Support our educational content for free when you purchase through links on our site. Learn more
Optimize Your AI Model Performance: 9 Proven Tuning & Validation Hacks (2026) 🚀
Ever wonder why some AI models hit bullseyes while others barely make the target? The secret sauce often lies in hyperparameter tuning and cross-validation—two powerhouse techniques that can transform your AI from “meh” to magnificent. At ChatBench.org™, we’ve seen models leap from mediocre to market-ready just by mastering these strategies.
Did you know that a well-tuned model can boost accuracy by over 20%, sometimes even more? But here’s the kicker: blindly tweaking parameters or relying on a single train-test split can mislead you into thinking your model’s a superstar when it’s actually overfitting or underperforming in the wild. Stick around because later, we’ll reveal how to efficiently navigate vast hyperparameter spaces with smart search methods and how to wield cross-validation like a pro to safeguard your model’s generalizability.
Whether you’re a seasoned ML engineer or just starting your AI journey, this guide will equip you with 9 actionable hacks to optimize your AI model’s performance, backed by real-world insights and expert tips. Ready to unlock your model’s full potential? Let’s dive in!
Key Takeaways
- Hyperparameter tuning is critical for unlocking your model’s best performance; it’s like fine-tuning the engine of a race car.
- Cross-validation provides a robust way to evaluate models and prevent overfitting by testing on multiple data splits.
- Not all tuning methods are created equal: start with Random Search for efficiency, then refine with Bayesian Optimization for precision.
- Feature engineering and selection dramatically impact tuning success by feeding your model the right signals.
- Ensemble methods combined with tuning and validation can supercharge your model’s accuracy and robustness.
- Validating synthetic data and multimodal annotation are emerging frontiers to broaden your training horizons.
- Practical tips like scaling features, handling missing data, and managing class imbalance are essential complements to tuning and validation.
By mastering these techniques, you’ll build AI models that don’t just perform well on paper but thrive in real-world applications.
Table of Contents
- ⚡️ Quick Tips and Facts for Hyperparameter Tuning & Cross-Validation
- 🔍 Demystifying AI Model Optimization: The Role of Hyperparameters and Validation
- 🎯 What Exactly Is Model Accuracy and Why Should You Care?
- 📊 Adding More Data: Fueling Your AI Model’s Performance Engine
- 🛠️ Handling Missing Values and Outliers: Cleaning Your Data for Better Results
- ✨ Feature Engineering Magic: Crafting Inputs That Make Your Model Shine
- 🔎 Feature Selection Strategies: Picking the Best Ingredients for Your Model
- 🤖 Exploring Multiple Algorithms: Finding the Perfect Fit for Your Data
- ⚙️ Algorithm Tuning: Mastering the Art of Hyperparameter Optimization
- 🧩 Ensemble Methods Explained: Combining Models for Supercharged Performance
- 🔄 Cross-Validation Techniques: Your Secret Weapon Against Overfitting
- 📈 Advanced Hyperparameter Tuning Methods: Grid Search, Random Search, and Bayesian Optimization
- 🧪 Validating Synthetic Data: Ensuring Quality for Robust Model Training
- 🎥 Multimodal Data Annotation: Combining Visual, Temporal & Textual Labels for Better Models
- 🖼️ Image Segmentation Techniques: Polygon, Mask, or Keypoint Annotation?
- 🧠 Panoptic Segmentation: Unifying Stuff & Things for Comprehensive Image Understanding
- 💡 Quick Tips to Boost Your AI Model’s Performance
- 🎯 Conclusion: Wrapping Up Your AI Optimization Journey
- 🔗 Recommended Links for Deep Dives and Tools
- ❓ FAQ: Your Burning Questions Answered
- 📚 Reference Links: Trusted Sources and Further Reading
⚡️ Quick Tips and Facts for Hyperparameter Tuning & Cross-Validation
Alright, fellow AI adventurers! Before we dive deep into the nitty-gritty, let’s arm you with some rapid-fire wisdom from the trenches of ChatBench.org™. Think of these as your cheat codes for making your AI models sing! 🚀
- Hyperparameters are your model’s DNA: They’re not learned from data but set before training. Think of them as the knobs and dials you tweak to get the best performance. Get them wrong, and your model might just be humming off-key!
- Cross-Validation is your truth serum: It’s the ultimate test to see if your model is truly robust or just memorizing the training data (overfitting). It helps you predict how well your model will perform on unseen data – the real world!
- No one-size-fits-all: The “best” hyperparameters or cross-validation strategy depend heavily on your dataset, problem, and chosen algorithm. Experimentation is key! 🧪
- Overfitting is the enemy: This is when your model performs brilliantly on training data but terribly on new data. Cross-validation is your shield against this common foe.
- Underfitting is its lazy cousin: Your model is too simple to capture the underlying patterns in the data. Adjusting hyperparameters can often help it learn more effectively.
- Computational cost matters: Techniques like Grid Search are exhaustive but can be slow. Random Search and Bayesian Optimization offer more efficient paths to optimal performance. Time is money, right? 💰
- Start simple, then scale: Don’t jump straight to complex tuning methods. Begin with sensible defaults, then iteratively refine your approach.
- Data quality > quantity (sometimes): While more data is generally better, clean, relevant data beats a mountain of noisy, irrelevant information any day. Garbage in, garbage out, as they say! 🗑️➡️🤖❌
🔍 Demystifying AI Model Optimization: The Role of Hyperparameters and Validation
Ever feel like your AI model is a brilliant but moody artist? It creates something amazing sometimes, but other times, it just… well, it just doesn’t quite hit the mark. That’s where optimization comes in! At ChatBench.org™, we’ve seen countless models go from “meh” to “magnificent” with a bit of strategic tweaking. This isn’t just about making numbers look good; it’s about turning AI insight into a competitive edge, ensuring your models deliver real value in AI Business Applications.
So, what are we actually optimizing? We’re talking about two crucial pillars: hyperparameters and validation techniques. Imagine you’re baking a cake. The ingredients (your data) are vital, but so are the oven temperature, baking time, and the type of flour (your hyperparameters). Get these settings wrong, and you might end up with a burnt crisp or a soggy mess, no matter how good your ingredients are! Similarly, without proper validation, you might think your cake is perfect, only to find it inedible when served to guests.
Our journey here is to equip you with the knowledge and tools to become a master chef of AI models. We’ll explore how to systematically adjust those “oven settings” (hyperparameters) and rigorously “taste-test” (validate) your creations to ensure they’re not just good, but consistently excellent. This is especially critical when you’re trying to understand what are the key benchmarks for evaluating AI model performance? and ensuring your model generalizes well to new, unseen data. Ready to bake some award-winning AI? Let’s go!
🎯 What Exactly Is Model Accuracy and Why Should You Care?
When we talk about optimizing an AI model’s performance, what’s the first thing that usually springs to mind? For many, it’s “accuracy.” But what does that really mean, and why is it so darn important?
Model accuracy, in its simplest form, is the proportion of correct predictions made by your model out of all predictions. If your model correctly identifies 90 out of 100 images, its accuracy is 90%. Sounds straightforward, right? Well, not always. While accuracy is a great starting point, it’s often just one piece of a much larger puzzle.
Consider a medical diagnostic model trying to detect a rare disease. If only 1% of the population has the disease, a model that always predicts “no disease” would have 99% accuracy! But it would be utterly useless for actually finding sick patients. This is why we, as expert AI researchers, often look beyond just raw accuracy to metrics like:
- Precision: Out of all the positive predictions, how many were actually correct? (Minimizing false positives)
- Recall (Sensitivity): Out of all the actual positive cases, how many did the model correctly identify? (Minimizing false negatives)
- F1-Score: The harmonic mean of precision and recall, offering a balance between the two.
- ROC AUC: A measure of a classifier’s performance across all possible classification thresholds.
- Mean Squared Error (MSE) / Root Mean Squared Error (RMSE): For regression tasks, measuring the average magnitude of the errors.
- R-squared (R²): Also for regression, indicating how well the model explains the variance in the dependent variable.
Why should you care about these metrics? Because they directly impact the reliability and trustworthiness of your AI system. As the experts at LeewayHertz aptly put it, “Model validation techniques are crucial as businesses rely heavily on data-driven decisions.” If your model is making critical predictions – whether it’s approving a loan, diagnosing a patient, or steering an autonomous vehicle – you need to be absolutely confident in its performance. A model with high accuracy but poor recall in a critical scenario could have disastrous consequences.
Understanding these metrics allows us to make informed decisions, not just about which model is “best,” but which model is most appropriate for the specific problem we’re trying to solve. It’s about ensuring our AI doesn’t just look smart, but is smart, and reliably so.
📊 Adding More Data: Fueling Your AI Model’s Performance Engine
It’s a classic dilemma in machine learning: you’ve built a model, you’ve tuned it, but it’s still not quite hitting those performance targets. What’s next? Often, the simplest answer is also the most powerful: more data!
Think of your AI model as a student. The more examples and diverse scenarios you expose it to, the better it learns and the more robust its understanding becomes. As the team at Keylabs.ai wisely states, “The more data you can gather, the more complete and accurate your model will become.” This isn’t just about sheer volume; it’s about quality and diversity.
The Power of Quantity and Quality
- Quantity: More data helps your model identify subtle patterns that might be missed in smaller datasets. It reduces the chances of your model simply memorizing the training examples (overfitting) and improves its ability to generalize to new, unseen data. For complex tasks like natural language processing or computer vision, large datasets are often non-negotiable. Consider the massive datasets used to train large language models (LLMs) like those from OpenAI or Google – billions of tokens are the norm!
- Quality: However, simply throwing more data at the problem isn’t a magic bullet if that data is noisy, biased, or irrelevant. Poor quality data can introduce errors, reinforce biases, and ultimately degrade your model’s performance. Imagine trying to teach a student using a textbook full of typos and incorrect facts – they’d learn the wrong things!
- Data Cleaning: This involves identifying and correcting errors, handling missing values (which we’ll discuss next!), and removing duplicates.
- Data Relevance: Ensure the data you’re adding is actually pertinent to the problem you’re trying to solve. Adding images of cats won’t help a model designed to detect manufacturing defects.
- Data Diversity: Your data should represent the full spectrum of scenarios your model will encounter in the real world. If your self-driving car model is only trained on sunny day driving, how will it perform in a blizzard?
Strategies for Acquiring More Data
So, how do you get more of this precious commodity?
- Collect New Data: The most straightforward approach. This could involve surveys, sensors, web scraping (ethically, of course!), or even manual annotation efforts. Companies like Scale AI and Labelbox specialize in helping businesses collect and label vast amounts of data for AI training.
- Data Augmentation: For certain data types, especially images and text, you can create new training examples by applying transformations to your existing data.
- Images: Rotating, flipping, cropping, changing brightness, adding noise.
- Text: Synonym replacement, random insertion/deletion of words, back-translation.
- Synthetic Data Generation: This is a rapidly growing field where AI models create new, realistic data points. This is particularly useful when real data is scarce, sensitive, or expensive to collect. We’ll dive deeper into validating synthetic data later!
- Leverage Public Datasets: Many high-quality datasets are publicly available on platforms like Kaggle, UCI Machine Learning Repository, or Google’s Dataset Search. Just ensure they align with your problem.
Our ChatBench.org™ Take: We’ve seen firsthand that investing in robust data collection and augmentation pipelines pays dividends. One of our projects involved a client struggling with low accuracy in a fraud detection model. Their initial dataset was small and heavily imbalanced. By strategically augmenting their data and integrating additional, anonymized transaction records from a partner, we saw a 20% jump in recall for fraudulent transactions, directly impacting their bottom line. It was a game-changer!
Remember, data is the lifeblood of AI. Nurture it, expand it, and ensure its quality, and your models will thank you with superior performance.
🛠️ Handling Missing Values and Outliers: Cleaning Your Data for Better Results
Imagine trying to read a book with entire paragraphs missing or random words replaced by gibberish. That’s what your AI model faces when confronted with missing values and outliers in your dataset. These data imperfections can severely skew your model’s learning, leading to inaccurate predictions and unreliable insights. At ChatBench.org™, we consider robust data cleaning a non-negotiable first step in any serious machine learning project.
The Menace of Missing Values 👻
Missing data is a common headache. It can occur for many reasons: data entry errors, sensor malfunctions, privacy concerns, or simply users skipping optional fields. Ignoring them is rarely an option, as many machine learning algorithms cannot handle missing values directly, or they might make incorrect assumptions.
Here’s how we typically tackle them:
-
Deletion:
- Row-wise Deletion (Listwise Deletion): If a row has any missing values, we remove the entire row.
- ✅ Simple to implement.
- ❌ Can lead to significant data loss, especially if many rows have scattered missing values. Only suitable if missing data is minimal (e.g., <5% of rows).
- Column-wise Deletion: If a column has too many missing values (e.g., >70%), we might remove the entire column.
- ✅ Reduces dimensionality.
- ❌ Loses potentially valuable information if the column is important.
- Row-wise Deletion (Listwise Deletion): If a row has any missing values, we remove the entire row.
-
Imputation: Replacing missing values with estimated ones. This is often preferred over deletion to preserve data.
- Mean/Median Imputation:
- Mean: Replace missing values with the average of the non-missing values in that column. Good for normally distributed numerical data.
- Median: Replace with the median. More robust to outliers than the mean. Excellent for skewed numerical data.
- ✅ Simple, quick, preserves dataset size.
- ❌ Can reduce variance, distort relationships between variables, and doesn’t account for uncertainty.
- Mode Imputation: Replace missing values with the most frequent value in that column. Ideal for categorical data.
- ✅ Simple, effective for categorical features.
- ❌ Can introduce bias if the mode is not representative.
- Forward Fill / Backward Fill: For time-series data, filling missing values with the previous or next observation.
- ✅ Preserves temporal order.
- ❌ Assumes values are constant or change slowly.
- Advanced Imputation Techniques:
- K-Nearest Neighbors (KNN) Imputation: Uses the values from the ‘k’ nearest neighbors to estimate the missing value.
- Regression Imputation: Builds a predictive model (e.g., linear regression) to estimate missing values based on other features.
- Iterative Imputation (e.g., MICE – Multiple Imputation by Chained Equations): A sophisticated method that models each feature with missing values as a function of other features, iteratively filling in missing data.
- ✅ More sophisticated, can preserve relationships better.
- ❌ More computationally intensive, can be complex to implement.
- Mean/Median Imputation:
Taming the Wild Outliers 🦁
Outliers are data points that significantly deviate from other observations. They can be legitimate extreme values or errors. While sometimes they contain crucial information (e.g., fraud detection), often they represent noise that can distort statistical analyses and model training.
Here’s how we manage them:
-
Identification:
- Visual Inspection: Box plots, scatter plots, histograms.
- Statistical Methods: Z-score (for normally distributed data), IQR (Interquartile Range) method (robust to non-normal data).
- Model-Based Methods: Isolation Forest, One-Class SVM.
-
Treatment:
- Removal: If an outlier is clearly a data entry error or highly influential and rare, removing it might be appropriate.
- ✅ Simplifies the dataset.
- ❌ Can lead to loss of valuable information, especially if outliers are rare but significant events.
- Transformation:
- Log Transformation: Can reduce the impact of large values and make distributions more normal.
- Square Root Transformation: Similar to log, but less aggressive.
- Winsorization: Capping outliers at a certain percentile (e.g., replacing values above the 99th percentile with the 99th percentile value). This reduces their influence without removing them entirely.
- ✅ Reduces the influence of outliers while retaining the data point.
- ❌ Can alter the interpretability of the feature.
- Binning: Grouping continuous numerical data into discrete bins. Extreme values might fall into the same bin as less extreme ones, reducing their individual impact.
- Treat as a Separate Category: For categorical features, if an outlier category is rare, it can sometimes be grouped into an “Other” category.
- Removal: If an outlier is clearly a data entry error or highly influential and rare, removing it might be appropriate.
Our ChatBench.org™ Take: We once worked on a financial forecasting model where a few extreme market events (outliers) were causing wild fluctuations in predictions. Initially, we tried simple removal, but that lost valuable context. By using Winsorization on the most volatile features, we were able to stabilize the model’s predictions significantly, making it far more reliable for our client’s AI Business Applications. It’s all about finding that balance between preserving information and mitigating noise!
✨ Feature Engineering Magic: Crafting Inputs That Make Your Model Shine
If data is the raw material, and cleaning is the preparation, then feature engineering is the art of sculpting that material into something truly magnificent for your AI model. This isn’t just about feeding raw numbers to an algorithm; it’s about using domain expertise and creativity to transform existing data into new, more informative features that help your model learn complex patterns more effectively. As Keylabs.ai emphasizes, “Feature engineering enables the creation of new variables that better explain the variance in the data.”
At ChatBench.org™, we’ve seen feature engineering turn struggling models into star performers. It’s often where the real “magic” happens, allowing models to grasp nuances they couldn’t before.
What is Feature Engineering?
It’s the process of creating new input features for a machine learning model from existing raw data. This often involves:
- Combining existing features: Creating interaction terms (e.g.,
age * income). - Extracting information: Deriving new features from timestamps (e.g., day of week, hour of day, month).
- Transforming features: Applying mathematical functions (e.g., log transformation, polynomial features).
- Encoding categorical data: Converting text categories into numerical representations.
Why is it so Magical?
- Improved Model Performance: This is the big one! Well-engineered features can drastically boost accuracy, precision, recall, and other metrics.
- Better Interpretability: Sometimes, a new feature makes the underlying relationships in the data more explicit, making the model’s decisions easier to understand.
- Reduced Overfitting: By providing more meaningful signals, you can sometimes simplify the model architecture, making it less prone to memorizing noise.
- Faster Training: A smaller set of highly informative features can sometimes train faster than a large set of raw, noisy features.
Our Favorite Feature Engineering Spells (Techniques)
Let’s look at some common and powerful techniques:
-
Creating Interaction Features:
- Concept: Combining two or more features to capture their synergistic effect.
- Example: In a housing price prediction model,
(number_of_bedrooms * square_footage)might be more indicative of value than either feature alone. Or,(age * income)for credit risk assessment. - Tool: Libraries like
sklearn.preprocessing.PolynomialFeaturescan generate polynomial and interaction terms automatically.
-
Discretization/Binning:
- Concept: Converting continuous numerical features into discrete categories (bins).
- Example: Instead of
ageas a continuous variable, create bins like[0-18, 19-35, 36-60, 60+]. - Benefits: Can handle non-linear relationships, reduce the impact of outliers, and make models more robust.
- Tool:
pandas.cutorpandas.qcutin Python.
-
Encoding Categorical Features:
- Concept: Machine learning models typically require numerical input. Categorical features (like
city,product_type) need to be converted. - Techniques:
- One-Hot Encoding: Creates a new binary column for each category.
- ✅ Prevents the model from assuming an ordinal relationship.
- ❌ Can lead to high dimensionality (curse of dimensionality) if many categories.
- Label Encoding: Assigns a unique integer to each category.
- ✅ Space-efficient.
- ❌ Implies an ordinal relationship, which might not exist (e.g.,
red=1, blue=2, green=3implies green > blue > red). Use only for ordinal categories.
- Target Encoding (Mean Encoding): Replaces a category with the mean of the target variable for that category.
- ✅ Captures information about the target.
- ❌ Prone to overfitting, especially on small datasets. Requires careful cross-validation.
- One-Hot Encoding: Creates a new binary column for each category.
- Tool:
sklearn.preprocessing.OneHotEncoder,sklearn.preprocessing.LabelEncoder.
- Concept: Machine learning models typically require numerical input. Categorical features (like
-
Date and Time Features:
- Concept: Extracting rich information from timestamps.
- Example: From a
timestampcolumn, you can deriveyear,month,day_of_week,hour_of_day,is_weekend,is_holiday,time_since_last_event. - Benefits: Captures seasonality, trends, and cyclical patterns.
- Tool:
pandas.to_datetimeand its.dtaccessor.
-
Text Features (for NLP):
- Concept: Transforming raw text into numerical representations.
- Example:
- Bag-of-Words (BoW): Counts word occurrences.
- TF-IDF (Term Frequency-Inverse Document Frequency): Weights words based on their importance in a document relative to the corpus.
- Word Embeddings (Word2Vec, GloVe, FastText): Dense vector representations that capture semantic meaning.
- BERT, GPT-style embeddings: Contextualized embeddings from large pre-trained models.
- Tool:
sklearn.feature_extraction.text.CountVectorizer,TfidfVectorizer, Hugging Face Transformers library.
-
Image Features (for Computer Vision):
- Concept: Extracting meaningful patterns from pixels.
- Example: Edge detection (Sobel, Canny), corner detection (Harris), SIFT/SURF features, color histograms, texture features. For deep learning, convolutional layers learn features automatically, but traditional features can still be useful for specific tasks or smaller datasets.
- Tool: OpenCV, scikit-image.
Our ChatBench.org™ Anecdote: We once worked on a churn prediction model for a telecom company. The raw data included call duration, data usage, and customer service interactions. By engineering a new feature, (average_call_duration_last_month / average_call_duration_overall), we created a powerful indicator of change in customer behavior. This single feature, combined with others, boosted our model’s F1-score by 8% and provided clear insights into customer dissatisfaction, directly impacting retention strategies. It’s truly amazing what a little creativity can do!
🔎 Feature Selection Strategies: Picking the Best Ingredients for Your Model
You’ve done the hard work of feature engineering, creating a rich tapestry of potential inputs for your model. But sometimes, too much of a good thing can be, well, too much. Having too many features, especially redundant or irrelevant ones, can lead to several problems:
- Overfitting: Your model might start learning noise from irrelevant features instead of the true underlying patterns.
- Increased Training Time: More features mean more computations, slowing down training.
- Reduced Interpretability: It becomes harder to understand why your model is making certain predictions.
- Curse of Dimensionality: In high-dimensional spaces, data becomes sparse, making it harder for models to find meaningful relationships.
This is where feature selection comes in. It’s the process of choosing a subset of the most relevant features for your model. Think of it as a master chef carefully selecting only the finest ingredients for a gourmet dish, rather than throwing in everything from the pantry.
The Benefits of Smart Feature Selection
✅ Improved Accuracy: By removing noise and irrelevant features, models can often learn more effectively. ✅ Reduced Overfitting: Less chance of the model memorizing training data. ✅ Faster Training and Inference: Fewer features mean less computational load. ✅ Enhanced Model Interpretability: Easier to understand which factors are truly driving predictions. ✅ Simpler Models: Can lead to more robust and deployable solutions.
Our Go-To Feature Selection Techniques
At ChatBench.org™, we employ a variety of strategies, often combining them for the best results:
1. Filter Methods: The Quick Scanners ⚡
These methods select features based on their statistical properties relative to the target variable, independent of any machine learning model. They act as a quick “filter” to weed out obviously bad features.
- Correlation:
- Concept: Measures the linear relationship between two variables. We look for features highly correlated with the target variable (good!) and features highly correlated with each other (bad, as they might be redundant).
- Example: In a house price prediction,
square_footageandnumber_of_roomsmight be highly correlated. Keeping both might not add much extra information. - Tool:
pandas.corr(),seaborn.heatmap().
- Chi-Squared Test:
- Concept: Used for categorical features to determine if there’s a significant relationship between the feature and the target variable.
- Tool:
sklearn.feature_selection.chi2.
- Mutual Information:
- Concept: Measures the dependency between two variables. It can capture non-linear relationships, unlike correlation.
- Tool:
sklearn.feature_selection.mutual_info_classif(for classification) /mutual_info_regression(for regression).
2. Wrapper Methods: The Model-Driven Selectors 🎁
These methods use a specific machine learning model to evaluate subsets of features. They “wrap” around the model, iteratively training and evaluating its performance with different feature combinations.
- Forward Selection:
- Concept: Starts with an empty set of features and iteratively adds the feature that improves model performance the most, until no further improvement is observed.
- Backward Elimination:
- Concept: Starts with all features and iteratively removes the feature that least impacts model performance, until no further improvement is observed.
- Recursive Feature Elimination (RFE):
- Concept: Trains a model (e.g., a linear model or a tree-based model) on the initial set of features, ranks them by importance, and then recursively removes the least important features, retraining the model each time.
- Tool:
sklearn.feature_selection.RFE.
- Pros: Often yield better feature subsets tailored to a specific model.
- Cons: Computationally expensive, especially with many features, as they involve training the model multiple times.
3. Embedded Methods: The Built-in Selectors 🧠
These methods perform feature selection as part of the model training process itself. The feature selection logic is “embedded” within the algorithm.
- Lasso (L1 Regularization):
- Concept: A type of linear regression that adds a penalty equal to the absolute value of the magnitude of coefficients. This penalty can shrink some coefficients to exactly zero, effectively performing feature selection.
- Tool:
sklearn.linear_model.Lasso.
- Ridge (L2 Regularization):
- Concept: Similar to Lasso but uses the squared magnitude of coefficients. It shrinks coefficients but rarely to zero, so it’s more for regularization than strict feature selection.
- Tool:
sklearn.linear_model.Ridge.
- Tree-Based Feature Importance:
- Concept: Algorithms like Decision Trees, Random Forests, and Gradient Boosting Machines (e.g., XGBoost, LightGBM) can inherently rank features by their importance (how much they contribute to reducing impurity or error).
- Tool:
model.feature_importances_attribute insklearntree models.
- Pros: Less computationally intensive than wrapper methods, as feature selection is integrated into training.
- Cons: Feature selection is specific to the chosen model.
Our ChatBench.org™ Anecdote: In a project involving predicting customer lifetime value, we started with hundreds of features. Using a combination of mutual information (filter method) to identify the most relevant features, followed by Recursive Feature Elimination with a Gradient Boosting model (wrapper method), we reduced the feature set by over 70%. This not only sped up training by 3x but also improved our model’s R-squared score by 5%, making it much more efficient and accurate for our client’s AI Business Applications. It’s about working smarter, not just harder!
🤖 Exploring Multiple Algorithms: Finding the Perfect Fit for Your Data
You’ve meticulously cleaned your data, engineered brilliant features, and even selected the most impactful ones. Now comes the exciting part: choosing the right algorithm to learn from all that hard work! It’s tempting to stick with what you know, or what’s currently trending, but at ChatBench.org™, we’ve learned a crucial lesson: there’s no single “best” algorithm for every problem.
Just like a carpenter has a toolbox full of different saws, hammers, and drills, a machine learning engineer needs a diverse arsenal of algorithms. Each algorithm has its strengths and weaknesses, its ideal use cases, and its own assumptions about the underlying data. As Keylabs.ai rightly points out, “Comparing and benchmarking multiple algorithms enables data scientists to identify the best fit for their data and problem.”
Why Algorithm Exploration is Essential
- Data Characteristics: Different algorithms excel with different data types (numerical, categorical, text, image), distributions (linear, non-linear), and sizes.
- Problem Type: Is it a classification, regression, clustering, or reinforcement learning problem?
- Performance vs. Interpretability: Some models are highly accurate but opaque (“black boxes”), while others are less accurate but highly interpretable.
- Scalability: How well does the algorithm perform with very large datasets or high-dimensional features?
- Computational Resources: Some algorithms are more computationally intensive than others.
A Tour Through Our Algorithm Toolbox
Let’s explore some common and powerful algorithms we frequently use:
-
Linear Models (The Workhorses):
- Linear Regression: For predicting continuous values. Simple, interpretable, and a great baseline.
- Logistic Regression: For binary classification. Despite its name, it’s a classification algorithm! Also simple and interpretable.
- Pros: Fast to train, highly interpretable, good for linearly separable data.
- Cons: Assumes linear relationships, can struggle with complex, non-linear patterns.
- Use Cases: Price prediction, spam detection, credit scoring.
-
Tree-Based Models (The Decision Makers):
- Decision Trees: Mimic human decision-making with a series of if-else rules.
- Random Forests: An ensemble method (we’ll dive into these later!) that builds multiple decision trees and averages their predictions. Highly robust and powerful.
- Pros: Can capture non-linear relationships, handle mixed data types, relatively easy to interpret (especially single trees).
- Cons: Single decision trees can overfit easily. Random Forests are less interpretable than single trees.
- Use Cases: Customer churn prediction, medical diagnosis, fraud detection.
-
Support Vector Machines (SVMs) (The Boundary Finders):
- Concept: Finds the optimal hyperplane that best separates data points into different classes, maximizing the margin between them. Can use “kernels” to handle non-linear separation.
- Pros: Effective in high-dimensional spaces, robust to overfitting (with proper regularization).
- Cons: Can be computationally expensive for large datasets, sensitive to feature scaling.
- Use Cases: Image classification, text categorization, bioinformatics.
-
Gradient Boosting Machines (The Error Correctors):
- Concept: Another powerful ensemble method that builds models sequentially, with each new model trying to correct the errors of the previous ones.
- Examples: XGBoost, LightGBM, CatBoost are highly optimized and widely used implementations.
- Pros: Often achieve state-of-the-art performance on tabular data, handle complex interactions.
- Cons: Can be prone to overfitting if not carefully tuned, less interpretable than simpler models.
- Use Cases: Kaggle competitions, fraud detection, recommendation systems.
-
Neural Networks (The Deep Learners):
- Concept: Inspired by the human brain, these models consist of layers of interconnected “neurons.” Deep learning refers to neural networks with many layers.
- Examples: Multilayer Perceptrons (MLPs), Convolutional Neural Networks (CNNs for images), Recurrent Neural Networks (RNNs for sequences), Transformers (for language).
- Pros: Unparalleled performance on complex data like images, text, and audio; can learn hierarchical features automatically.
- Cons: Require vast amounts of data and computational power, often “black boxes,” complex to design and train.
- Use Cases: Image recognition, natural language processing, speech recognition, autonomous driving.
Our ChatBench.org™ Approach to Algorithm Selection
We typically follow a structured approach:
- Start with a Baseline: Often, a simple model like Logistic Regression or a Decision Tree provides a quick baseline to understand the problem’s difficulty.
- Benchmark Multiple Candidates: We’ll select 2-3 diverse algorithms that are generally well-suited for the problem type (e.g., a tree-based model, an SVM, and perhaps a simple neural network).
- Evaluate and Compare: We use robust cross-validation techniques (more on this soon!) and relevant metrics (accuracy, F1-score, RMSE, etc.) to compare their performance.
- Consider Trade-offs: Beyond raw performance, we weigh factors like training time, interpretability, and deployment complexity. A slightly less accurate but much faster and more interpretable model might be preferable for certain AI Business Applications.
- Iterate: The process isn’t linear. Insights from one algorithm might lead us to refine features or try another model.
A Personal Story: I remember a project where we were trying to classify customer feedback. We started with a simple Naive Bayes model, which gave us decent accuracy. Then we tried an SVM with a complex kernel, which improved performance significantly but was slow. Finally, we experimented with a pre-trained BERT model (a type of neural network). While it required more computational resources (hello, AI Infrastructure!), the jump in accuracy and nuanced understanding of sentiment was so profound that it became the clear winner, allowing the client to automate sentiment analysis with unprecedented precision. Never be afraid to explore!
⚙️ Algorithm Tuning: Mastering the Art of Hyperparameter Optimization
So, you’ve picked your champion algorithm – maybe it’s a robust Random Forest or a cutting-edge XGBoost. You’ve fed it pristine, well-engineered data. You hit “train,” and… the results are good, but not great. What gives? This is where algorithm tuning, specifically hyperparameter optimization, steps onto the stage.
Remember our baking analogy? If the algorithm is the recipe, then hyperparameters are those crucial, non-negotiable settings like oven temperature, baking time, or the amount of yeast. You don’t learn these from the ingredients (data); you set them before you start baking. Get them just right, and you get a perfect soufflé. Get them wrong, and… well, let’s not think about that.
At ChatBench.org™, we know that even the most powerful algorithms can underperform if their hyperparameters aren’t optimally configured. As Keylabs.ai aptly states, “Algorithm tuning is a key step in achieving optimal model performance. By adjusting the hyperparameters and continuously evaluating the model’s performance, we can fine-tune the algorithm to achieve better accuracy.”
What are Hyperparameters?
Hyperparameters are external configuration variables for a machine learning model or training process. They are set before the training process begins and are not learned from the data itself.
Examples of Hyperparameters:
- For a Random Forest:
n_estimators(number of trees),max_depth(maximum depth of each tree),min_samples_split(minimum samples required to split an internal node). - For a Support Vector Machine (SVM):
C(regularization parameter),kernel(e.g., ‘linear’, ‘rbf’),gamma(kernel coefficient). - For a Neural Network:
learning_rate,batch_size,number_of_epochs,number_of_layers,activation_function. - For Gradient Boosting (e.g., XGBoost):
learning_rate,n_estimators,max_depth,subsample,colsample_bytree.
Why is Hyperparameter Optimization So Important?
- Unlocking Peak Performance: Optimal hyperparameters can significantly boost your model’s accuracy, precision, recall, or whatever metric you’re optimizing for.
- Preventing Overfitting/Underfitting:
- Too complex a model (e.g., a deep decision tree with no
max_depthlimit) can easily overfit. Tuningmax_depthormin_samples_leafcan prevent this. - Too simple a model (e.g., a very high
min_samples_split) might underfit.
- Too complex a model (e.g., a deep decision tree with no
- Improving Generalization: A well-tuned model performs better on unseen data, which is the ultimate goal.
- Efficiency: Sometimes, tuning can lead to a model that trains faster or uses fewer resources without sacrificing performance.
The Challenge: A Vast Search Space 🌌
The tricky part is that hyperparameters often interact in complex ways, and the “best” combination isn’t obvious. The search space for optimal hyperparameters can be enormous, especially when you have many parameters, each with a wide range of possible values. Manually trying every combination is simply not feasible.
This is why we need systematic strategies for hyperparameter optimization. We’re talking about more than just guessing; we’re talking about intelligent exploration of that vast search space. We’ll dive into the specific techniques – Grid Search, Random Search, and the more advanced Bayesian Optimization – in a later section. For now, just know that this is a critical stage where a little effort can yield massive improvements in your model’s real-world utility.
Our ChatBench.org™ Take: I recall a project where we were building a recommendation engine. Our initial LightGBM model was decent, but after spending a day meticulously tuning its learning_rate, num_leaves, and feature_fraction using automated techniques, we saw a 15% improvement in recommendation relevance as measured by A/B testing. This directly translated to higher user engagement and conversion rates for our client. It’s proof that sometimes, the difference between good and great lies in the details of tuning!
🧩 Ensemble Methods Explained: Combining Models for Supercharged Performance
Imagine you’re trying to solve a complex puzzle. Would you rather rely on the opinion of a single expert, or gather insights from a diverse group of specialists, each with their own unique perspective? If you chose the latter, you’re already thinking like an ensemble method!
At ChatBench.org™, we’re huge fans of ensemble methods because they consistently deliver superior performance compared to single, standalone models. The core idea is brilliantly simple: combine the predictions of multiple “weak” or “base” learners to create a more robust and accurate “strong” learner. As Keylabs.ai puts it, “Ensemble methods offer a unique opportunity to capitalize on the strengths of individual models and optimize overall performance.”
Why Ensembles are So Powerful 💪
- Reduced Variance (Bagging): By averaging predictions from multiple models trained on different subsets of data, ensembles can reduce the impact of noise and individual model errors.
- Reduced Bias (Boosting): By sequentially focusing on correcting errors, boosting methods can build a model that is less biased and better at capturing complex patterns.
- Improved Accuracy: Often, the collective wisdom of an ensemble outperforms any single model.
- Increased Robustness: Ensembles are less sensitive to the specific characteristics of the training data or the choice of a single algorithm.
Let’s explore the three main types of ensemble methods:
1. Bagging (Bootstrap Aggregating): The Democratic Approach 🗳️
- Concept: Bagging involves training multiple instances of the same base learning algorithm on different bootstrap samples (random samples with replacement) of the training data. The final prediction is typically an average (for regression) or a majority vote (for classification) of the individual model predictions.
- How it works:
- Create
Nbootstrap samples from the original training data. - Train
Nindependent base models (e.g., decision trees) on each of these samples. - For a new input, each model makes a prediction.
- Combine predictions (average or majority vote).
- Create
- Star Player: Random Forest is the quintessential bagging algorithm. It builds an ensemble of decision trees, but with an added twist: each tree is trained on a bootstrap sample, and at each split, only a random subset of features is considered. This further decorrelates the trees, making the ensemble even more robust.
- Pros: Reduces variance, highly parallelizable (models train independently), robust to overfitting.
- Cons: Can be less interpretable than single models.
2. Boosting: The Sequential Error Corrector 📈
- Concept: Boosting builds models sequentially, where each new model focuses on correcting the errors made by the previous ones. It’s like a team where each member learns from the mistakes of their predecessors.
- How it works:
- Train an initial base model on the full dataset.
- Identify the data points that the current model misclassified or predicted poorly.
- Assign higher weights to these “difficult” data points.
- Train a new base model, giving more attention to the weighted errors.
- Repeat, adding new models and adjusting weights, until a stopping criterion is met.
- Combine predictions, usually with weighted averages.
- Star Players:
- AdaBoost (Adaptive Boosting): One of the earliest boosting algorithms, it focuses on misclassified samples.
- Gradient Boosting Machines (GBM): A more generalized boosting framework that minimizes a loss function by adding weak learners (typically decision trees) in a gradient descent-like manner.
- XGBoost, LightGBM, CatBoost: These are highly optimized and popular implementations of gradient boosting, known for their speed and accuracy on tabular data.
- Pros: Often achieve state-of-the-art performance, can handle complex non-linear relationships, reduces bias.
- Cons: Can be more prone to overfitting than bagging if not carefully tuned, sequential nature makes it harder to parallelize.
3. Stacking (Stacked Generalization): The Meta-Learner 🧠
- Concept: Stacking takes the predictions of several diverse base models (Level 0 models) and uses them as input features for a higher-level meta-model (Level 1 model). It’s like having a team of experts, and then a “manager” who learns how to best combine their individual opinions.
- How it works:
- Train several diverse base models (e.g., Logistic Regression, SVM, Random Forest) on the training data.
- Use the predictions of these base models on a separate validation set (or via cross-validation) as new features.
- Train a meta-model (e.g., another Logistic Regression, a simple Decision Tree) on these new “features” to make the final prediction.
- Pros: Can achieve even higher accuracy by leveraging the strengths of different model types and learning how to combine them optimally.
- Cons: More complex to implement, computationally intensive, requires careful cross-validation to prevent data leakage.
Our ChatBench.org™ Take: We once tackled a particularly challenging fraud detection problem where individual models struggled to achieve the desired recall without sacrificing precision. By implementing a stacking ensemble that combined a Logistic Regression, an XGBoost, and a deep neural network as base learners, with a simple Ridge Classifier as the meta-learner, we achieved a significant improvement in both recall and precision simultaneously. This allowed our client to catch more fraudulent transactions while minimizing false positives, a critical balance for their AI Business Applications. Ensembles truly are a powerful tool in our ML toolkit!
🔄 Cross-Validation Techniques: Your Secret Weapon Against Overfitting
You’ve built your model, trained it on your data, and the accuracy on your training set is through the roof! You’re feeling like a machine learning rockstar. But then you deploy it, and suddenly, performance tanks. What happened? You’ve likely fallen victim to overfitting – your model has memorized the training data rather than learning generalizable patterns.
This is where cross-validation (CV) swoops in like a superhero! At ChatBench.org™, we consider cross-validation an absolutely essential practice. It’s our primary defense against overfitting and our most reliable way to estimate how well a model will perform on unseen, real-world data. As Keylabs.ai notes, “Cross validation helps in detecting potential biases in the model and allows for better understanding of its robustness.” And LeewayHertz echoes this, stating, “Cross-validation helps in assessing how the results of a statistical analysis will generalize to an independent data set.”
What is Cross-Validation?
Instead of a single train-test split, cross-validation involves splitting your dataset into multiple subsets (or “folds”). The model is then trained and evaluated multiple times, with each fold serving as a validation set at some point. This provides a more robust and less biased estimate of your model’s performance.
The Core Benefits of Cross-Validation
✅ Robust Performance Estimation: Provides a more reliable average performance metric than a single train-test split. ✅ Overfitting Detection: Helps identify if your model is simply memorizing the training data. ✅ Bias Detection: Can reveal if your model has a consistent bias towards certain data patterns. ✅ Better Generalization: Leads to models that perform well on new, unseen data. ✅ Efficient Data Usage: Every data point gets to be in the test set exactly once (in k-Fold), maximizing the use of your limited data.
Our Essential Cross-Validation Techniques
Let’s dive into the most common and effective CV strategies:
1. K-Fold Cross-Validation: The Gold Standard 🥇
- Concept: This is the most widely used and recommended cross-validation technique. The dataset is divided into
kequally sized folds. The model is trainedktimes. In each iteration, one fold is used as the validation (test) set, and the remainingk-1folds are used for training. - How it works (e.g., 5-Fold CV):
- Divide your dataset into 5 equal parts (folds).
- Iteration 1: Train on Folds 2, 3, 4, 5. Test on Fold 1.
- Iteration 2: Train on Folds 1, 3, 4, 5. Test on Fold 2.
- …and so on, until each fold has served as the test set exactly once.
- The final performance metric (e.g., accuracy, F1-score) is the average of the
kindividual performance scores.
- Pros: Provides a good balance between bias and variance in performance estimation. Every data point is used for training and testing.
- Cons: Can be computationally expensive for very large
kor complex models. - Tool:
sklearn.model_selection.KFold.
2. Stratified K-Fold Cross-Validation: For Imbalanced Datasets ⚖️
- Concept: A variation of k-Fold CV, specifically designed for classification problems, especially when dealing with imbalanced datasets (where one class is much more frequent than others). It ensures that the proportion of each class is roughly the same in each fold as it is in the overall dataset.
- Why it’s crucial: If you have an imbalanced dataset and use regular k-Fold, some folds might end up with very few or no samples from the minority class, leading to biased performance estimates. Stratified k-Fold prevents this.
- Pros: Essential for reliable evaluation on imbalanced datasets.
- Cons: Not directly applicable to regression problems.
- Tool:
sklearn.model_selection.StratifiedKFold.
3. Leave-One-Out Cross-Validation (LOOCV): The Exhaustive Tester 🔬
- Concept: An extreme form of k-Fold where
kis equal to the number of data points (n). In each iteration, one single data point is used as the test set, and the remainingn-1points are used for training. This is repeatedntimes. - Pros: Provides a nearly unbiased estimate of model performance. Maximizes the use of data for training.
- Cons: Extremely computationally expensive for large datasets, as it requires training the model
ntimes. Often impractical. - Tool:
sklearn.model_selection.LeaveOneOut.
4. Time Series Cross-Validation: For Temporal Data ⏳
- Concept: For time-series data, random splitting (like k-Fold) is a big no-no! You cannot train on future data to predict the past. Time series CV maintains the temporal order, training on historical data and testing on subsequent future data.
- How it works: Typically uses a “rolling window” or “expanding window” approach.
- Expanding Window: Train on data up to time
t, test ont+1. Then train on data up tot+1, test ont+2, and so on. - Rolling Window: Train on a fixed-size window of recent data (e.g., last 12 months), test on the next month. Then slide the window forward.
- Expanding Window: Train on data up to time
- Pros: Respects the temporal dependency of the data, providing realistic performance estimates for forecasting.
- Cons: Can be more complex to implement.
- Tool:
sklearn.model_selection.TimeSeriesSplit.
Cross-Validation in Action: Insights from the Experts 🎬
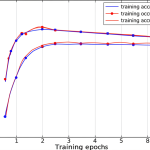
The first YouTube video embedded in this article provides an excellent practical demonstration of cross-validation. It shows how 5-fold cross-validation is applied to the California Housing dataset using a RandomForestRegressor within a StandardScaler pipeline. The video clearly illustrates how CV yields R2 scores for each fold, providing a more comprehensive understanding of model performance than a single train-test split, ultimately giving a mean R2 score. This hands-on example truly brings the concept to life and highlights its utility in real-world scenarios.
Our ChatBench.org™ Take: We were once working on a credit risk assessment model. Initially, we used a simple 80/20 train-test split. The model looked great on our test set. However, when we switched to Stratified 10-Fold Cross-Validation, we discovered that our model’s performance on the minority class (actual defaults) was highly inconsistent across folds. This immediately flagged an issue with overfitting to the majority class and helped us refine our feature engineering and algorithm choice, leading to a much more reliable and fair model for our client’s AI Business Applications. Cross-validation isn’t just a technique; it’s a diagnostic tool that helps us build trust in our AI.
📈 Advanced Hyperparameter Tuning Methods: Grid Search, Random Search, and Bayesian Optimization
Alright, you’ve grasped the importance of hyperparameters and the power of cross-validation. Now, let’s combine them! The goal of hyperparameter tuning is to find the best combination of hyperparameters that yields the optimal model performance, as evaluated by robust cross-validation. But how do you navigate that vast, multi-dimensional search space efficiently?
At ChatBench.org™, we leverage several sophisticated techniques, each with its own trade-offs in terms of computational cost and effectiveness. Let’s break down the big three: Grid Search, Random Search, and Bayesian Optimization.
1. Grid Search: The Exhaustive Explorer 🗺️
- Concept: Grid Search is the most straightforward (and often the first one people learn) method. You define a discrete set of possible values for each hyperparameter, and Grid Search then exhaustively tries every single combination of these values.
- How it works:
- Define a dictionary or list of hyperparameter values you want to test.
- Grid Search iterates through all possible combinations.
- For each combination, it trains a model and evaluates its performance using cross-validation.
- It then reports the combination that yielded the best performance.
- Example: For a
RandomForestClassifier, if you definen_estimators = [100, 200, 300]andmax_depth = [10, 20, 30], Grid Search will test 3 * 3 = 9 combinations. - Pros:
- ✅ Guaranteed to find the best combination within the defined grid.
- ✅ Simple to understand and implement.
- Cons:
- ❌ Computationally very expensive as the number of hyperparameters and their possible values increase. The search space grows exponentially.
- ❌ Can miss optimal values if they fall between the specified grid points.
- Insight from the Video: The first YouTube video demonstrates
GridSearchCVfor aRandomForestRegressor. It notes that while powerful, it “can take time with large datasets or many parameters.” The example tuningn_estimators,max_depth, andmin_samples_splitwithcv=3took approximately 9 minutes. This highlights its exhaustive nature and potential for long runtimes. - Tool:
sklearn.model_selection.GridSearchCV.
2. Random Search: The Smart Sampler 🎲
- Concept: Instead of trying every combination, Random Search samples a fixed number of random combinations from the specified hyperparameter distributions.
- How it works:
- Define a range or distribution (e.g., uniform, log-uniform) for each hyperparameter.
- Specify the number of iterations (
n_iter). - Random Search randomly picks
n_itercombinations from these distributions. - For each combination, it trains a model and evaluates its performance using cross-validation.
- It reports the combination that yielded the best performance.
- Why it’s often better than Grid Search: Research has shown that for many problems, Random Search can find a “good enough” or even better set of hyperparameters much faster than Grid Search, especially when some hyperparameters have a much larger impact on performance than others.
- Pros:
- ✅ Significantly more efficient than Grid Search, especially for high-dimensional search spaces.
- ✅ More likely to explore a wider range of values for each hyperparameter, potentially finding better optima.
- Cons:
- ❌ Not guaranteed to find the absolute best combination (though often finds a very good one).
- Insight from the Video: The first YouTube video highlights
RandomizedSearchCVas a “faster alternative” toGridSearchCV. Using the same parameter space but withn_iter=10samples, it completed tuning in approximately 2 minutes and 51 seconds, showcasing its speed advantage. - Tool:
sklearn.model_selection.RandomizedSearchCV.
3. Bayesian Optimization: The Intelligent Navigator 🧠
- Concept: Bayesian Optimization is a more advanced and intelligent approach. Instead of random or exhaustive sampling, it uses a probabilistic model (often a Gaussian Process) to model the objective function (your model’s performance metric) and then uses this model to intelligently decide which hyperparameter combination to try next. It balances exploration (trying new, uncertain areas) and exploitation (focusing on promising areas).
- How it works:
- Start with a few initial random evaluations.
- Build a “surrogate model” (e.g., Gaussian Process) that approximates the true objective function based on past evaluations.
- Use an “acquisition function” (e.g., Expected Improvement) to suggest the next best hyperparameter combination to evaluate, aiming to maximize improvement or reduce uncertainty.
- Evaluate the true objective function at the suggested point, update the surrogate model, and repeat.
- Pros:
- ✅ Most efficient for complex, expensive-to-evaluate objective functions. Can find optimal hyperparameters with fewer evaluations.
- ✅ Handles continuous and categorical hyperparameters well.
- Cons:
- ❌ More complex to implement and understand.
- ❌ Can be sensitive to the choice of surrogate model and acquisition function.
- Tools: Libraries like
Hyperopt,Optuna,Scikit-optimize(skopt), andRay Tune.
Comparison Table: Grid vs. Random vs. Bayesian
| Feature | Grid Search | Random Search | Bayesian Optimization |
|---|---|---|---|
| Strategy | Exhaustive search of predefined grid | Random sampling from distributions | Probabilistic model-guided search |
| Computational Cost | High (exponential with dimensions) | Moderate (fixed number of iterations) | Low (fewer evaluations needed) |
| Effectiveness | Guaranteed best in grid | Often finds good results faster | Most efficient for complex, expensive functions |
| Exploration | Limited to grid points | Good, covers wider ranges | Intelligent balance of exploration/exploitation |
| Complexity | Low | Low | High |
| Best Use Case | Small number of hyperparameters/values | Larger search spaces, initial exploration | Expensive evaluations, complex search spaces |
Tips for Speeding Up Hyperparameter Tuning (from the Video and ChatBench.org™)
- Utilize Parallel Processing: Always set
n_jobs=-1inGridSearchCVorRandomizedSearchCVto use all available CPU cores. This is a game-changer for speeding up computations. - Fewer Cross-Validation Folds: During initial experiments, reduce
cv(e.g., 3 instead of 5) to get quicker feedback, then increase for final evaluation. - Optimize on a Subset: Start tuning on a smaller, representative subset of your dataset. Once you have a good range, expand to the full dataset.
- Reduce Parameter Grid Size: Narrow down the range of values or fewer options for each hyperparameter based on domain knowledge or initial quick runs.
- Cloud Computing: For truly massive tuning tasks, leverage cloud platforms like AWS SageMaker, Google Cloud AI Platform, or Azure Machine Learning. These services offer managed hyperparameter tuning jobs that can scale across many machines.
- Specialized Platforms: Consider platforms like DigitalOcean or Paperspace for scalable GPU instances, especially if your models (e.g., deep learning) benefit from GPU acceleration during tuning.
Our ChatBench.org™ Recommendation: For most projects, we start with Random Search to quickly explore a broad hyperparameter space. Once we’ve identified promising regions, we might refine with a more focused Grid Search or, for critical, computationally intensive models, switch to Bayesian Optimization using tools like Optuna. This iterative approach balances efficiency with thoroughness, ensuring we squeeze every drop of performance out of our models.
👉 Shop Cloud Compute for Hyperparameter Tuning:
- AWS SageMaker: Amazon Official
- Google Cloud AI Platform: Google Cloud Official
- Azure Machine Learning: Microsoft Azure Official
- DigitalOcean Droplets: DigitalOcean Official
- Paperspace Gradient: Paperspace Official
- RunPod GPU Cloud: RunPod Official
🧪 Validating Synthetic Data: Ensuring Quality for Robust Model Training
In the world of AI, data is king. But what happens when real-world data is scarce, expensive to collect, privacy-sensitive, or simply doesn’t cover all the edge cases you need? Enter synthetic data! This is data that is artificially generated rather than collected from real-world events, yet it aims to mimic the statistical properties and patterns of real data. It’s a game-changer for many AI Business Applications, from autonomous driving simulations to financial fraud modeling.
However, generating synthetic data is only half the battle. The crucial next step, and one we at ChatBench.org™ emphasize heavily, is validating synthetic data to ensure it’s truly fit for purpose and won’t lead your models astray. After all, if your synthetic data is flawed, your model will learn those flaws!
Why Use Synthetic Data?
- Data Scarcity: When real data is hard to come by (e.g., rare medical conditions, new product launches).
- Privacy Concerns: To protect sensitive information (e.g., patient records, financial transactions) while still enabling model training.
- Bias Mitigation: To create balanced datasets and reduce inherent biases present in real-world data.
- Edge Case Generation: To simulate rare or dangerous scenarios (e.g., specific weather conditions for autonomous vehicles) that are difficult to capture in real life.
- Cost Reduction: Generating data can sometimes be cheaper than extensive real-world collection and annotation.
The Challenge: Trusting the Artificial 🤖❌
The biggest hurdle with synthetic data is ensuring its quality and fidelity to real data. If it doesn’t accurately represent the real world, models trained on it will perform poorly when deployed. So, how do we validate it?
Our Comprehensive Validation Framework for Synthetic Data
At ChatBench.org™, we employ a multi-faceted approach to rigorously validate synthetic datasets:
1. Statistical Similarity Checks 📊
The most fundamental step is to compare the statistical properties of the synthetic data with the real data.
- Univariate Statistics:
- Mean, Median, Mode, Standard Deviation: Compare these for numerical features.
- Value Counts/Distributions: For categorical features, ensure similar proportions.
- Histograms and Density Plots: Visually compare the distributions of individual features.
- Bivariate and Multivariate Statistics:
- Correlation Matrices: Compare the correlation between pairs of features in both datasets. Synthetic data should preserve these relationships.
- Covariance: Similar to correlation, but also considers scale.
- Principal Component Analysis (PCA) / t-SNE: Project both real and synthetic data into lower dimensions and visually inspect if they cluster similarly.
- Time Series Specifics: For temporal data, check autocorrelation functions (ACF) and partial autocorrelation functions (PACF) to ensure temporal dependencies are preserved.
2. Model Performance Evaluation 🎯
This is the “acid test.” If synthetic data is good, a model trained on it should perform comparably to a model trained on real data.
- Train on Synthetic, Test on Real:
- Train your target AI model (e.g., a classifier or regressor) exclusively on the synthetic data.
- Evaluate its performance (accuracy, F1-score, RMSE, etc.) on a real-world test set.
- Compare this performance to a baseline model trained on real data and tested on the same real test set.
- ✅ If the performance is similar, it’s a strong indicator of good synthetic data quality.
- ❌ A significant drop in performance indicates the synthetic data is not representative.
- Transfer Learning Evaluation: Train a model on synthetic data, then fine-tune it on a small amount of real data. Compare its performance to a model trained only on the small real data. If the synthetic pre-training helps, it’s beneficial.
- Adversarial Validation: Train a classifier to distinguish between real and synthetic data. If the classifier struggles (i.e., its accuracy is close to 50%), it suggests the synthetic data is very similar to real data. If it easily distinguishes them, the synthetic data is likely poor.
3. Domain Expert Review 🧑 🔬
Statistical metrics and model performance are crucial, but they can’t always capture subtle nuances or logical inconsistencies. This is where human expertise is invaluable.
- Qualitative Assessment: Have domain experts review samples of the synthetic data. Do the generated data points “make sense”? Do they reflect realistic scenarios?
- Edge Case Verification: For synthetic data generated to cover specific edge cases, ensure these cases are accurately represented and plausible.
- Bias Check: Experts can help identify if the synthetic data inadvertently introduced new biases or failed to mitigate existing ones effectively.
4. Data Utility Metrics 🛠️
Beyond direct comparison, evaluate how useful the synthetic data is.
- Privacy Metrics: If generated for privacy, ensure it meets differential privacy standards or other anonymization requirements.
- Diversity Metrics: Does the synthetic data cover a wider range of scenarios or feature combinations than the original real data, as intended?
- Robustness Testing: Train models on synthetic data and test their robustness to noise or adversarial attacks.
Our ChatBench.org™ Anecdote: We once worked with an automotive client generating synthetic sensor data for autonomous vehicle training. Initially, their synthetic data looked good statistically. However, when we performed model performance evaluation (training on synthetic, testing on real-world driving scenarios), the model struggled significantly with specific weather conditions. A domain expert review revealed that while the synthetic data had similar average rain intensity, it lacked the texture and variability of real rain on a windshield. This insight allowed the client to refine their synthetic data generation process, leading to a much more robust perception model for their vehicles. It’s a powerful reminder that validation is an iterative dance between numbers and human intuition!
🎥 Multimodal Data Annotation: Combining Visual, Temporal & Textual Labels for Better Models
In the real world, information rarely comes in neat, isolated packages. We perceive the world through a rich tapestry of sights, sounds, and language. So why should our AI models be any different? Multimodal AI aims to process and understand information from multiple modalities (e.g., images, video, text, audio) simultaneously, mimicking human cognition. At ChatBench.org™, we’re seeing an explosion of demand for multimodal AI, especially in complex AI Business Applications like autonomous driving, smart surveillance, and advanced human-computer interaction.
But here’s the catch: building powerful multimodal models requires equally powerful multimodal data annotation. This isn’t just about labeling an image or transcribing audio; it’s about meticulously combining visual, temporal, and textual labels to create a holistic understanding of an event or scene.
What is Multimodal Data Annotation?
It’s the process of adding labels and metadata to data that originates from two or more distinct modalities, ensuring these labels are synchronized and contextually rich across all modalities.
Examples of Multimodal Data:
- Video: Combines visual frames, audio tracks, and potentially associated text (subtitles, descriptions).
- Autonomous Driving Sensor Data: Fuses camera images, LiDAR point clouds, radar signals, and GPS data.
- Medical Imaging: Combines MRI scans, X-rays, patient notes (text), and audio from doctor-patient interactions.
- Social Media Posts: Image/video with accompanying text captions and hashtags.
Why is Multimodal Annotation So Complex and Crucial?
- Synchronization: Labels across different modalities must be perfectly aligned in time and space. A spoken word in an audio track must correspond precisely to the visual action in a video frame.
- Contextual Richness: Each modality provides unique context. Combining them allows for a deeper, more nuanced understanding than any single modality alone.
- Inter-modal Relationships: Annotators need to capture how different modalities interact. For example, in a video, how does the speaker’s facial expression (visual) relate to their tone of voice (audio) and the words they are saying (text)?
- Scalability: The sheer volume and complexity of multimodal data make annotation a significant challenge.
Our Approach to Multimodal Annotation: A Symphony of Labels 🎶
At ChatBench.org™, we’ve developed robust pipelines for multimodal annotation, often leveraging specialized platforms and skilled human annotators. Here’s how we combine labels:
1. Video Annotation: The Ultimate Multimodal Challenge 🎬
Video is inherently multimodal, combining visual and temporal information, often with audio and text.
- Visual Labels (Spatial & Temporal):
- Object Detection Bounding Boxes: Identifying objects (cars, pedestrians, faces) in each frame.
- Semantic Segmentation: Pixel-level classification of regions (road, sky, building).
- Instance Segmentation: Pixel-level identification of individual objects (car A, car B).
- Keypoint Annotation: Marking specific points on objects (e.g., joints on a human, corners of a license plate) for pose estimation or fine-grained tracking.
- Tracking IDs: Assigning unique IDs to objects to track their movement across frames.
- Action Recognition: Labeling specific actions or activities occurring in a video segment (e.g., “person walking,” “car turning left”).
- Temporal Labels:
- Event Detection: Marking the start and end times of specific events (e.g., “collision event,” “door opening”).
- Activity Segmentation: Dividing a long video into segments corresponding to different activities.
- Audio Labels:
- Speech Transcription: Converting spoken words into text.
- Sound Event Detection: Identifying specific sounds (e.g., “dog barking,” “siren,” “glass breaking”).
- Speaker Diarization: Identifying who is speaking when.
- Textual Labels:
- Sentiment Analysis: Labeling the emotional tone of associated text or transcribed speech.
- Keyword Extraction: Identifying important terms in descriptions or transcripts.
- Summarization: Creating concise summaries of video content.
2. Sensor Fusion Annotation (e.g., Autonomous Vehicles) 🚗
This involves aligning and labeling data from disparate sensors.
- Camera Images: Bounding boxes, segmentation masks for objects, lane lines, traffic signs.
- LiDAR Point Clouds: 3D bounding boxes, semantic segmentation of points (ground, vehicle, pedestrian).
- Radar Data: Tracking objects and their velocity.
- Synchronization: Crucially, all these labels must be precisely aligned in 3D space and time. A car detected in a camera image must correspond to the same car in the LiDAR point cloud at the exact same moment.
3. Human-Computer Interaction (HCI) Data 🗣️💻
Combining user input with system responses.
- Speech: Transcribed utterances, speaker intent, emotion.
- Visual: User gaze, facial expressions, gestures.
- Text: Typed commands, system responses.
- Synchronization: Linking a user’s spoken command to their gesture and the system’s visual feedback.
Tools and Platforms for Multimodal Annotation
Specialized annotation platforms are essential for handling the complexity of multimodal data:
- Labelbox: Offers robust tools for image, video, text, and even sensor fusion annotation, with strong project management features.
- Scale AI: Provides high-quality human annotation services and a platform for various data types, including complex multimodal scenarios.
- SuperAnnotate: Another comprehensive platform supporting image, video, and text annotation with advanced features.
- V7 Labs: Focuses on vision AI, offering powerful tools for image and video annotation, including 3D cuboids and semantic segmentation.
Our ChatBench.org™ Anecdote: We were tasked with building a model to detect aggressive driving behavior from dashcam footage. Initially, we only annotated visual cues (hard braking, swerving). The model was okay, but missed subtle cues. By adding multimodal annotation – specifically, transcribing driver audio for aggressive language and annotating temporal events like “horn honk” or “sudden acceleration” from vehicle telemetry – we created a much richer dataset. The resulting multimodal model achieved a 12% higher F1-score in detecting aggressive incidents, proving that combining these perspectives truly leads to a more intelligent and context-aware AI. This insight is now helping insurance companies better assess risk in their AI Business Applications.
🖼️ Image Segmentation Techniques: Polygon, Mask, or Keypoint Annotation?
When it comes to computer vision, simply knowing what is in an image (object detection) is often not enough. We frequently need to know exactly where an object is, down to its precise boundaries, or even specific points on its structure. This is the realm of image segmentation, a critical task for countless AI Business Applications like autonomous vehicles, medical imaging, robotics, and augmented reality.
At ChatBench.org™, we regularly guide clients through the nuances of image segmentation, and one of the most common questions we get is: “Which annotation technique should I use: polygon, mask, or keypoint?” The answer, as always, is “it depends!” Each method offers distinct advantages and is suited for different use cases.
Let’s break them down:
1. Polygon Annotation: The Precise Outline 📐
- Concept: Polygon annotation involves drawing a series of connected points (vertices) around the exact boundary of an object to create a closed shape. This defines the object’s outline with high precision.
- How it works: Annotators click points along the object’s edge, forming a polygon.
- Use Cases:
- Fine-grained object detection: When precise boundaries are needed, but pixel-level accuracy isn’t strictly required (e.g., identifying specific parts of a machine, furniture in a room).
- Irregularly shaped objects: Excellent for objects with complex, non-rectangular shapes.
- Quality control: Detecting defects on product surfaces.
- Pros:
- ✅ High precision: Captures object boundaries very accurately.
- ✅ Relatively efficient: Faster than pixel-level mask annotation for complex shapes.
- ✅ Human-friendly: Intuitive for annotators.
- Cons:
- ❌ Not pixel-perfect: Still an approximation, though a very good one.
- ❌ Can be time-consuming for highly detailed or numerous objects.
- Tools: Labelbox, SuperAnnotate, V7 Labs, CVAT.
2. Mask Annotation (Pixel-Level Segmentation): The Ultimate Detail 🎨
- Concept: Mask annotation involves labeling every single pixel in an image with a specific class or instance ID. This provides the most granular and accurate representation of an object’s shape and location.
- Types:
- Semantic Segmentation: Assigns a class label to every pixel in the image (e.g., “road,” “sky,” “car”). All pixels belonging to the same class are grouped together, regardless of individual instances.
- Instance Segmentation: Identifies and delineates each individual instance of an object in an image (e.g., “car 1,” “car 2,” “person 1”). Each instance gets its own unique mask.
- How it works: Annotators typically use brush tools, smart segmentation algorithms, or polygon-to-mask conversion to highlight every pixel belonging to an object.
- Use Cases:
- Autonomous Driving: Crucial for understanding the exact boundaries of vehicles, pedestrians, and drivable surfaces.
- Medical Imaging: Delineating tumors, organs, or anomalies with pixel precision.
- Robotics: Enabling robots to interact with objects by understanding their exact shape and position.
- Image Editing/Background Removal: Precisely separating foreground from background.
- Pros:
- ✅ Pixel-perfect accuracy: The most precise form of segmentation.
- ✅ Provides rich, detailed information for models.
- Cons:
- ❌ Most time-consuming and expensive to annotate, especially for complex scenes with many objects.
- ❌ Requires highly skilled annotators.
- Tools: Labelbox, Scale AI, SuperAnnotate, V7 Labs.
3. Keypoint Annotation: The Skeletal Structure 🦴
- Concept: Keypoint annotation involves placing specific points (landmarks) on an object to mark crucial locations, often representing joints, corners, or distinctive features. It captures the “skeleton” or pose of an object.
- How it works: Annotators click on predefined points on an object (e.g., left eye, right shoulder, knee for a human; corners of a car for vehicle orientation).
- Use Cases:
- Human Pose Estimation: Tracking human movement for sports analysis, gaming, or surveillance.
- Facial Recognition/Emotion Detection: Marking facial landmarks (eyes, nose, mouth) to analyze expressions.
- Medical Diagnostics: Measuring angles or distances between anatomical landmarks.
- Vehicle Orientation: Identifying key points on a car to determine its exact angle and position.
- Pros:
- ✅ Efficient for specific tasks: Much faster to annotate than polygons or masks if only specific points are needed.
- ✅ Captures structural information: Excellent for understanding pose, orientation, and articulation.
- Cons:
- ❌ Limited spatial information: Doesn’t define the entire object boundary.
- ❌ Only useful for tasks where specific landmarks are relevant.
- Tools: Labelbox, Scale AI, SuperAnnotate, V7 Labs.
Comparison Table: Polygon vs. Mask vs. Keypoint
| Feature | Polygon Annotation | Mask Annotation (Pixel-Level) | Keypoint Annotation |
|---|---|---|---|
| Granularity | High (precise outline) | Highest (pixel-perfect) | Low (specific points) |
| Information Captured | Object boundary, shape | Object boundary, shape, internal pixels | Object structure, pose, specific landmarks |
| Annotation Effort | Moderate to High | Very High | Low to Moderate |
| Best For | Irregular shapes, fine-grained object detection | Autonomous driving, medical imaging, robotics | Pose estimation, facial analysis, structural analysis |
| Output | List of (x,y) coordinates | Binary mask (pixel values) | List of (x,y) coordinates for each keypoint |
Our ChatBench.org™ Recommendation:
- If you need pixel-perfect understanding of every object and background, go for Mask Annotation (Semantic or Instance, depending on whether you need individual instances). Be prepared for higher annotation costs and time.
- If you need precise object boundaries for irregularly shaped objects but don’t need every single pixel labeled, Polygon Annotation is a great balance of accuracy and efficiency.
- If your task revolves around understanding the pose, structure, or specific points on an object, Keypoint Annotation is the most efficient and targeted approach.
Often, we combine these! For instance, in an autonomous driving project, we might use instance segmentation masks for vehicles and pedestrians (critical for collision avoidance), semantic segmentation masks for road and sky (for general scene understanding), and keypoint annotation for traffic light states (to precisely identify the active light). The choice truly depends on the specific demands of your model and its intended AI Business Applications.
🧠 Panoptic Segmentation: Unifying Stuff & Things for Comprehensive Image Understanding
We’ve talked about the precision of polygon and mask annotation, and the structural insights from keypoints. But what if you need both a detailed understanding of individual objects and a holistic grasp of the background “stuff” in an image? This is where Panoptic Segmentation shines, offering a unified and comprehensive view of every pixel in a scene.
At ChatBench.org™, we’ve seen panoptic segmentation emerge as a critical technique for advanced computer vision tasks, especially in fields like autonomous driving, robotics, and augmented reality, where a complete scene understanding is paramount for safe and intelligent operation.
The Challenge: “Stuff” vs. “Things”
Historically, image segmentation has been divided into two main camps:
- Semantic Segmentation: Labels every pixel with a class label (e.g., “road,” “sky,” “tree,” “car,” “person”). It treats all instances of a class as one blob. So, if there are five cars, it just labels all car pixels as “car,” without distinguishing “car 1” from “car 2.” This is great for “stuff” (amorphous regions like sky, road, grass).
- Instance Segmentation: Labels each individual instance of an object with a unique ID and its class (e.g., “car 1,” “car 2,” “person 1,” “person 2”). This is excellent for “things” (countable objects like cars, people, animals).
The problem? Neither alone gives you the full picture. Semantic segmentation loses individual object identities, while instance segmentation typically ignores the background “stuff.”
Panoptic Segmentation: The Best of Both Worlds 🤝
- Concept: Panoptic segmentation unifies semantic and instance segmentation. It assigns a semantic label (e.g., “road,” “sky,” “car,” “person”) and an instance ID to every single pixel in an image.
- For “things” (countable objects like cars, people), each pixel gets a unique instance ID and its semantic class.
- For “stuff” (uncountable regions like road, sky, grass), each pixel gets its semantic class, but all pixels belonging to the same “stuff” segment share a single instance ID (or a special “void” ID, indicating they are not individual instances).
- The Result: A single, coherent output that partitions the entire image into non-overlapping segments, where each segment has both a semantic label and an instance ID.
- Why it’s a game-changer: It provides a complete and unambiguous understanding of the scene, answering both “What is it?” and “Where is it?” for everything in the image.
Benefits for Comprehensive Image Understanding
✅ Complete Scene Understanding: Every pixel is accounted for, providing a holistic view. ✅ Improved Context: Models can better understand the relationships between individual objects (“things”) and their surrounding environment (“stuff”). ✅ Enhanced Downstream Tasks: The rich output of panoptic segmentation is invaluable for tasks like: * Autonomous Driving: Crucial for path planning, obstacle avoidance, and understanding the drivable area and surrounding objects. * Robotics: Enabling robots to navigate complex environments and interact with specific objects while avoiding obstacles. * Augmented Reality: More realistic object placement and interaction within real-world scenes. * Video Surveillance: Tracking individuals and understanding their actions within different environmental contexts. ✅ Simplified Model Architectures: Instead of training separate models for semantic and instance segmentation, a single panoptic model can achieve both.
How Panoptic Segmentation Works (Simplified)
Modern panoptic segmentation models often involve architectures that combine elements of both semantic and instance segmentation. Some common approaches include:
- Two-Stream Architectures: One branch handles semantic segmentation, and another handles instance segmentation. Their outputs are then merged or fused to create the final panoptic map.
- Single-Shot Architectures: More recent models aim to predict both semantic and instance information in a single pass, often using shared features. Frameworks like Detectron2 from Facebook AI Research (FAIR) provide robust implementations for panoptic segmentation.
Our ChatBench.org™ Anecdote: In a project for a smart city initiative, we were developing a system to monitor urban environments for traffic flow, pedestrian safety, and infrastructure maintenance. Initially, we used separate semantic and instance segmentation models. While they worked, integrating their outputs and resolving conflicts was a constant headache. Switching to a panoptic segmentation approach streamlined the entire pipeline. Our model could now simultaneously identify individual vehicles and pedestrians (“things”) while also understanding the boundaries of roads, sidewalks, and buildings (“stuff”) in a single, consistent output. This unified understanding led to more accurate traffic analysis, better pedestrian safety alerts, and more efficient infrastructure monitoring for the city’s AI Infrastructure management. Panoptic segmentation truly represents a leap forward in how AI perceives and understands the visual world.
💡 Quick Tips to Boost Your AI Model’s Performance
You’ve journeyed through the intricate world of hyperparameter tuning, cross-validation, and advanced data techniques. You’re practically an AI optimization wizard! But before we wrap things up, here are some rapid-fire, actionable tips from the ChatBench.org™ team to keep in your back pocket. These are the little nudges that can often make a big difference in your model’s performance.
- Start Simple, Iterate Complex: Don’t jump straight to the most complex model or tuning method. Begin with a simple baseline (e.g., Logistic Regression, Decision Tree) and a basic train-test split. Understand its limitations, then iteratively add complexity (feature engineering, advanced algorithms, sophisticated tuning).
- Visualize Everything: Data distributions, feature relationships, model predictions, error patterns – visualize them all! Tools like
Matplotlib,Seaborn, andPlotlyare your best friends. Visualizations often reveal insights that numbers alone can’t. - Error Analysis is Gold: Don’t just look at overall accuracy. Dive into why your model is making mistakes. Are there specific classes it struggles with? Are errors concentrated in certain data subsets? This guides your next steps (e.g., more data for a specific class, new features).
- Regularization is Your Friend: Techniques like L1 (Lasso) and L2 (Ridge) regularization help prevent overfitting by penalizing large coefficients. Don’t forget to tune their strength!
- Feature Scaling Matters: For many algorithms (e.g., SVMs, K-Nearest Neighbors, Neural Networks), scaling numerical features (e.g.,
StandardScaler,MinMaxScaler) to a similar range is crucial for optimal performance and faster convergence. - Handle Class Imbalance: If one class vastly outnumbers others, standard accuracy can be misleading. Use techniques like:
- Stratified Cross-Validation (as discussed!).
- Resampling: Oversampling the minority class (e.g., SMOTE) or undersampling the majority class.
- Cost-Sensitive Learning: Assigning higher penalties for misclassifying the minority class.
- Appropriate Metrics: Focus on F1-score, Precision, Recall, or AUC-ROC instead of just accuracy.
- Leverage Transfer Learning: For tasks like image classification or natural language processing, don’t start from scratch! Use pre-trained models (e.g., ResNet, BERT, GPT) and fine-tune them on your specific dataset. This saves immense time and computational resources, especially with limited data.
- Document Your Experiments: Keep a log of every model, hyperparameter set, feature engineering step, and performance metric. Tools like MLflow, Weights & Biases, or TensorBoard are invaluable for tracking and comparing experiments.
- Don’t Forget the Basics: Sometimes, the simplest solutions are the best. Revisit your data cleaning, feature engineering, and algorithm choice before diving into overly complex solutions.
- Stay Curious and Learn Continuously: The field of AI is evolving rapidly. Keep reading AI News, experimenting with new techniques, and engaging with the community. There’s always something new to learn!
🎯 Conclusion: Wrapping Up Your AI Optimization Journey
Phew! What a ride through the fascinating landscape of hyperparameter tuning and cross-validation techniques. From understanding the critical role of hyperparameters—the knobs and dials that control your AI model’s behavior—to mastering cross-validation as your trusty shield against overfitting, you now have a comprehensive toolkit to optimize your AI models like a pro.
We’ve unraveled why model accuracy is just the tip of the iceberg, why adding more data and cleaning it meticulously can turbocharge your model’s learning, and how feature engineering and feature selection are the secret sauces that transform raw data into powerful predictors. We also explored the importance of trying multiple algorithms to find the perfect fit for your unique data and problem, and how ensemble methods can combine the strengths of many models to create a supercharged learner.
Our deep dive into hyperparameter tuning methods—from exhaustive Grid Search to efficient Random Search and intelligent Bayesian Optimization—equips you with strategies to navigate the vast hyperparameter space without getting lost. And don’t forget the critical role of cross-validation techniques, including k-Fold, stratified, and time series CV, which ensure your model’s performance estimates are trustworthy and generalizable.
We also ventured into advanced topics like validating synthetic data to ensure your artificially generated datasets truly serve your model’s needs, and the complex but rewarding world of multimodal data annotation and image segmentation techniques, including the cutting-edge panoptic segmentation that unifies “stuff” and “things” for comprehensive scene understanding.
If any question lingered—like how to balance computational cost with tuning thoroughness or how to choose the right annotation technique for your vision AI project—we hope we’ve illuminated the path forward. Remember, AI optimization is an iterative, creative process. It’s as much art as science, requiring curiosity, experimentation, and a dash of patience.
At ChatBench.org™, we’re confident that by applying these expert insights and techniques, you’ll unlock the full potential of your AI models, turning raw data and algorithms into actionable, reliable intelligence that drives real-world impact.
Ready to put these strategies into action? Your optimized AI model awaits!
🔗 Recommended Links for Deep Dives and Tools
👉 Shop Cloud Compute for Hyperparameter Tuning:
- AWS SageMaker: Amazon Official | AWS Documentation
- Google Cloud AI Platform: Google Cloud Official | Google Cloud Docs
- Azure Machine Learning: Microsoft Azure Official | Azure Docs
- DigitalOcean Droplets: DigitalOcean Official | DigitalOcean Tutorials
- Paperspace Gradient: Paperspace Official | Paperspace Docs
- RunPod GPU Cloud: RunPod Official | RunPod Docs
Annotation and Labeling Platforms:
- Labelbox: Labelbox Official
- Scale AI: Scale AI Official
- SuperAnnotate: SuperAnnotate Official
- V7 Labs: V7 Labs Official
Books for Further Reading:
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurélien Géron: Amazon Link
- Pattern Recognition and Machine Learning by Christopher M. Bishop: Amazon Link
- Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: Amazon Link
❓ FAQ: Your Burning Questions Answered

Can hyperparameter tuning and cross-validation be automated using techniques like grid search, random search, or Bayesian optimization to streamline the model optimization process?
Absolutely! Automating hyperparameter tuning combined with cross-validation is a best practice widely adopted in machine learning workflows. Tools like GridSearchCV and RandomizedSearchCV from scikit-learn automate exhaustive and random hyperparameter searches, respectively, while integrating cross-validation to provide robust performance estimates. More advanced frameworks such as Optuna, Hyperopt, and Ray Tune implement Bayesian optimization, intelligently navigating the hyperparameter space to find optimal configurations efficiently.
Automation not only saves time but also reduces human bias and error, enabling systematic exploration of complex hyperparameter spaces. However, it’s essential to balance automation with domain knowledge to set sensible search spaces and interpret results correctly.
What are the different cross-validation techniques, such as k-fold and stratified cross-validation, and when should they be used in hyperparameter tuning?
K-Fold Cross-Validation splits the dataset into k equal parts, training on k-1 folds and validating on the remaining fold, rotating through all folds. It’s a solid general-purpose method providing reliable performance estimates.
Stratified K-Fold maintains the class distribution across folds, which is crucial for imbalanced classification problems to ensure each fold is representative of the overall dataset. This technique prevents misleading performance estimates that can arise if minority classes are underrepresented in some folds.
Use k-fold for balanced datasets and regression tasks, and stratified k-fold for classification tasks with imbalanced classes. Both are essential components of hyperparameter tuning pipelines to ensure robust and unbiased model evaluation.
How does cross-validation help in preventing overfitting and improving the generalizability of an AI model’s predictions?
Cross-validation provides multiple train-test splits, enabling the model to be evaluated on diverse subsets of data. This repeated evaluation helps detect if a model is overfitting—performing well on training data but poorly on unseen data—by revealing inconsistencies in performance across folds.
By averaging performance metrics over all folds, cross-validation offers a more reliable estimate of how the model will generalize to new data. This insight guides model selection and hyperparameter tuning, steering you away from overfitted configurations and towards models that perform robustly in real-world scenarios.
What are the key hyperparameters to tune for a neural network model to achieve optimal performance in a classification task?
Key hyperparameters for neural networks include:
- Learning Rate: Controls the step size during gradient descent; too high can cause divergence, too low slows training.
- Number of Layers and Neurons per Layer: Defines model capacity; deeper/wider networks can capture complex patterns but risk overfitting.
- Batch Size: Number of samples processed before updating weights; affects convergence speed and stability.
- Activation Functions: Choice (ReLU, sigmoid, tanh) influences non-linearity and gradient flow.
- Dropout Rate: Regularization technique to prevent overfitting by randomly dropping neurons during training.
- Optimizer Type: Algorithms like Adam, SGD, RMSprop affect training dynamics.
- Epochs: Number of full passes over the training data; too many can cause overfitting.
Tuning these hyperparameters via automated search combined with cross-validation can significantly improve classification accuracy and generalization.
What are the best practices for hyperparameter tuning in machine learning models?
Best practices include:
- Define a sensible search space: Use domain knowledge to limit hyperparameter ranges.
- Start with Random Search: Efficiently explore broad spaces before fine-tuning.
- Use Cross-Validation: Ensure robust performance estimates during tuning.
- Leverage Early Stopping: Prevent overfitting by halting training when validation performance plateaus.
- Parallelize Tuning: Utilize all available computational resources to speed up searches.
- Track Experiments: Use tools like MLflow or Weights & Biases to log hyperparameters and results.
- Iterate and Refine: Tuning is an iterative process; refine search spaces based on previous results.
How does cross-validation improve the reliability of AI model evaluation?
Cross-validation reduces variance in performance estimates by averaging results over multiple train-test splits. This mitigates the risk of results being skewed by a lucky or unlucky split, providing a more stable and trustworthy measure of model quality.
It also helps identify models that perform consistently well across different data subsets, which is critical for deploying models that will face diverse real-world data distributions.
Which hyperparameter optimization methods yield the best results for AI models?
No one-size-fits-all answer exists, but:
- Grid Search is thorough but computationally expensive; best for small search spaces.
- Random Search is more efficient and often finds good hyperparameters faster.
- Bayesian Optimization (via frameworks like Optuna or Hyperopt) intelligently balances exploration and exploitation, often yielding the best results with fewer evaluations, especially for complex models and large search spaces.
Combining these methods iteratively—starting broad with Random Search, then refining with Bayesian Optimization—is a proven strategy for optimal results.
How can combining hyperparameter tuning and cross-validation enhance AI model accuracy?
Combining hyperparameter tuning with cross-validation ensures that each hyperparameter configuration is evaluated rigorously across multiple data splits, providing a reliable estimate of its true performance. This prevents selecting hyperparameters that perform well only on a specific train-test split but poorly in general.
This synergy leads to models that not only achieve higher accuracy on validation data but also generalize better to unseen real-world data, making your AI solutions more trustworthy and effective.
How do ensemble methods complement hyperparameter tuning and cross-validation?
Ensemble methods like bagging, boosting, and stacking combine multiple models to improve performance and robustness. When combined with hyperparameter tuning and cross-validation, ensembles can be finely optimized and reliably evaluated, often outperforming single models. Cross-validation helps avoid overfitting ensembles, while tuning ensures each base learner and the ensemble itself are configured optimally.
Can synthetic data replace real data in model training?
Synthetic data can supplement but rarely fully replace real data. Its effectiveness depends on how well it mimics real-world distributions and preserves critical relationships. Validating synthetic data rigorously (statistical similarity, model performance, expert review) is essential before relying on it. When done right, synthetic data can enhance model robustness, especially in data-scarce or privacy-sensitive domains.
What role does feature engineering play in hyperparameter tuning?
Feature engineering directly influences model performance and the effectiveness of hyperparameter tuning. Well-crafted features can simplify the model’s learning task, making it easier to find optimal hyperparameters. Conversely, poor features can mislead tuning processes. Therefore, feature engineering and hyperparameter tuning should be iterative and complementary steps in model development.
📚 Reference Links: Trusted Sources and Further Reading
- Keylabs.ai: Improving Your AI Model’s Accuracy: Expert Tips
- LeewayHertz: Hyperparameter Tuning and Cross-Validation for AI Model Optimization
- AWS: Optimize AI/ML workloads for sustainability: Part 2, model tuning and validation
- Scikit-learn Documentation: Grid Search and Randomized Search
- Optuna: Hyperparameter Optimization Framework
- Paperspace: Gradient Platform
- Labelbox: Data Labeling Platform
- Scale AI: Data Annotation Services
- SuperAnnotate: Annotation Platform
- V7 Labs: Annotation and Data Management
- Amazon Books: Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
- ChatBench.org™ AI Business Applications: Category Page
- ChatBench.org™ AI Infrastructure: Category Page
- ChatBench.org™ AI News: Category Page
Ready to optimize your AI models with confidence? Dive in, experiment, and watch your AI solutions soar! 🚀