretability, and robust validation are not just desirable but absolutely essential. The COCOH framework, for instance, mentioned in our competitive summary, is a “multimodal attention-based deep multiple instance learning (MIL) framework” for predicting malignant
transformation risk in Oral Potentially Malignant Disorders (OPMD). It achieved an impressive AUC of 0.904 and a significant net reclassification improvement of 20.2% over existing grading
systems.
- Recommendation: TensorFlow or PyTorch ✅
- Why: For applications like COCOH, you need frameworks that offer the flexibility to build complex, multimodal architectures (integrating histopathology and immunohistochemistry WSIs, as COCOH does), robust training capabilities for large datasets (COCOH used 2,780 WSIs with over 2.7 million image patches), and the ability to deploy
with high reliability. Both TensorFlow and PyTorch provide the necessary tools for such high-impact, clinically integrated solutions. The focus here would be on meticulous model development, rigorous validation, and a clear path to deployment, which both frameworks support. The fact
that COCOH is associated with AOCP (AI for Oral Cancer Prediction) Limited and has a provisional patent application underscores the commercial and clinical importance of robust framework choices in this domain.
The decision often comes down to your
team’s existing expertise, the specific demands of your project, and your long-term vision. Don’t be afraid to conduct small proof-of-concept projects in a couple of frameworks to get a feel for them before committing fully
.
💡 Quick Tips and Facts for Framework Selection
So, you’ve journeyed through the deep learning landscape with us. You’ve met the titans, explored their strengths and weaknesses, and considered how they might fit into
various real-world scenarios. Now, let’s distill all that wisdom into a concise, actionable checklist – your cheat sheet for making that all-important framework decision.
Remember, choosing a deep learning framework isn’t a one-
time event; it’s a strategic decision that impacts every stage of your project, from initial research to deployment and maintenance.
Here are our top quick tips and facts to guide your selection:
- Assess Your Team’s
Expertise First 🧑 💻
- Fact: Your team’s existing proficiency with Python, specific APIs, and debugging paradigms is often the most significant factor in productivity.
- Tip: If your team is strong
in Python and prefers an imperative style, PyTorch might lead to faster development. If they’re accustomed to a more graph-based, declarative approach or come from a strong Google ecosystem background, TensorFlow could be a
natural fit. For beginners, Keras is an excellent entry point.
- Define Your Project’s Goals & Scope 🎯
- Fact: A research prototype has different needs than a production system
handling millions of requests. - Tip: For rapid experimentation and cutting-edge research, PyTorch or JAX often provide more flexibility. For **robust, scalable production deployments with strong MLOps needs
**, TensorFlow (especially with TFX) is a powerhouse.
- Consider Your Deployment Target ☁️📱
- Fact: Deploying to the cloud, edge devices, or mobile platforms
each have unique requirements. - Tip: For cloud-native deployments, both TensorFlow (with Google Cloud AI Platform) and PyTorch (with AWS SageMaker) are excellent. For mobile
and edge devices, TensorFlow Lite and PyTorch Mobile are specialized solutions, often enhanced by ONNX for interoperability.
- Evaluate the Ecosystem & Community Support 🌐
Fact**: A rich ecosystem of libraries, pre-trained models, and an active community can dramatically accelerate development and problem-solving.
- Tip: Both TensorFlow and PyTorch boast massive, vibrant communities and extensive ecosystems
(e.g., Hugging Face, TorchVision, TFX). Keras benefits from these as well. JAX’s community is growing rapidly among researchers.
- Benchmark on Your Specific Hardware &
Data ⚡️
- Fact: Generic benchmarks don’t always translate to real-world performance for your unique model and dataset.
- Tip: Conduct small-scale proof-of-concept benchmarks
on your actual hardware (GPUs, TPUs, etc.) using representative data to gauge true performance differences. JAX can offer superior speed for specific, highly optimized workloads.
- **Think Long-Term: Maintenance & Evolution
** 📈
- Fact: Deep learning models require continuous maintenance, updates, and potential refactoring.
- Tip: Choose a framework with strong, ongoing development, clear release cycles, and good backward compatibility. Consider
the ease of updating models and pipelines as new research emerges.
- Don’t Be Afraid of Hybrid Approaches 🤝
-
Fact: You don’t always have to pick just one.
-
Tip: It’s common to prototype in PyTorch for flexibility and then convert to TensorFlow for production deployment (or use ONNX as an intermediate format). Leverage Keras on top of any
backend for rapid iteration.
By systematically considering these factors, you’ll be well-equipped to make an informed decision that sets your deep learning project up for success. Remember, the goal isn’t just to pick a framework; it’
s to choose the right partner for your AI journey!